- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
分类: 数据库开发技术
2022-09-27 10:09:39
1 导读
数据的一致性是数据准确的重要指标,那如何实现数据的一致性呢?本文从事务特性和事务级别的角度和大家一起学习如何实现数据的读写一致性。
2 一致性
1.数据的一致性:通常指关联数据之间的逻辑关系是否正确和完整。
举个例子:某系统实现读写分离,读数据库是写数据库的备份库,小李在系统中之前录入的学历信息是高中,经过小李努力学习,成功获得了本科学位。小李及时把信息变成成了本科,可是由于今天系统备份时间较长,小李变更信息时,数据已经开始备份。公司的hr通过系统查询小李信息时,发现还是本科,小李的申请被驳回。这就是数据不一致问题。
2.数据库的一致性:是指数据库从一个一致性状态变到另一个一致性状态。这是事务的一致性的定义。
举个例子:仓库中商品a有100件,门店中商品a有10件。上午10点,仓库发送商品a50件到门店,{banned}最佳后仓库中有商品a50件,门店有商品a60件,这样商品的总是是不变的。不能门店收到货后,仓库的商品a还是100件,这样就出现数据库不一致问题。仓库和门店商品a的总数是110才是正确的,这就是数据库的一致性。
3 数据库事务
数据库事务( transaction)是访问并可能操作各种数据项的一个数据库操作序列,这些操作要么全部执行,要么全部不执行,是一个不可分割的工作单位。事务由事务开始与事务结束之间执行的全部数据库操作组成。
事务的性质:
- 原子性(atomicity):事务中的全部操作在数据库中是不可分割的,要么全部完成,要么全部不执行。
- 一致性(consistency):几个并行执行的事务,其执行结果必须与按某一顺序 串行执行的结果相一致。
- 隔离性(isolation):事务的执行不受其他事务的干扰,事务执行的中间结果对其他事务必须是透明的。
- 持久性(durability):对于任意已提交事务,系统必须保证该事务对数据库的改变不被丢失,即使数据库出现故障
4 并发问题
数据库在并发环境下会出现脏读、重复读和幻读问题。
1.脏读
事务a读取了事务b未提交的数据,如果事务b回滚了,事务a读取的数据就是脏的。
举例:订单a需要商品a20件,订单b需要商品a10件。仓库中有商品a库存是20件。订单b先查询,发现库存够,进行扣减。在扣减的过程中,订单a进行查询,发现库存只有10个不够订单数量,抛出异常。这时候订单b提交失败了。库存数量又变成20了。这时候,仓库人员去查库存,发现数量是20,可是订单a却说库存不足,这就让人很奇怪。
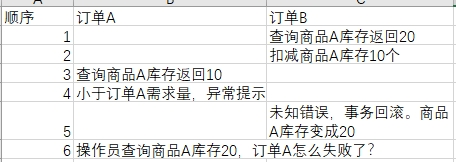
复读指的是在一个事务内,{banned}最佳开始读到的数据和事务结束前的任意时刻读到的同一批数据出现不一致的情况。
举例:库房管理员查询商品a的数量,读取结果是20件。这是订单a出库,扣减了商品10件。这时管理员再去查商品a时,发现商品a的数量时10件和{banned}中国第一此查询的结果不同了。

事务a在执行读取操作,需要两次统计数据的总量,前一次查询数据总量后,此时事务b执行了新增数据的操作并提交后,这个时候事务a读取的数据总量和之前统计的不一样,就像产生了幻觉一样,平白无故的多了几条数据,成为幻读。
举例:操作员查询可生产单量10个,调用接口下发10个订单,事务a增加10个订单。操作员获取10个订单落库,查询 发现变成30个订单。
5 事务隔离级别
read uncommitted(未提交读)
一个事务可以读取到其他事务未提交的数据,会出现脏读,所以叫做 ru,它没有解决任何的问题。
read committed(已提交读)
一个事务只能读取到其他事务已提交的数据,不能读取到其他事务未提交的数据,它解决了脏读的问题,但是会出现不可重复读的问题。
repeatable read(可重复读)
它解决了不可重复读的问题,也就是在同一个事务里面多次读取同样的数据结果是一样的,但是在这个级别下,没有定义解决幻读的问题。
serializable(串行化)
在这个隔离级别里面,所有的事务都是串行执行的,也就是对数据的操作需要排队,已经不存在事务的并发操作了,所以它解决了所有的问题。
6 解决数据读一致性
有两个方案可以解决读一致性问题:基于锁的并发操作(lbcc)和基于多版本的并发操作(mvcc)
6.1 lbcc
既然要保证前后两次读取数据一致,那么读取数据的时候,锁定我要操作的数据,不允许其他的事务修改就行了。这种方案叫做基于锁的并发控制 lock based concurrency control(lbcc)。
lbcc是通过悲观锁来实现并发控制的。
如果事务a对数据进行加锁,在锁释放前,其他事务就不能对数据进行读写操作。这样并发调用,改成了顺序调用。对目前的大多数系统来说,性能完全不能满足要求。
6.2 mvcc
要让一个事务前后两次读取的数据保持一致,那么我们可以在修改数据的时候给它建立一个备份或者叫快照,后面再来读取这个快照就行了。不管事务执行多长时间,事务内部看到的数据是不受其它事务影响的,根据事务开始的时间不同,每个事务对同一张表,同一时刻看到的数据可能是不一样的。这种方案我们叫做多版本的并发控制 multi version concurrency control(mvcc)。
mvcc是基于乐观锁的。
在 innodb 中,mvcc 是通过undo log中的版本链和read-view一致性视图来实现的。
6.2.1 undo logundo log是innodb引擎的一种日志,在事务的修改记录之前,会把该记录的原值先保存起来再做修改,以便修改过程中出错能够恢复原值或者其他的事务读取。undo log是一种用于撤销回退的日志,在事务没提交之前,mysql会先记录更新前的数据到 undo log日志文件里面,当事务回滚时或者数据库崩溃时,可以利用 undo log来进行回退。
对数据变更的操作不同,undo log记录的内容也不同:
- 新增一条记录的时候,在创建对应undo日志时,只需要把这条记录的主键值记录下来,如果要回滚插入操作,只需要根据对应的主键值对记录进行删除操作。
- 删除一条记录的时候,在创建对应undo日志时,需要把这条数据的所有内容都记录下来,如果要回滚删除语句,需要把记录的数据内容生产相应的insert语句,并插入到数据库中。
- 更新一条记录的时候,如果没有更新主键,在创建对应undo日志时,如果要回滚更新语句,需要把变更前的内容记录下来,如果要回滚更新语句,需要根据主键,把记录的数据更新回去。
- 更新一条记录的时候,如果有更新主键,在创建对应undo日志时,需要把数据的所有内容都记录下来,如果要回滚更新语句,先把变更后的数据删掉,再执行插入语句,把备份的数据插入到数据库中。
undo log版本链
每条数据有两个隐藏字段,trx_id 和 roll_pointer,trx_id表示{banned}最佳近一次事务的id,roll_pointer表示指向你更新这个事务之前生成的undo log。
事务id:mysql维护一个全局变量,当需要为某个事务分配事务id时,将该变量的值作为事务id分配给事务,然后将变量自增1。
举例:
- 事务a id是1 插入一条数据x,这条数据的trx_id =1 ,roll_pointer 是空({banned}中国第一次插入)。
- 事务b id 是2 对这条数据进行了更新,这条数据的 trx_id =2 ,roll_pointer 指向 事务a的undo log.
- 事务c id 是3 又对数据进行了更新操作,这条数据的trx_id =3,roll_pointer 指向 事务b的undo log.
所以当多个事务串行执行的时候,每个事务修改了一行数据,都会更新隐藏字段trx_id 和 roll_pointer,同时多个事务的undo log会通过roll_pointer指针串联起来,形成undo log版本链。
6.2.2 read-view一致性视图innodb为每个事务维护了一个数组,这个数组用来保存这个事务启动的瞬间,当前活跃的事务id。这个数组里有两个水位值: 低水位(事务id {banned}最佳小值)和 高水位(事务id {banned}最佳大值 1);这两个水位值就构成了当前事务的一致性视图(read-view)
readview中主要包含4个比较重要的内容:
- m_ids:表示在生成readview时当前系统中活跃的读写事务的事务id列表。
- min_trx_id:表示在生成readview时当前系统中活跃的读写事务中{banned}最佳小的事务id,也就是m_ids中的{banned}最佳小值。
- max_trx_id:表示生成readview时系统中应该分配给下一个事务的id值。
- creator_trx_id:表示生成该readview的事务的事务id。
有了这些信息,这样在访问某条记录时,只需要按照下边的步骤判断记录的某个版本是否可见:
- 如果被访问版本的trx_id属性值与readview中的creator_trx_id值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。
- 如果被访问版本的trx_id属性值小于readview中的min_trx_id值,表明生成该版本的事务在当前事务生成readview前已经提交,所以该版本可以被当前事务访问。
- 如果被访问版本的trx_id属性值大于readview中的max_trx_id值,表明生成该版本的事务在当前事务生成readview后才开启,所以该版本不可以被当前事务访问。
- 如果被访问版本的trx_id属性值在readview的min_trx_id和max_trx_id之间,那就需要判断一下trx_id属性值是不是在m_ids列表中,如果在,说明创建readview时生成该版本的事务还是活跃的,该版本不可以被访问;如不在,说明创建readview时生成该版本的事务已经被提交,该版本可以被访问。
- 如果某个版本的数据对当前事务不可见的话,那就顺着版本链找到下一个版本的数据,继续按照上边的步骤判断可见性,依此类推,直到版本链中的{banned}最佳后一个版本。如果{banned}最佳后一个版本也不可见的话,那么就意味着该条记录对该事务完全不可见,查询结果就不包含该记录。
快照读又叫一致性读,读取的是历史版本的数据。不加锁的简单的select都属于快照读,即不加锁的非阻塞读,只能查找创建时间小于等于当前事务id的数据或者删除时间大于当前事务id的行(或未删除)。
2.当前读当前读查找的是记录的{banned}最佳新数据。加锁的select、对数据进行增删改都会进行当前读。
6.2.4 数据举例
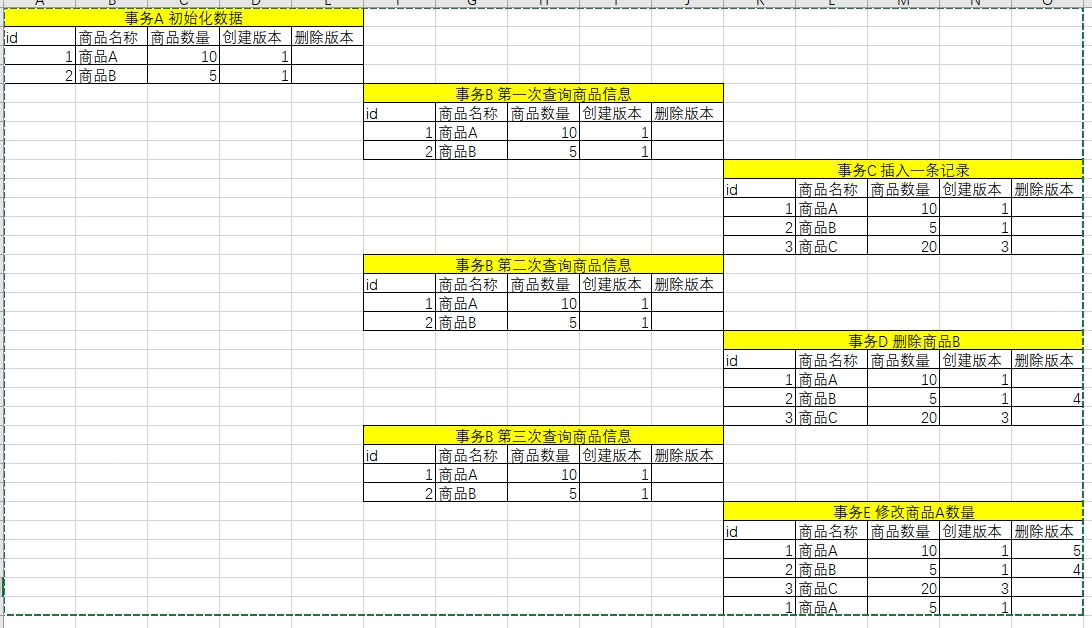
如图所示:
事务a id =1 初始化了数据
事务b id=2 进行了查询操作(mvcc只读取创建时间小于当前事务id的数据或者删除时间大于当前事务id的行)
事务b的结果是 (商品a:10,商品b:5)
事务c id =3 插入了商品c
事务b id=2 进行了查询操作(mvcc只读取创建时间小于当前事务id的数据或者删除时间大于当前事务id的行)
事务b的结果是 (商品a:10,商品b:5)
事务d id =4 删除商品b
事务b id=2 进行了查询操作(mvcc只读取创建时间小于当前事务id的数据或者删除时间大于当前事务id的行)
事务b的结果是 (商品a:10,商品b:5)
事务e id =4 修改商品a的数量
事务b id=2 进行了查询操作(mvcc只读取创建时间小于当前事务id的数据或者删除时间大于当前事务id的行)
事务b的结果是 (商品a:10,商品b:5)
所以当事务e提交后,当前读获取的数据和事务b读取的快照数据明显不同。
6.2.5 可解决问题mvcc可以很好的解决读一致问题,只能看到这个时间点之前事务提交更新的结果,而不能看到这个时间点之后事务提交的更新结果。而且降低了死锁的概率和解决读写之间堵塞问题。
7 小结
lbcc和mvcc都可以解决读一致问题,具体使用哪种方式,要结合业务场景选择{banned}最佳合适的方式,mvcc和锁也可以结合使用,没有{banned}最佳好只有更好。
作者:陈昌浩