将晦涩难懂的技术讲的通俗易懂
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
分类: 高性能计算
2024-09-22 20:37:10
allreduce 相关算法-凯发app官方网站
allreduce 有不同的实现算法,比如基于 ring 的 allreduce 和基于 tree 的 allreduce。它们之间有各自不同的场景和优劣。
ring allreduce:是一种环形拓扑结构的 allreduce 算法,假设有 n 个节点参与
l 通信过程:
1. reduce-scatter 阶段。
2. allgather 阶段。
优点:带宽利用率高,因为在每个通信步骤中,所有节点都在同时发送和接收数据。
缺点:延迟较高,尤其是当节点数量较多时,由于需要进行 2*(n-1) 次通信。
tree allreduce:采用树状拓扑结构进行通信
l 通信过程
1. reduce阶段:从叶子节点开始向根节点汇聚数据,根节点{banned}最佳终得到完整的结果。
2. broadcast 阶段:根节点将汇总的结果沿树结构向下广播给所有节点。
优点:通信步骤少,通常为 2*log(n),因此在大规模节点时延迟较低。
缺点:在每一步中,只有部分节点参与通信,带宽利用率相对较低。
总体来说:
ring allreduce 更适合在高带宽、低延迟的网络环境下使用,特别是当节点数量较小时,它能更好地利用带宽资源。
tree allreduce 更适合在节点数量较多或网络延迟较高的情况下使用,因为它的通信延迟随节点数量增长的速度较慢。
下面就逐个具体分析这两个算法和实现。
ring allreduce
allreduce 是集合通信中常见的分布式计算操作,主要用于需要在多个设备(如多台服务器或多个 gpu)之间聚合数据的场景,可以包含 sum、min、max 等操作。以 allreducesum 为例,假设有 k 个 设备,每个设备上有 n 个数据,则 allreduce 后每个设备上的 out[i] = in0[i] in1 [i] … in(k-1)[i]。如下图所示:
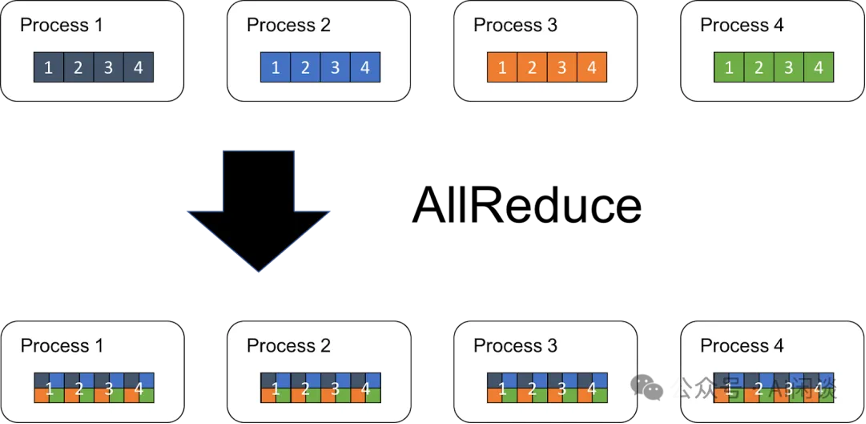
其实等效与一个reduce broadcast。但为了更多的利用当前gpu和多轨道网络的环形(ring)拓扑,一个基于 ring 的 allreduce 操作更多拆解为一个reducescatter和一个allgather操作,如下图所示:
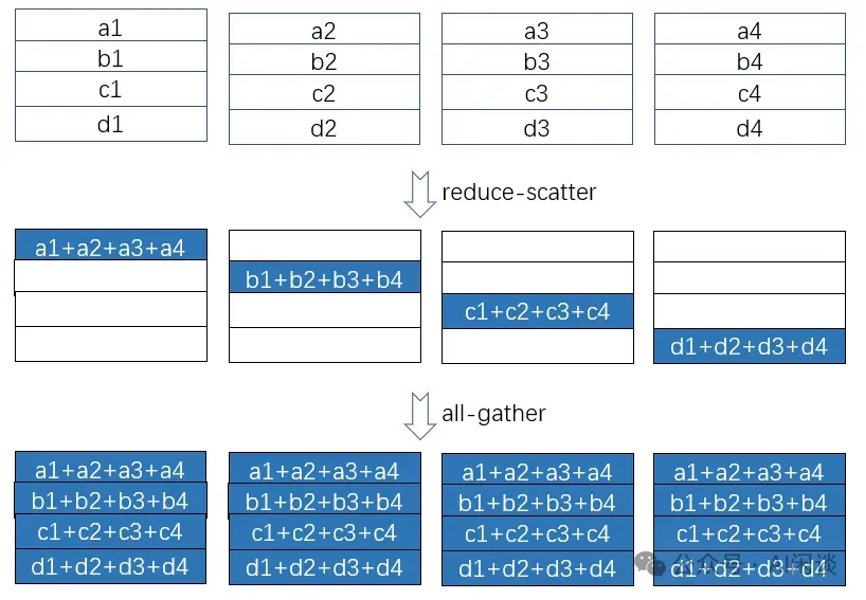
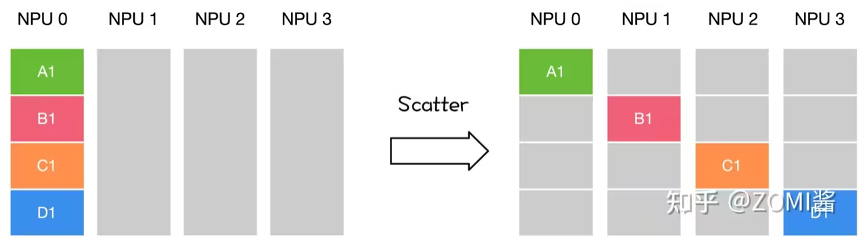
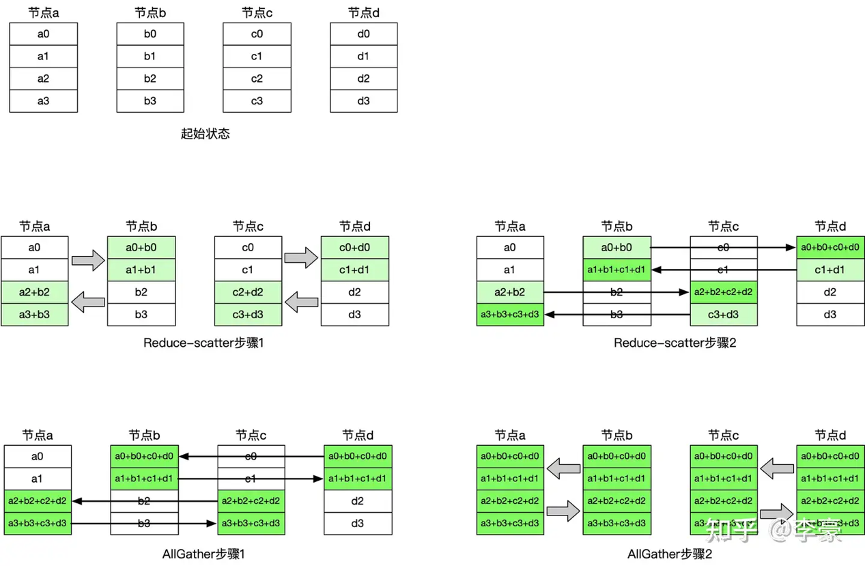
我们先来回顾一下reducescatter操作:每个节点先做scatter,再做reduce。scatter操作表示一种散播行为,将主节点的数据进行划分并散布至其他指定的节点。
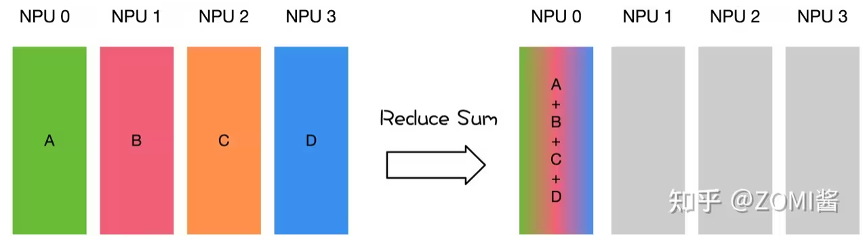
reduce,从多个sender那里接收数据,{banned}最佳终combine到一个节点上。
reduce scatter操作会将个进程的输入先进行求和,然后在第0维度按卡数切分,将数据分发到对应的卡上。
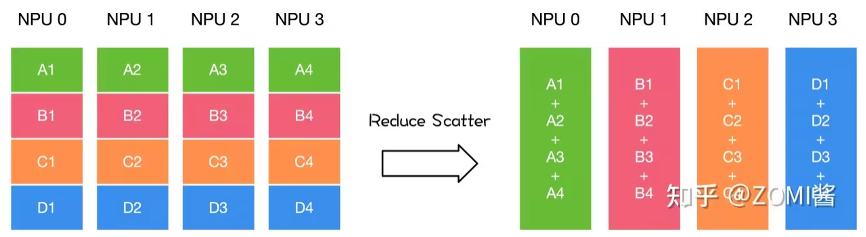
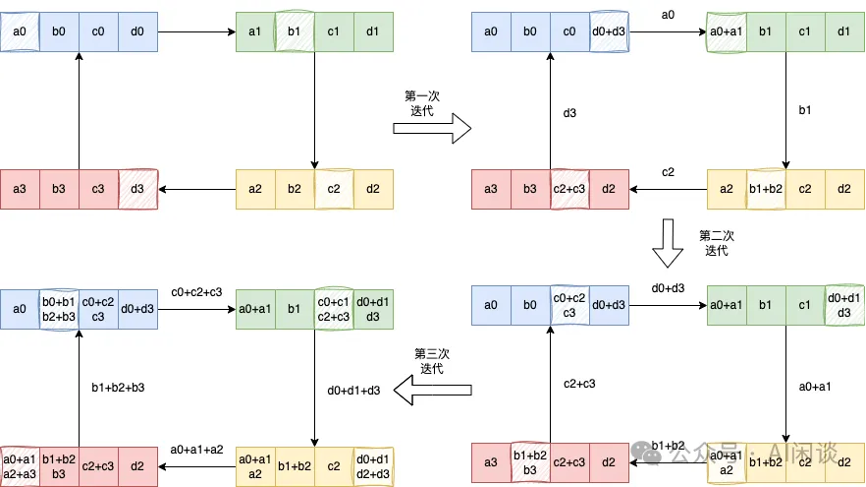
然后我们看下具体基于ring的 reducescatter操作如下,每个节点发送一部分数据给下一个节点,同时接收上一个节点的数据并累加,这个过程进行 n-1 步。reducescatter 后每个设备都包含一部分数据的 sum:
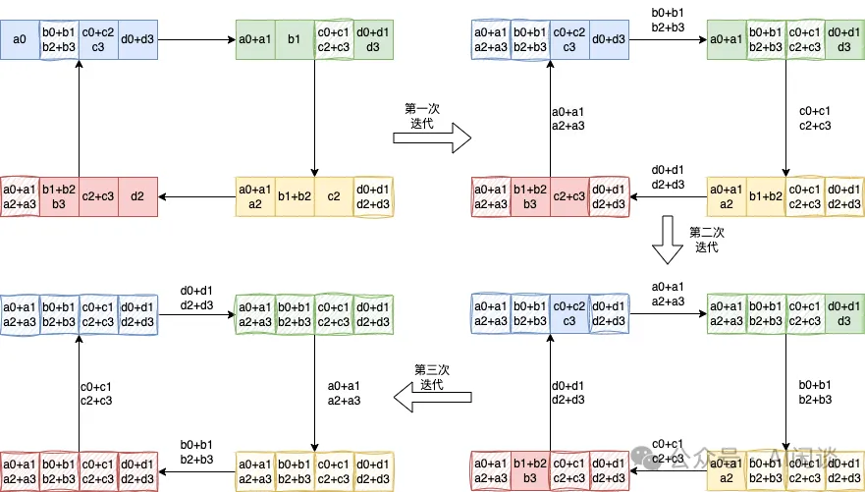
具体的 allgather操作如下,每个节点将其持有的部分结果发送给下一个节点,同时接收上一个节点的部分结果,逐步汇集完整的结果。allgather 后,每个设备都包含全量的数据:
allreduce 带宽
如上所示,allreduce 操作可以分成 reducescatter和 allgather操作,假设 gpu 数量为 k,则每一个阶段的通信量为 (k-1) * t * sizeof(dtype),假设每个 gpu 的总线带宽为 busbw,则 allreduce 对应的理论通信时延为:
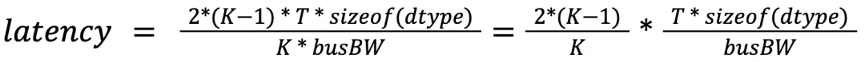
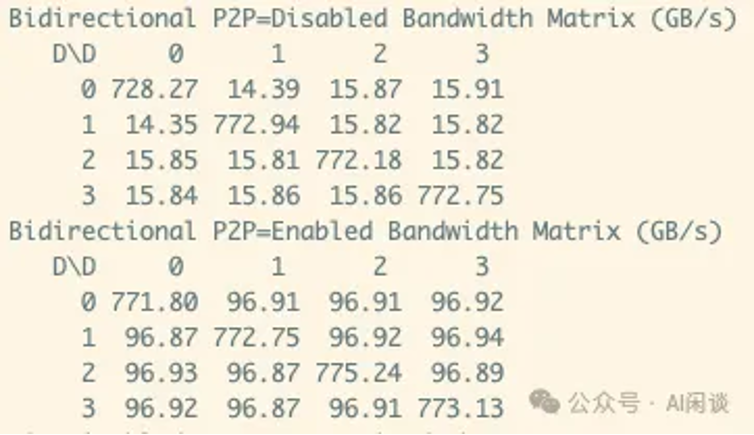
然而,实际的总线带宽并不能达到理论总线带宽,如下图所示,4*v100 通过 nvlink 互联(没有 nvswitch),每两个 gpu 之间两个 nvlink 连接,理论双向带宽为 100gb/s,实际测试也可以达到 97gb/s,如果 disable nvlink,则对应的带宽只有 16gb/s。
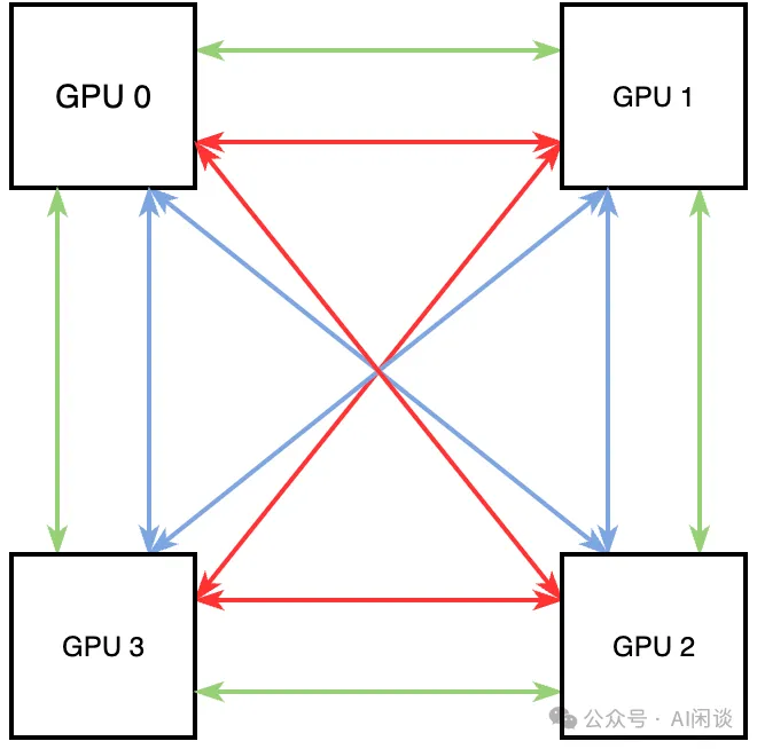
而 allreduce 通常更关注的是总线带宽 busbw,对于 4*v100 nvlink 互联(没有 nvswitch),nccl 通过如下的方式可以创建 3 个双向环,其中每个颜色都是 1 个双向环。因为每个环的单向通信带宽为 4*25gb/s,通信带宽的理论上限为 6*(4*25gb/s)=600gb/s(也可以用 12 个 nvlink * 50gb/s 得到),那么平均每个 gpu 的 busbw 为 150gb/s。
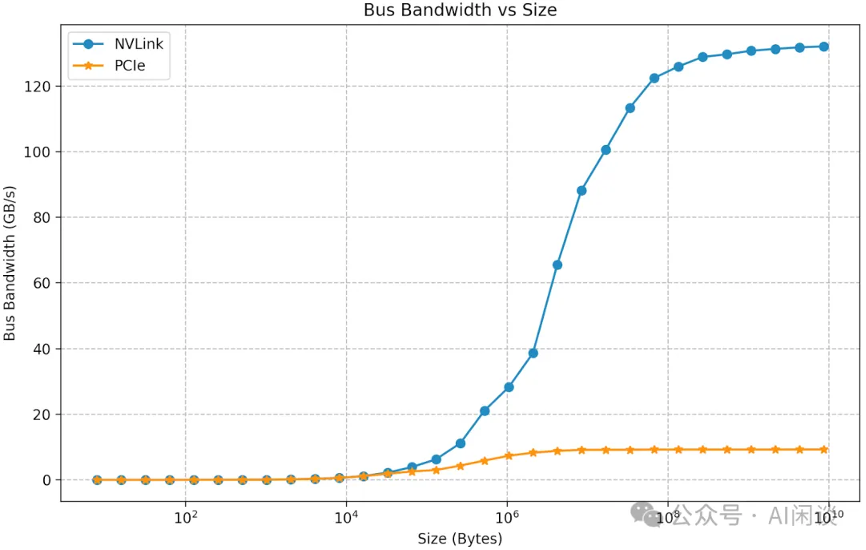
然而,实际总线带宽也与理论总线带宽有一定差距,这和数据量、gpu 连接方式、使用的通信算法、nccl 版本等有关。如下图所示为使用 nccl 测试出的 allreduce 总线带宽,可以看出,当数据量比较小时,比如小于 1mb(106b),测试的 busbw 很低,不到 30gb/s。当通信的数据量达到 128mb 时,相应的 busbw 达到 130gb/s,基本接近极限的 150gb/s。如果没有 nvlink,则实测的 busbw 只有 10gb/s 左右。
halving-doubling
另一种常见的allreduce实现算法是halving-doubling,采用了这种算法,该算法每次选择节点距离倍增的节点相互通信,每次通信量倍减(或倍增),过程图示如下:
该算法的优点是通信步骤较少,只有 2?log2n 次(其中n表示参与通信的节点数)通信即可完成,所以其有更低的延迟。相比之下ring算法的通信步骤是 2?(n?1) 次;缺点是每一个步骤相互通信的节点均不相同,链接来回切换会带来额外开销。
double binary tree
上节我们以ring allreduce为例看到了集合通信的过程,但是随着训练任务中使用的个数的扩展,ring allreduce的延迟会线性增长,为了解决这个问题,nccl引入了tree算法,即double binary tree。
朴素的tree算法将所有机器节点构造成一棵二叉树,支持broadcast,reduce,前缀和。假设root节点要broadcast一个消息m给所有节点,root会将m发送给他的子节点,其他所有的节点收到消息m后再发送给子节点,叶节点因为没有子节点,所以叶结点只会接收m。这个过程可以将m切分为k个block,从而可以流水线起来。
但这个朴素算法有一个问题,叶节点只接收数据,不发送,因此只利用了带宽的一半,为了解决这个问题,mpi提出了double binary tree算法,假设一共有n个节点,mpi会构建两个大小为n的树t1和t2,t1的中间节点在t2中是叶节点,t1和t2同时运行,各自负责消息m的一半,这样每个节点的双向带宽可以都被利用到。以十台机器为例,构建出的结构如下:
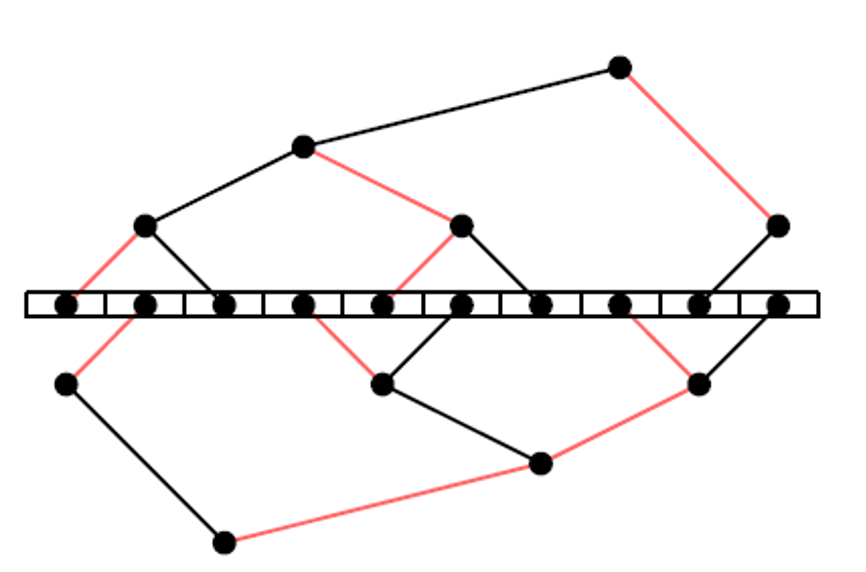
t2的构造有两种方式,一种是shift,将rank向左shift一位,比如rank10变成rank9,然后通过和t1一样的方式构造,这种构造方式下t1和t2的树结构完全一致;另外一种是mirror,将rank号镜像一下,比如rank0镜像为rank9,这种构造方式下t1和t2树结构是镜像对称的,不过mirror的方式只能用于机器数为偶数的场景,否则会存在节点在两棵树中都是叶节点。
如上图,t1和t2的边可以被染成红色或者黑色,从而有如下很好的性质:
l 不会有节点在t1和t2中连到父节点的边的颜色相同,比如node a在t1中通过红色的边连到父节点,那t2中a一定通过黑色的边连到父节点。
l 不会有节点连到子节点的边颜色相同,比如node a在t1中是中间节点,如果a通过红色的边连到左子节点,那么a一定通过黑色的边连到右子节点
根据上述性质,就有了两棵树的工作流程,在每一步中从父节点中收数据,并将上一步中收到的数据发送给他的一个子节点,比如在偶数步骤中使用红色边,奇数步骤中使用黑色边,这样的话在一个步骤中可以同时收发,从而利用了双向带宽。
nccl中的tree只用于节点之间,节点内是一条链,2.7.8版本使用的pattern为nccl_topo_pattern_split_tree,假设为4机32卡,对于t2后边再介绍,t1如下所示:
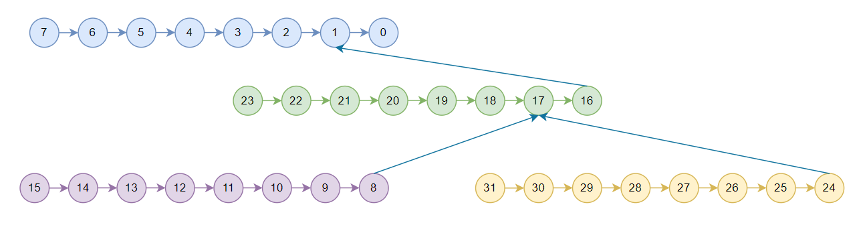
由于allreduce可以拆分为reduce和broadcast两个过程,所以nccl tree allreduce先执行reduce,数据按照图中箭头方向流动,称为上行阶段,从rank15,rank31,rank23,rank7开始一直reduce到rank 0,rank0拿到全局reduce的结果之后再按照箭头反方向开始流动,称为下行阶段,broadcast到所有卡。
sharp
之前我们看到了基于ring和tree的两种allreduce算法,对于ring allreduce,一块数据在reduce scatter阶段需要经过所有的rank,allgather阶段又需要经过所有rank;对于tree allreduce,一块数据数据在reduce阶段要上行直到根节点,在broadcast阶段再下行回来,整个流程比较长。
ib sharp
因此基于这一点,mellanox提出了sharp,将计算offload到了ib switch,每个节点只需要发送一次数据,这块数据会被完成规约,然后每个节点再接收一次就得到了完整结果。下图展示了一个胖树物理网络拓扑,其中绿色节点为交换机,黄色节点的为host。
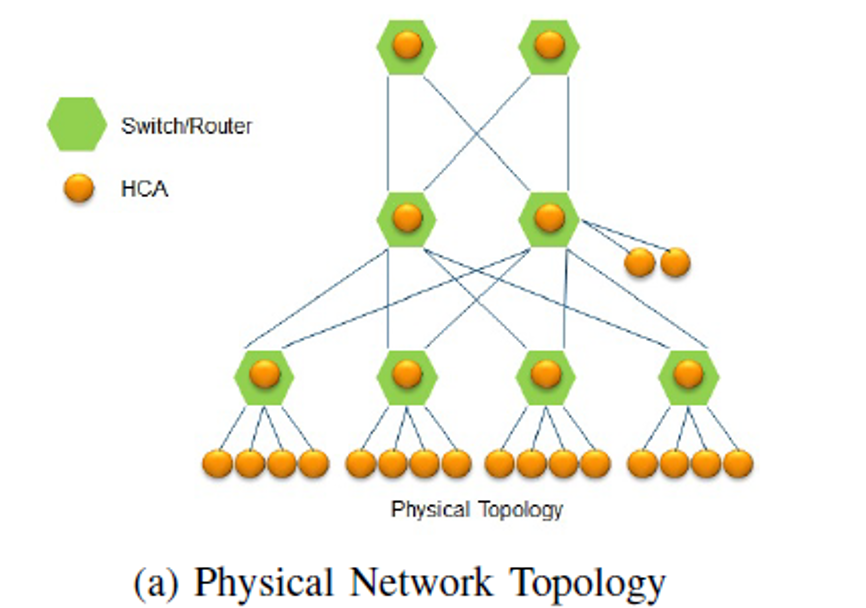
下图展示了基于上图的物理网络拓扑,这些host节点执行sharp初始化后得到的sharp tree,sharp tree是个逻辑概念,并不要求物理拓扑一定是胖树。
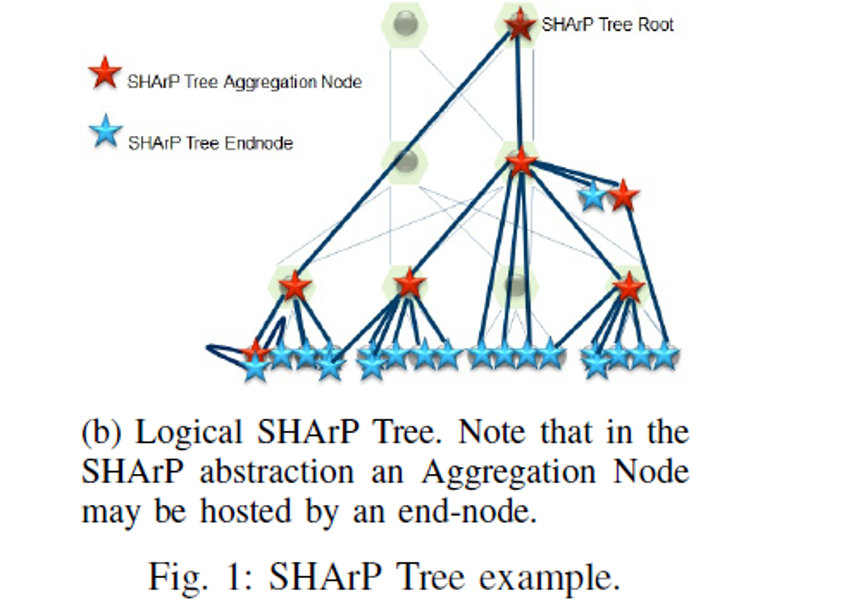
值得注意的是:
l 其中一个交换机可以位于{banned}最佳多64个sharp tree中,
l 一个sharp tree可以建立大量的group,group指的是基于现有的host创建的一个子集
l 支持数百个集合通信api的并发执行
nvlink sharp
进一步的,在hopper架构机器中引入了第三代nvswitch,就像机间ib sharp一样,机内可以通过nvswitch执行nvlink sharp,简称nvls。