- 博客访问: 1582002
- 博文数量: 43
- 博客积分: 169
- 博客等级: 入伍新兵
- 技术积分: 1162
- 用 户 组: 普通用户
- 注册时间: 2012-04-08 15:35
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
分类: java
2019-08-05 16:25:28
jedis第一讲-凯发app官方网站
jedis是开源的面向java的redis数据库客户端工具包之一,目前github版本是3.1.0 ()。对于spring boot项目来说,starter-data-redis:1.5.12.release 版本所依赖的redis client包是2.9.0版本。从maven的依赖引用上看,官方引用最多的也是此版本。所以本文在源码讲解上也是依据2.9.0版本进行说明的。
众所周知,所有项目对于redis数据库的依赖无非出于以下两种原因:一方面,依赖其内存数据库特性,将redis作为分布式缓存使用,同时以降低对关系型数据库的ops操作;另一方面,依赖其单线程执行的特性,以实现分布式锁的功能。大多数业务场景,我们还是将redis作为了文本型的缓存服务器在使用,以提高请求的相应效率,降低平响时间,增加服务的吞吐。但是,今天我们聊一下在集群环境下,集群整体不可用时,产生的redis超时过长,最终拖慢请求的场景。
5主5从 redis集群
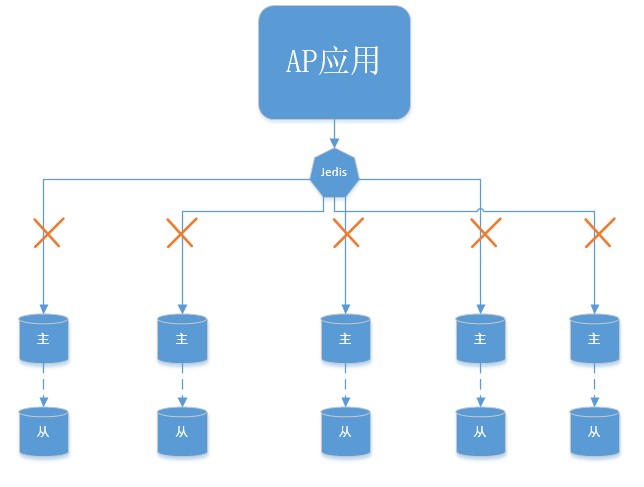
redis集群不可用
正常情况下,如果集群中某一台机器挂掉,redis集群会执行故障偏移策略,将其对应的从节点升级为主节点,超时时间将为一个timeout,。然而,当整个集群与应用服务之间出现了网络断链时,超时时间=timeout * 集群节点数(主从)。这是为什么呢?是因为在集群模式下,如果某个节点挂掉,集群会执行故障偏移,偏移过程中涉及到新的主节点选举以及新的从节点加入。jedis为了能够获取到新的集群信息,会从原始的集群信息列表中某一个节点开始遍历,如果能够连接该节点,就从该节点获取整个集群的配置信息和slot分布。如果当前节点已经断连,jedis会获取另外一个节点信息获取集群配置,直到遍历到最后一个节点为止。所以在整个过程中如果整个集群断连,那么一次请求timeout时间 >= timeout * 节点数。
jedis client(2.9.0)版本关于上述业务处理的代码主要在jedisclustercommand类的runwithretries方法中。
该方法有四个参数:
key : 要进行操作的key
attempts : 请求重试次数
trytrandomnode : 是否尝试随机选择一个节点进行
asking : 是否处理asking 链接(可以了解一下asking 和moved 区别)
具体方法体如下: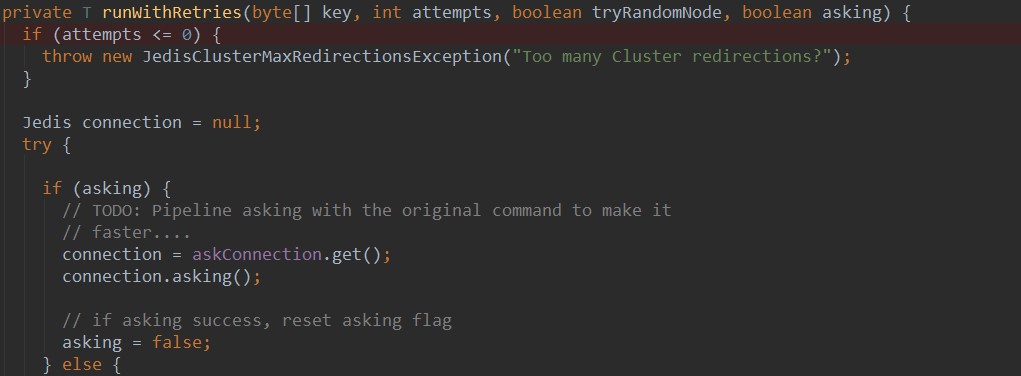
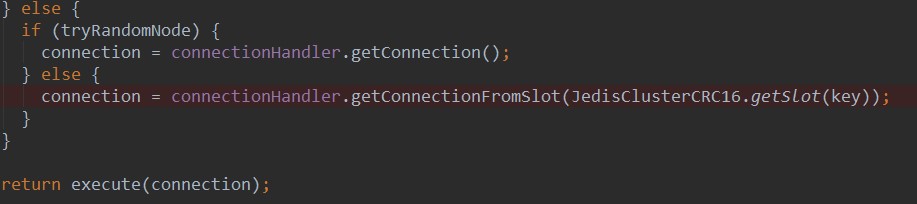
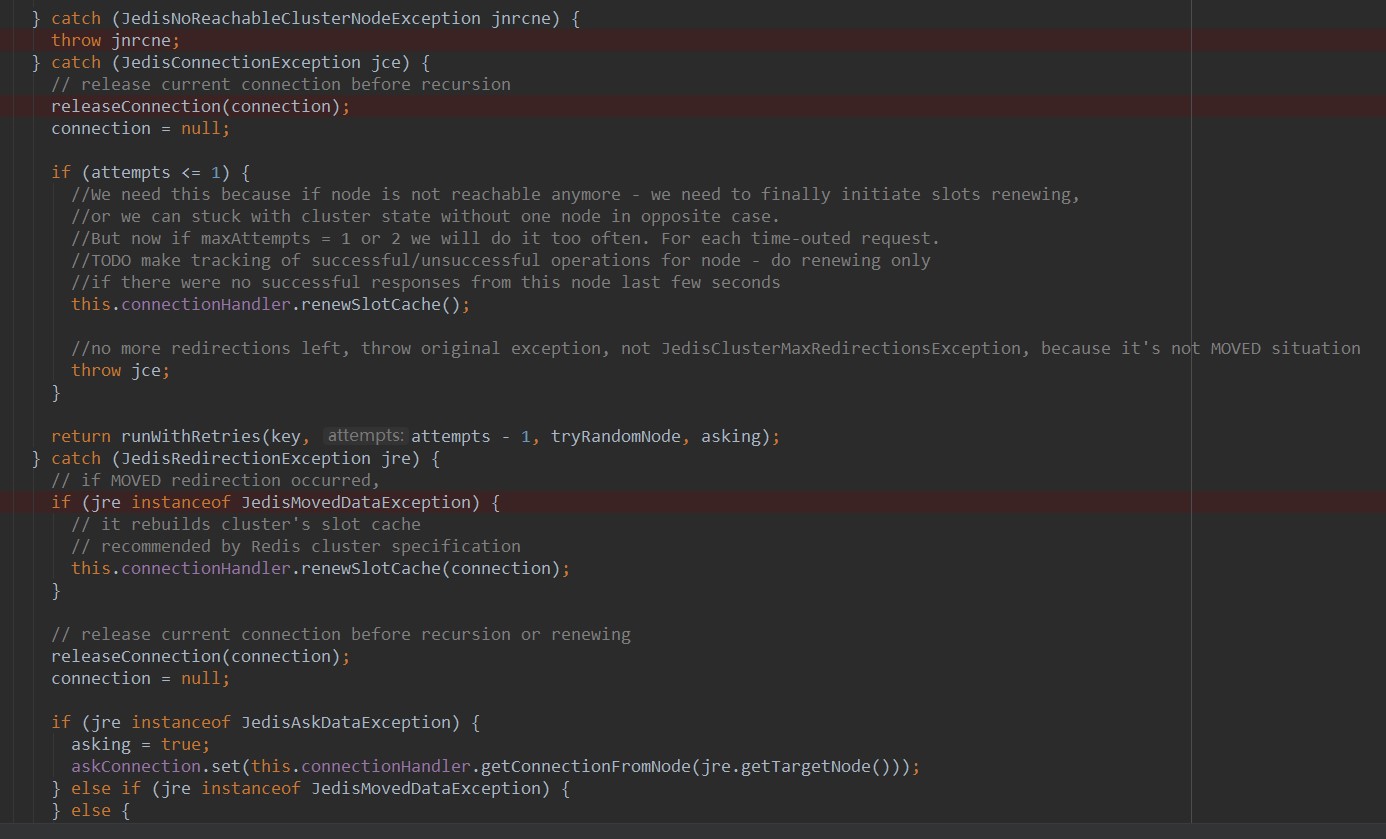
如果在获取链接时或者执行execute操作时出现异常,则执行异常处理机制,此处的异常处理分为:
1、jedisnoreachableclusternodeexception 说明jedis在初始化时没有获取到任何集群信息,即在服务启动时集群就是不可用的,所以这种状态下,必须检查redis集群的可用性,并重启应用服务。
2、jedisconnectionexception 说明jedis在获取链接时出现异常,主要原因是因为jedis在获取连接时默认会ping一下连接以保证目标节点是可用的,如果ping过程失败,则抛出该异常。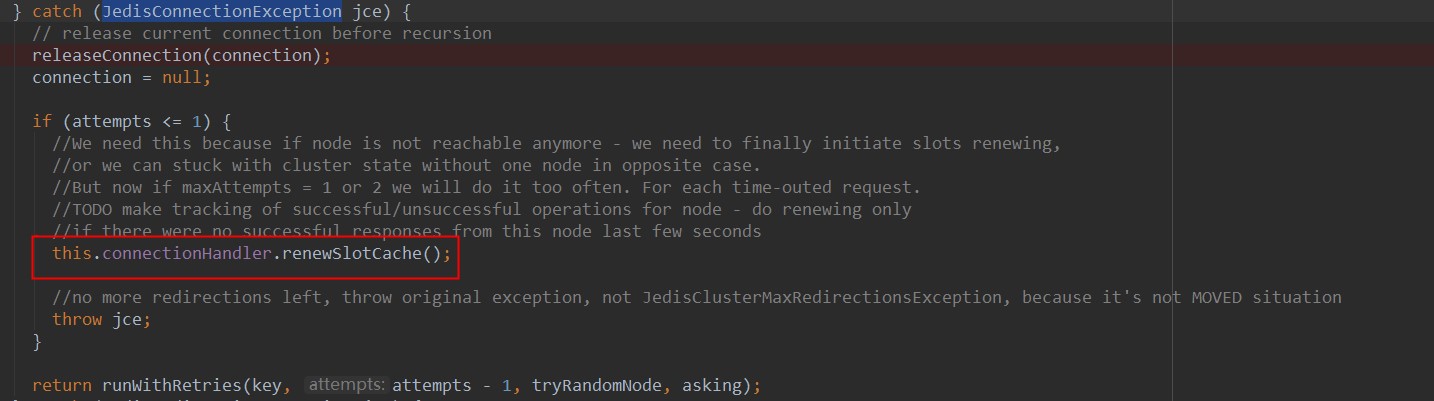
1、释放connection链接
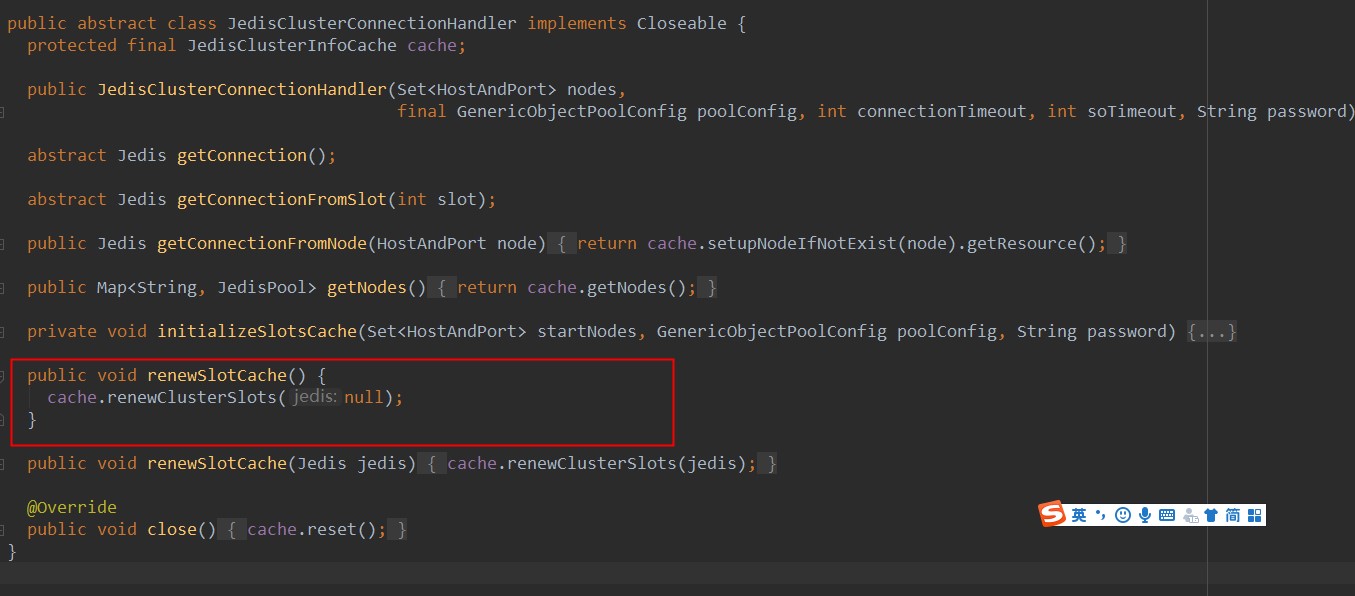
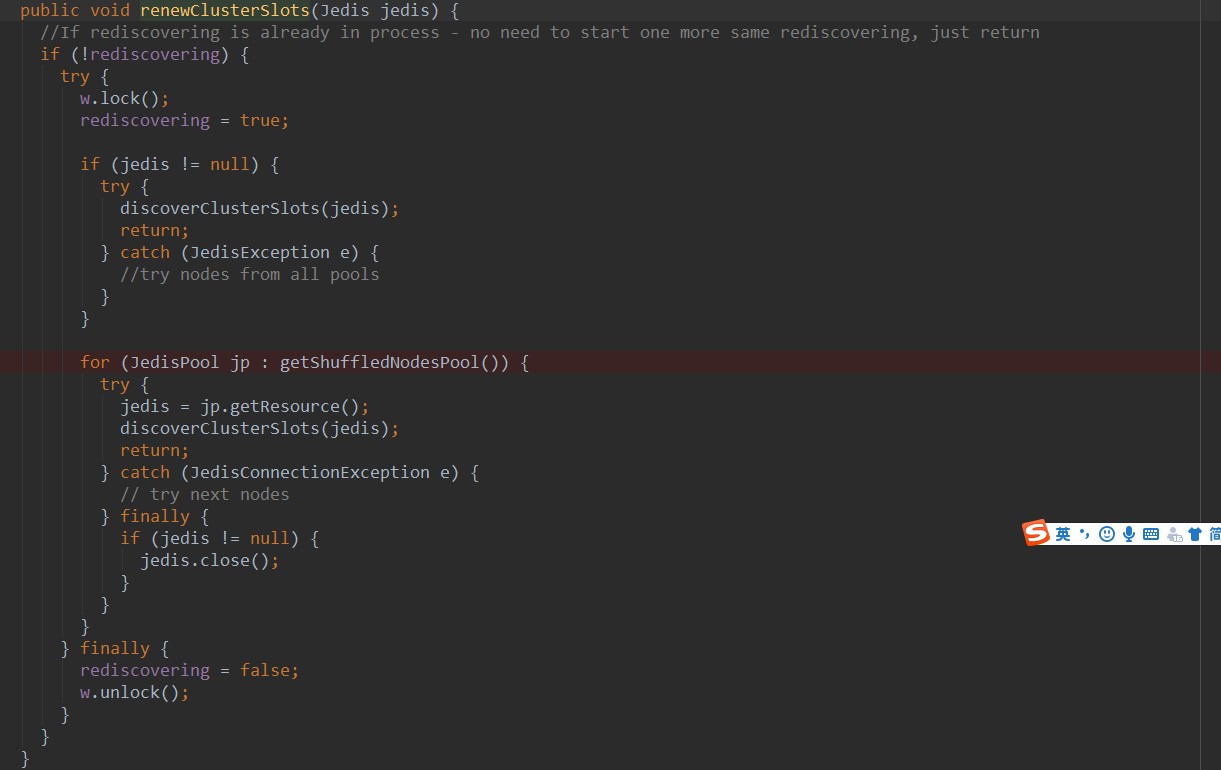
2、判断设置的重试次数是否<=1,如果为false,则调用runwithretries方法递归调用进行重试访问,如果为true,则会调用connectionhandler对象的renewslotcache()方法:
3、jedisredirectionexception 该异常主要原因有两个。一种是由于moved操作导致的(slot不在被访问节点,在另外一个节点时,当前节点返回moved错误,并附带上目标节点ip 端口),另外一种是asking导致的(在节点进行迁移过程中,如果被访问的slot属于正在迁移节点,并且此时,访问的key不在当前节点,会返回asking错误,让client访问目标节点获取数据)。这两种情况虽然结果一直,即都需要跳转到另外一个节点获取最终结果,但是原因是截然不同的。如果客户端使用jedis时,并且在集群环境下,一般不会出现moved错误,因为jedis在client端 就已经通过crc16(key)计算好了slot以及slot具体分布在哪个节点上,所以一般不会出现moved问题。当然只有一种情况就是当被访问的key所在主节点挂掉时,集群进行故障偏移,jedis需要通过其他节点重新获取最新集群信息时,有可能会出现moved问题。再有2就是通过命令行链接集群时,redis-cli -c ip:port 时,如果访问的key不在该节点上时,server会返回 moved错误。