about me:oracle ace pro,optimistic,passionate and harmonious. focus on oracle,mysql and other database programming,peformance tuning,db design, j2ee,linux/aix,architecture tech,etc
全部博文(166)
- cbo(54)
- tuning&performan(32)
- concepts&archite(4)
- troubleshooting(5)
- new feature(7)
- sql(50)
- pl/sql(8)
- miscellaneous(3)
- mysql(3)
- 未分配的博文(0)
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
分类: oracle
2023-04-24 16:52:11
hash碰撞问题
hash join是专门用来做大数据处理的高效算法,并且只能用于等值连接条件,针对表build table(hash table)和probe table构建hash运算,查找满足条件的结果集。
一般格式如下:
hash join
build table
probe table
这里的build table应该选择通过过滤条件过滤后,结果集尺寸较小的表(size不是rows),然后按照连接条件进行hash函数运算,把需要的列和hash函数运算结果存储到hash bucket中,hash bucket自身是链表结构。同样,对于probe table也需要进行hash函数运算,并根据运算结果到build table的hash bucket中去查询,查到满足,查不到丢弃。当然,oracle hash join内部构造还是很复杂的,具体可以参考jonathan lewis的cbo原理书。
hash查找天生存在的问题:
一旦build table的连接条件列选择性不好(也就是重复值特别多),那么某些hash bucket上可能存储大量数据,由于hash bucket自身是链表结构,那么当查询这些hash bucket时,效率会急剧下降,此问题就是hash运算的经典问题hash collision(hash碰撞)。
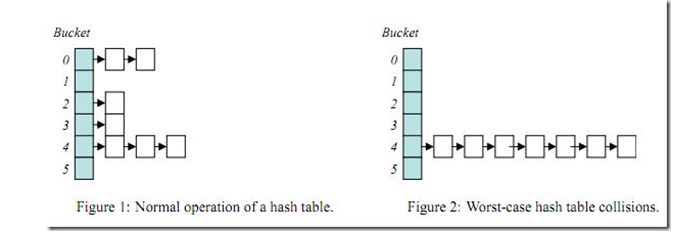
下面用一个小例子来分析下hash碰撞:
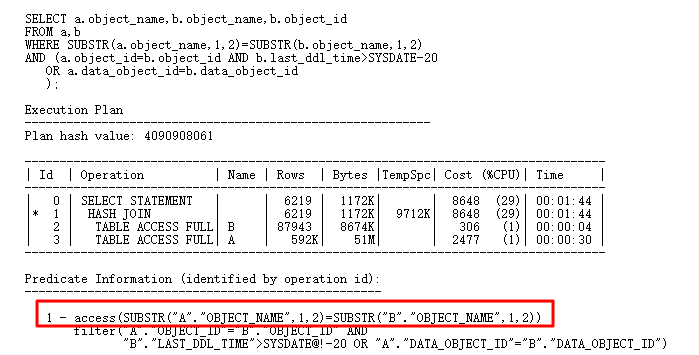
其中a表61w多条记录,b表7w多条记录,此sql结果返回8w多条记录,从执行计划来看,做hash join运算没有什么问题,但是实际此sql执行10多分钟都没有执行完,效率非常低下,cpu使用率突增,远远大于访问两个表的时间。
如果你了解hash join,这时候,你应当考虑是不是遇到hash collision了,如果很多bucket上存储大量数据,那么对于这样的hash bucket里的数据查找那就类似于nested loops了,必然效率大减。如下进一步分析:

查找一下大于重复数据大于3000条的值,果然有很多,当然剩下数据也有很多比较大,探测hash join,可以使用event 10104:
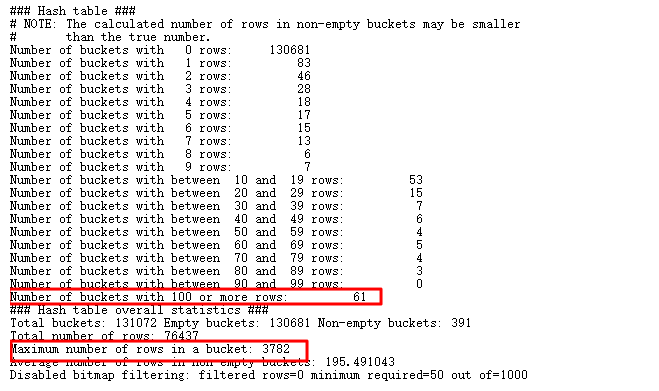
可以看到存储100行的bucket有61个,而且{banned}最佳多的一个bucket中存储了3782条,也就是和我们查询出来的一致。还是回到原始sql:

oracle为什么选择substr(b.object_name,1,2)来构建hash表呢,如果能将or展开,原始sql改为一个union all形式的,那么hash表可以采用substr(b.object_name,1,2)和b.object_id以及data_object_id来构建,那么必然唯一性很好,那应该可以解决hash collision问题,改写如下:

现在的sql执行时间从原来的10几分钟都没有结果,到4s执行完毕,再来看内部构建的hash table信息:
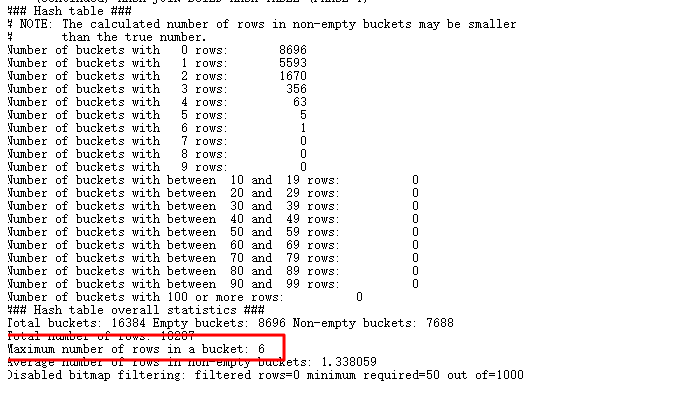
{banned}最佳多的一个bucket中只存储6条数据,那肯定性能比前面好很多了。hash碰撞的危害很大,实际应用中,可能比较复杂,如果遇到hash碰撞问题,{banned}最佳好的方式就是进行sql重写,尽量从业务上分析,能不能增加其它选择性比较好的列进行join。
回头来看看,既然我都知道改写成union all后,就采用2个组合列构建比较好的hash表,那么oracle为什么不这样做呢?很简单,我这里只是举例刻意这么做的而已,用以说明hash碰撞的问题,对于这种简单sql,有选择性更好的列,收集下统计信息,oracle就可以将的sql进行or展开了。