将晦涩难懂的技术讲的通俗易懂
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
分类: 云计算
2024-09-01 12:17:34
rdma高级特性
mr
memory region (mr):用户通过ibv_reg_mr向对端暴露一块内存(iova va len key),iova是对端来访问所用地址,va是本地访问所用地址,它们都需在硬件里翻译为pa,所以注册mr涉及建立mtt地址翻译表。同时也需为mr指定访问权限如可读可写,这涉及建立mpt表。mr所涵盖的物理内存需要在注册时pin住以避免dma访问swapped out的页。注册mr可以指定mr的访问权限(local/remote read/write)。mr注册好之后会返回lkey和rkey,lkey用于自己访问自己,rkey用于别人访问自己。一片内存区可以多次注册mr,每次可以设置不同的访问权限,每次都会返回不同的lkey和rkey。
memory window (mw):mw允许用户更灵活的控制远端对本地内存的访问:动态的授予和收回远端对mr的访问权限,给不同的远端以不同的访问权限,为mr内的不同range的小块内存授予不同的访问权限。注册mr时需要同时建立表和安全保护表,但注册mw仅需建立安全保护表,所以建立mw可以直接在用户态与硬件通信完成而不需要经过内核。 ibv_bind_mw用于建立mw,它其实也是向qp里post了一个请求。
点击(此处)折叠或打开
-
mr = ibv_reg_mr(pd, addr, len, access);
-
mw = ibv_alloc_mw(pd, ibv_mw_type_1);
-
-
struct ibv_mw_bind bind = {.wr_id = xxx, .send_flags = xxx,
-
.bind_info = {.mr = mr, .addr = x, .length = y, .mw_access_flags = read/write}, };
- ibv_bind_mw(qp, mw, bind);
zero based mr:mr注册后正常情况下对端是拿本端的va地址来访问,但这容易泄露某些信息或者va在进程重启后会变化。此时可调用ibv_reg_mr创建一个zero based mr (access flags |= ibv_access_zero_based),这样对端拿来访问的地址会在本端hca被当成是mr的偏移,而不是一个具体的va。
mr with iova:有的时候用户希望指定对端用来访问本地mr的地址,此即iova。 ibv_reg_mr_iova(pd, addr, length, iova, access) 在注册mr时同时指定iova,当对端用地址x来访问mr时,它真正访问的本地进程va是 (x - iova addr)。
user-mode memory registration (umr)
l
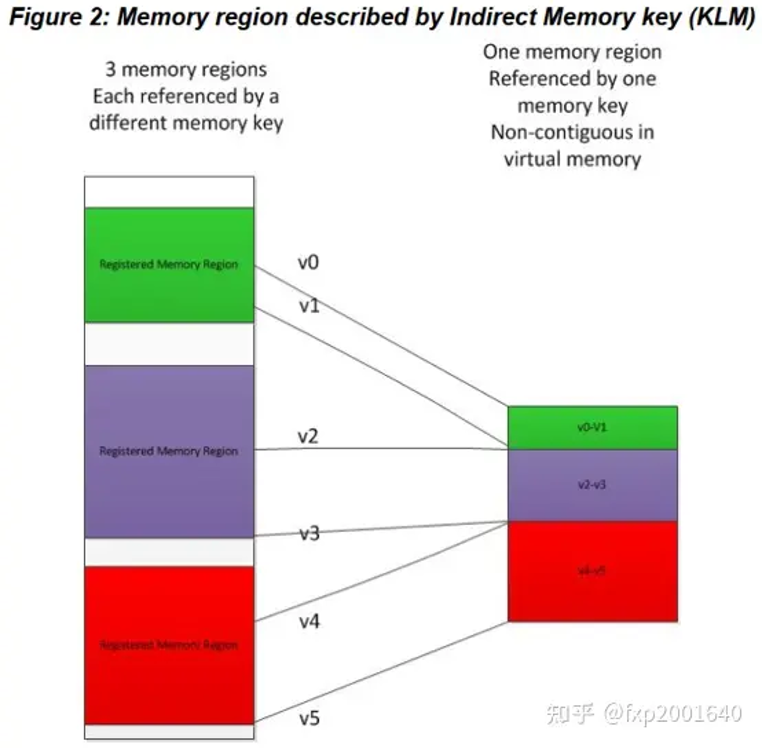
将多块非连续的mr拼接成一个va连续的mr如上图所示,我们之前创建了3个常规得mr:mr1(green), mr2(purple), mr3(red),现在我们想从这三个mr中各抽取一部分拼接起来形成一个新的连续的mr:{banned}中国第一块是mr1(v0-v1)部分,第二块是mr2(v2-v3)部分,第三块是mr3(v4-v5)部分。这个新的mr有一个新的base va地址,长度是3个小块的长度之和。这样虽然内部是不连续的,但在外部访问者看来这个mr是连续的。
l
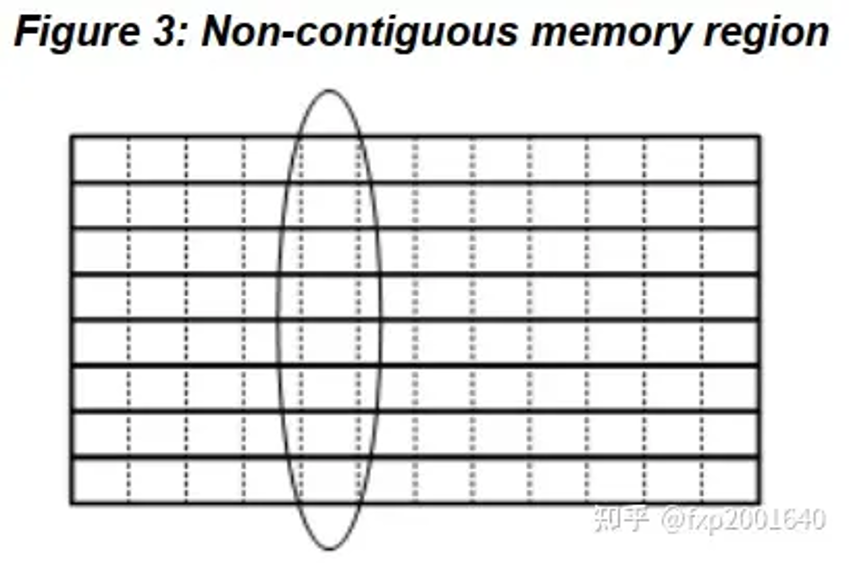
将一个mr内有规律非连续的块拼接成一个连续的mr如上图所示,当我们做一个矩阵的转置时需要把一列的元素拼成新的行,这个行就成了新的连续的mr。老矩阵的列元素一般可以用<基地址(base address), 元素间距(stride),元素长度(block size),元素数量(repeat count)>来描述。
l
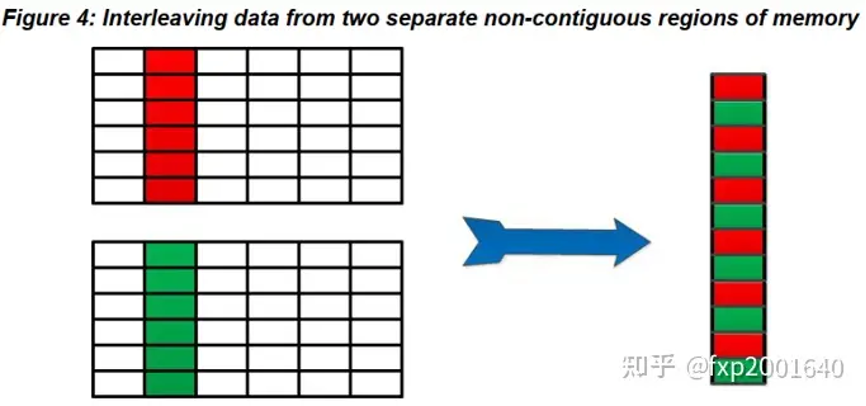
将多个mr拼接成新的相互交织的连续mr如上图所示,2个老矩阵的列相互交织形成新的列,这是一个新的va连续的mr,有它自己的新的base address和length。
点击(此处)折叠或打开
-
int num_interleaved = 1,repeat_count = 2,message_size = 4096;
-
int skip_bytes_interleaved = 20;
-
-
mlx5_qp_attr.comp_mask = mlx5dv_qp_init_attr_mask_send_ops_flags;
-
mlx5_qp_attr.send_ops_flags = mlx5dv_qp_ex_with_mr_interleaved;
-
init_attr_ex.cap.max_inline_data = 128;
-
init_attr_ex.send_ops_flags = ibv_qp_ex_with_send;
-
-
qp = mlx5dv_create_qp(context, &init_attr_ex, &mlx5_qp_attr);
-
qpx = ibv_qp_to_qp_ex(qp);
-
dv_qp = mlx5dv_qp_ex_from_ibv_qp_ex(qpx);
-
mkey_init_attr.create_flags = mlx5dv_mkey_init_attr_flags_indirect;
-
mkey_init_attr.max_entries = 4;
-
mkey_init_attr.pd = pd;
-
-
dv_mkey = mlx5dv_create_mkey(&mkey_init_attr);
-
array_interleaved = calloc(1, num_interleaved * sizeof(struct mlx5dv_mr_interleaved));
-
qpx->wr_flags = ibv_send_inline | ibv_send_signaled;
-
array_interleaved[0].addr = (uintptr_t)mr->addr;
-
array_interleaved[0].bytes_count = (message_size - skip_bytes_interleaved) / 2;
-
array_interleaved[0].bytes_skip = skip_bytes_interleaved / 2;
-
array_interleaved[0].lkey = mr->lkey;
-
ibv_wr_start(qpx);
-
mlx5dv_wr_mr_interleaved (dv_qp, dv_mkey, access_flags, repeat_count, num_interleaved, array_interleaved);
- ret = ibv_wr_complete(ctx->qpx);
address translation: memory translation table(mtt)
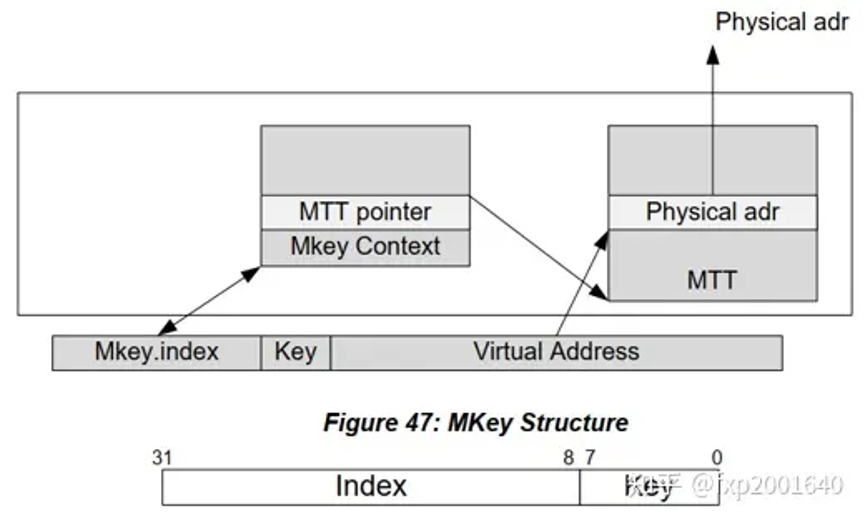

1. 使用mkey.index索引mkey context table得到mkey context。
2. key检查:对比mkey.key和mkey context里的key是否一致。
3. pd检查:对比发起内存访问的qp里的pd和mkey context里的pd是否一致。
4. 地址范围检查:mkey context对应了一个mr,里面包含address和length两个字段用于指明mr的范围,这里需要检查当前正在进行的内存访问是否在这个mr范围内。
5. 访问权限检查:根据mkey context内的local/remote read/write/atomic权限检查当前操作是否合法。
6. 当上面的检查通过时,我们就可以使用mkey context里的mtt handle了,它是mtt表的基地址。
7. 访问mtt表需要一个索引mtt index=当前访问地址accessing va - mkey_context.va得到,其中mkey_context.va是mr的起始地址。另外需要考虑pa所指向的page大小,当page为4k时,上面的mtt index还要右移12位。
8. 用上面的index索引mtt表就能得到一个mtt entry,它里面包含一个pa地址,即page number页号。如果page为4kb则{banned}最佳终的pa = (page number << 12) (accessing va & 0xfff)。
none-pin rdma
pinned rdma的问题
1,注册mr时pin住物理内存这使得可注册的内存空间受限于物理内存大小。
2,应用程序必须有锁住内存的权限。
3,持续的在软硬件之间同步地址翻译表是一个很耗时的操作。这是因为malloc/mmap/stack都会导致页表变化。
4,注册本身需要在hca建立地址映射表,而get_user_pages以及填写页表都是耗时操作,这导致注册mr很慢。
计算内存区和通信内存区

很多程序并不知道未来的数据会放在哪个va范围,也不知道未来需要使用的内存会有多大,这就导致它不能提前注册mr,只能在快要用rdma发送数据时才注册mr,而注册mr很慢又会阻塞计算。应用也不能将整个进程的虚拟地址空间注册为mr,因为没有这么多的物理内存可以pin住。这种矛盾就产生了计算内存区和通信内存区的区分:计算内存区是程序运行时动态扩张的,其大小和范围无法提前预测,而通信内存区是提前注册好的mr,其物理内存是pin住的。应用使用rdma发送数据时要先将数据从计算内存区copy至通信内存区。这是一个很大的开销。
方案一:on-demand paging (odp)
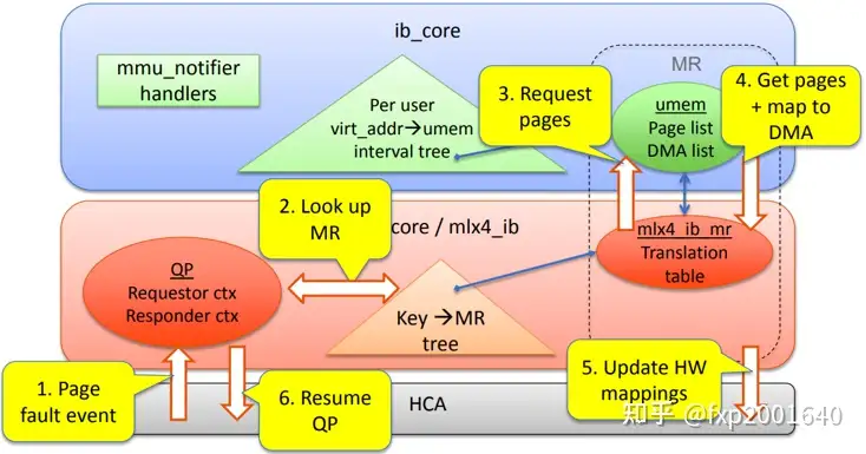
注册mr时指定ibv_access_on_demand标识则创建odp mr,其初始地址翻译表里va对应的物理页并不存在,因此设备首次访问mr va时会产生io page fault(iopf),hca驱动处理此iopf并换入所需物理页更新hca里的地址翻译表,则下次设备dma时不再发生iopf。若操作系统决定swap out va对应的物理页,也会由hca驱动更新地址翻译表将va对应entry置为page none-present。
方案二:shared virtual address (sva)
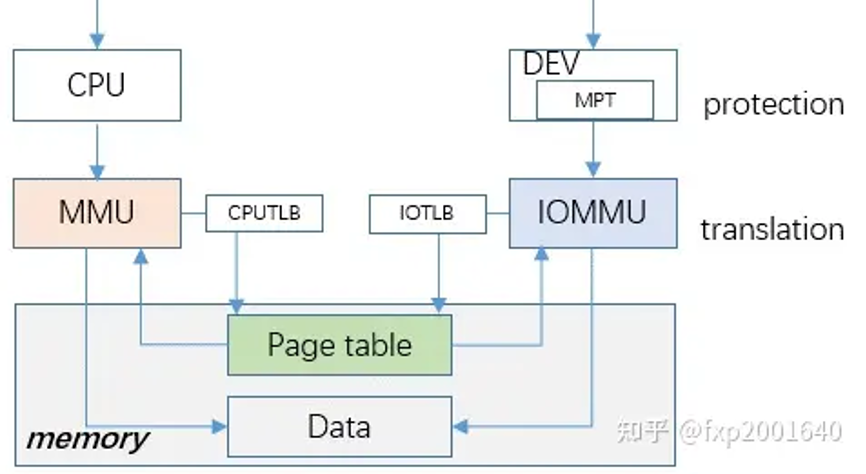
sva的思想是让设备完全共享进程的地址空间,让iommu和mmu共享同一张页表,这样进程malloc出来的内存不用做任何注册就能直接被设备所访问。它的好处是io page fault的处理可以复用大部分cpu page fault的处理逻辑,同时由于共享页表也节约了iommu另建页表所需的额外内存。因为进程地址空间完全对设备可见,所以也消除了通信内存区和计算内存区的差异。
因为共享页表后进程地址空间完全对设备可见,此时若要做安全保护则需要在设备内部设立mpt表,因为这一步只涉及安全保护不涉及建立翻译页表,所以完全可以在用户态和硬件之间完成,无需内核介入,这类似memory window。另一个问题是共享页表后,iommu需要保持与cpu的页表兼容性,无法单独设计页表格式以优化性能。cpu一般是随机访问,而设备的访问多集中在某一块区域,大多数情况下设备页表访问不需要经历4级页目录,而是一次ddr访问搞定翻译。这是sva带来的缺陷。
点击(此处)折叠或打开
-
iommu_dev_enable_feature(dev, iommu_dev_feat_iopf);
-
iommu_dev_enable_feature(dev, iommu_dev_feat_sva);
-
sva = iommu_sva_bind_device(dev, current->mm, null);
- pasid = iommu_sva_get_pasid(sva); /*经描述符传递给设备*/
共同的挑战:io page fault tlb invalidation
inline data
normal flow
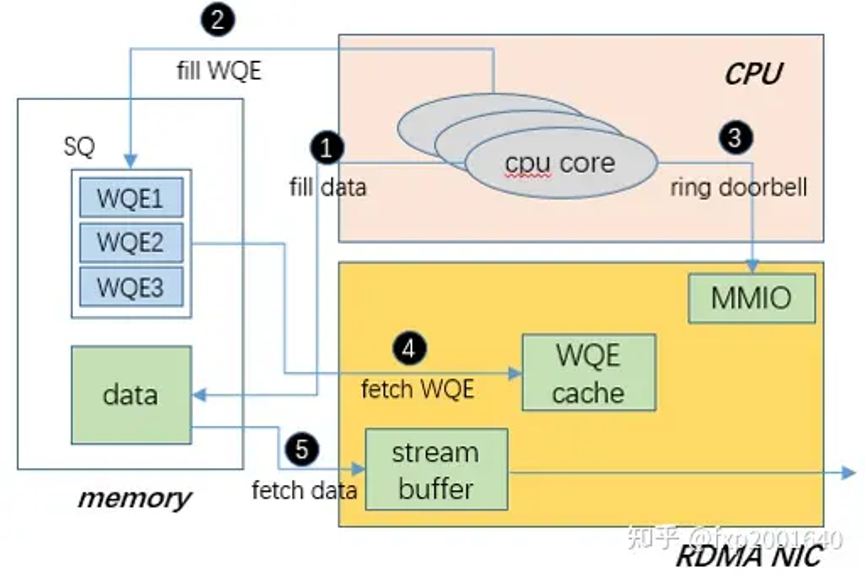
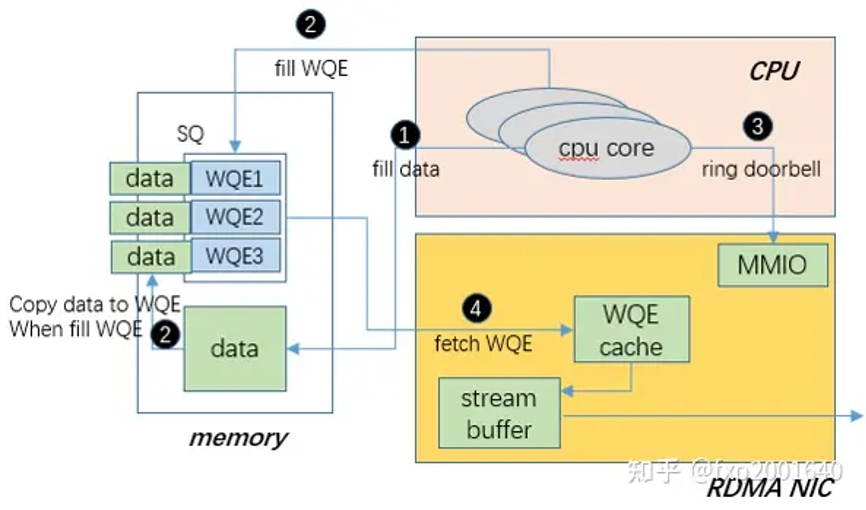
1.填充要发送的数据
2.填充wqe描述符
3.敲doorbell通知硬件有数据要发送
4.硬件通过dma读取wqe
5.硬件通过dma读取要发送的数据
direct wqe
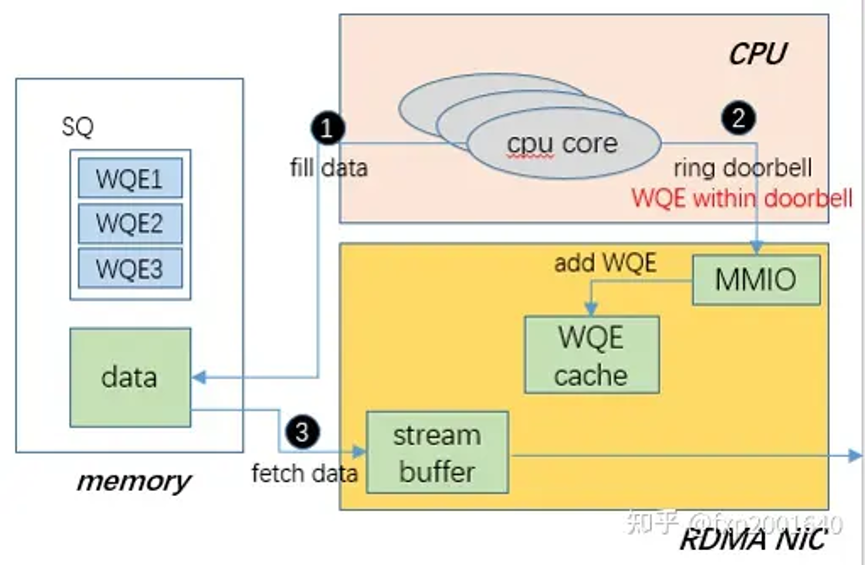
更详细的说direct wqe携带了相应的pi指针,同时还包含了当前wqe的内容,非direct wqe只有pi指针,需要设备主动发起一次wqe的pcie读操作,direct wqe方式减少了一次pcie读操作。(非direct wqe时,wqe是在host ddr中,需要设备dma读一次,而direct wqe是cpu直接将wqe写到硬件mmio空间上)
inline-send
ibv_post_send时带上ibv_send_inline标识,如果要发送的数据小于128字节则填wqe时会将这部分数据直接append在wqe的后面。这样硬件dma wqe时就顺便将data也读出来了,这样就省去了单独dma data的操作。
inline-receive
与发送类似,如果接收的是一个小数据,则没有必要将其放入rq的receive buffer中,而是可以直接将其放入cqe中。这可以省去硬件将数据dma至rq sge list的过程。使用ibv_exp_create_qp创建qp时指定max_inl_recv即可开启此功能。
hardware doorbell vs software doorbell
doorbell 的用途
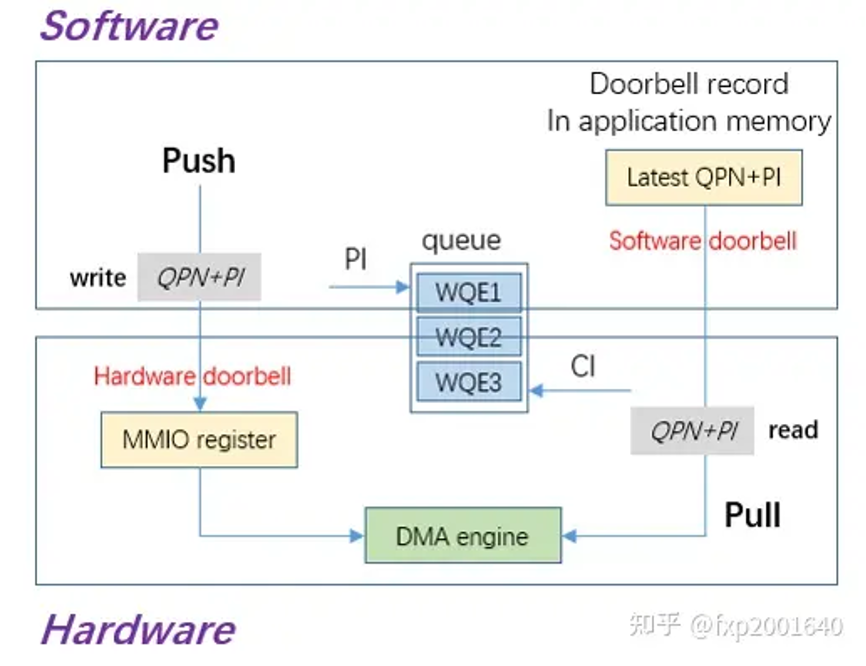
doorbell的目的是为了让软件告诉硬件queue里有新的wqe需要处理。硬件收到doorbell并不是立即处理,而是将doorbell转换为一个doorbell message暂存下来,等到调度时机到来再处理。硬件处理wqe是以batch方式进行的,一般会一次dma读取8个wqebb(每个64字节)。
push: hardware doorbell
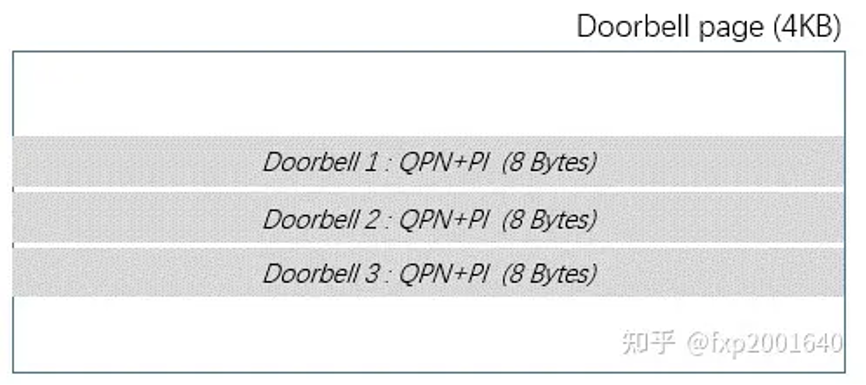
软件往sq里添加了新的wqe,硬件并不知道,所以需要一个机制让软件通知硬件queue里有新的wqe需要处理,这就是hardware doorbell。hardware doorbell本身是设备的一个mmio寄存器,一旦写这个地址硬件就能感知。写入的值包含qpn和producer index(pi)。doorbell是以page为单位分配的,每个page内可以包含多个doorbell。需要注意,由于doorbell page以页为单位分配,硬件并不关心doorbell地址的低12位,因此这里的低12位可以用于携带额外的信息,比如queue type(sq/eq/cq等)。
在verbs编程中,doorbell 是随着context的创建而分配的,context内再创建qp/cq时都会在这个doorbell page内分配具体的doorbell并关联至这个qp。当一个context关联的qp太多时可以再分配一个doorbell page。一个context支持多个doorbell可以有效地支持多个线程使用不同的qp并敲不同的doorbell,以避免并发性问题。
由于ring doorbell是一个异步过程,软件可能在返回后继续写入wqe继续敲doorbell,而此时硬件可能还没有开始处理wqe,所以会产生针对同一个doorbell的多次写入。所以硬件拿到一个doorbell message时并不表示它是{banned}最佳新的pi。另外,用户敲doorbell太频繁时也会导致doorbell message丢失。
pull: software doorbell
hardware doorbell只能告诉硬件有wqe要处理,但却不能告诉硬件{banned}最佳新的pi,因为软件会多次敲同一个doorbell而硬件并不会立即处理这些doorbell message,另外硬件以batch的方式读取wqe,可能会读到owner还不是硬件的wqe,所以硬件需要一个方式知道{banned}最佳新的pi值,这就是software doorbell的作用。software doorbell是一个8字节的内存缓冲区,它的物理地址会被写入qpc以告诉硬件。软件每次更新完wqe都需要将{banned}最佳新的pi值写入software doorbell,由于是override所以硬件读这块内存总能得到{banned}最佳新的pi值,从而判断dma读取到的wqe哪些是有效的。
stride send/receive
stride send

stride receive
stride receive是与stride send对称的操作,用于将本地一段连续的数据发送到对端,且在对端以有规律非连续的形式存放。同样在接收端也用base address, block size, stride size, repeat count四个参数描述存放位置。
streaming rdma
current problem: 传统的qp receive wqe类似udp,每个接收到的消息都会消耗一个receive buffer,这里有2个问题:如果进来的消息比receive buffer大则无法接收只能被丢弃,而如果它比receive buffer小又会造成接收缓冲区的浪费。由于我们无法预测进来的消息的大小,所以只能按{banned}最佳大尺寸分配接收缓冲区。传统的qp receive wqe会有如下2方面的问题:
1. receive buffer的利用率很低:即使大部分消息很小而只有个别大消息,我们也要按{banned}最佳大尺寸分配接收缓冲区,这就造成接收缓冲区的有效利用率很低。极端的说,如果我们按64kb分配接收缓冲区,而大部分消息是64b的,则内存利用率只有0.1%。这样的后果是小包突发时由于内存不足而导致丢包。
2. 频繁读取receive wqe会成为性能瓶颈:每收到一个消息就需要从host memory取一个receive wqe, 一个wqe是64b,而如果消息也是64b,那么相当于有效内存读写只有50%,这在很多场景下是性能瓶颈。
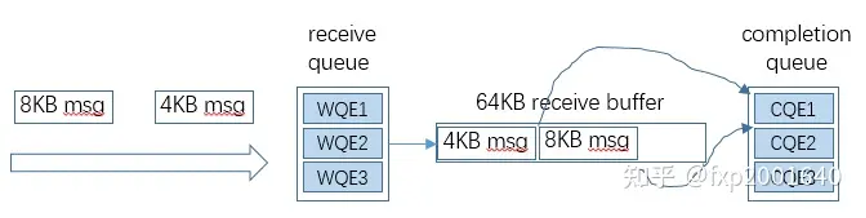
streaming receive是说每个进来的消息只消费它自身的大小而不是整个receive wqe,接收缓冲区剩下的部分可以接收下一个消息,因此一个receive wqe可以接收多个消息只要它能容纳。这就解决了接收缓冲区利用率低和频繁读取receive wqe的问题。
streaming receive时每个消息还是会上报一个cqe,所以cqe中要指明消息放在wqe receive buffer的起始和终止位置。一个消息只能放在一个wqe receive buffer中而不能跨wqe。注意这样做了之后,cqe的数量将要大于rq中wqe的数量,所以创建cq时需要加大深度。另外的一个策略是使receive buffer size更大而让rq深度变小。
tag matching and rendezvous offload
tag matching offload

mpi send操作除了指定通信组communicator和通信对象dest之外,还会指定一个tag表示用作某个特定用途的数据。而mpi receive也会指定(source, tag, communicator),这称之为一个envelope信封,表示消息的接收者信息。对于常规的网卡来说它只会接收报文放在一个通用的缓冲区里,而解析envelope的动作需要cpu进行,解析出tag之后再将数据搬运至tag关联的真正的缓冲区,这就引入了一次额外的copy,并且因为它是靠cpu进行的,所以非常耗cpu资源。
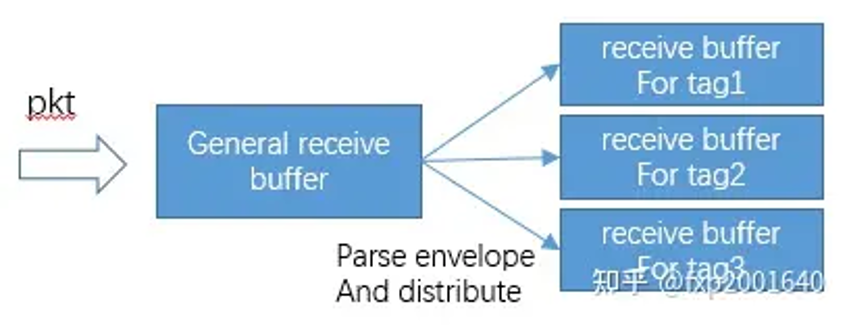
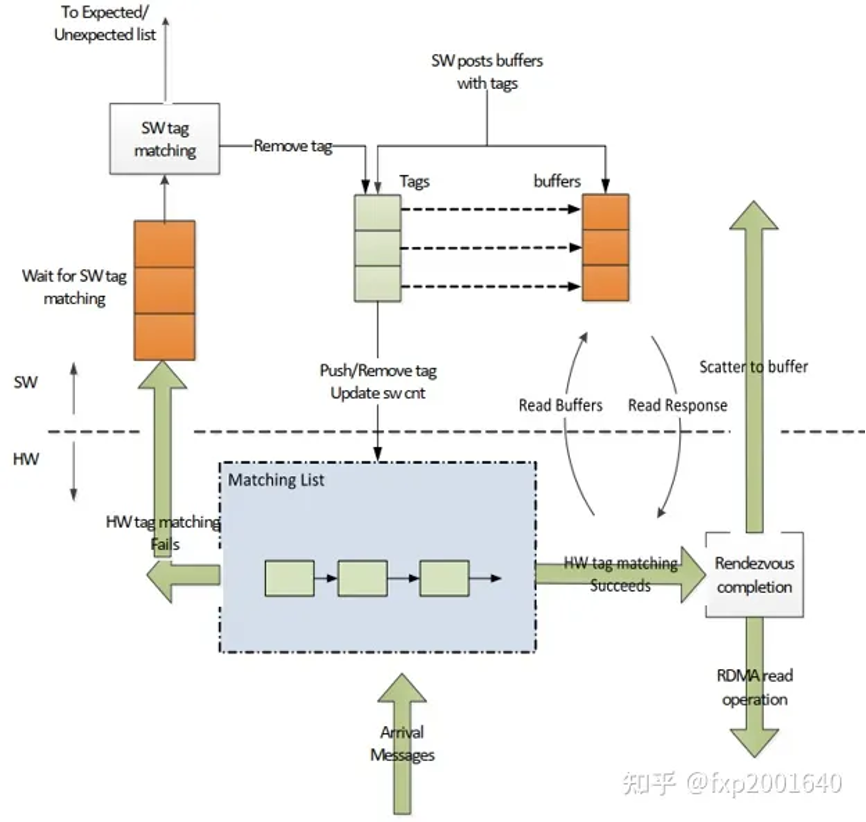
这里的矛盾在于常规网卡不touchpayload里的用户数据,所以理解不了envelope,这正是tag matching offload需要做的事:软件将tag matching list告诉网卡,网卡从接收报文的固定位置处读取envelope解析出tag,然后跟软件下发的tag matching list逐一比较,若命中则将接收的报文写入tag指向的缓冲区,并通过cq告知软件。这样软件收到通知时数据已被放置在{banned}最佳终目的地,而无需cpu再次搬运。
点击(此处)折叠或打开
-
struct ibv_srq *srq = ibv_create_srq_ex(context, &attr);//attr.srq_type = ibv_srqt_tm;
-
//create the rc/dc qp, set qp_init_attr->srq to point to srq
-
struct ibv_qp *qp = ibv_create_qp(pd, &qp_init_attr);
-
ibv_post_srq_recv(srq, &wr, &bad_wr); //for the unexpected buffers
-
// create ops_wrs *wr in struct ibv_ops_wr with information for the tm_data structure
-
ibv_post_srq_ops(srq, wr, bad_wr); // use opcode ibv_wr_tm_add
- ibv_poll_cq_ex(srq->cq, 1, wc);
rendezvous offload
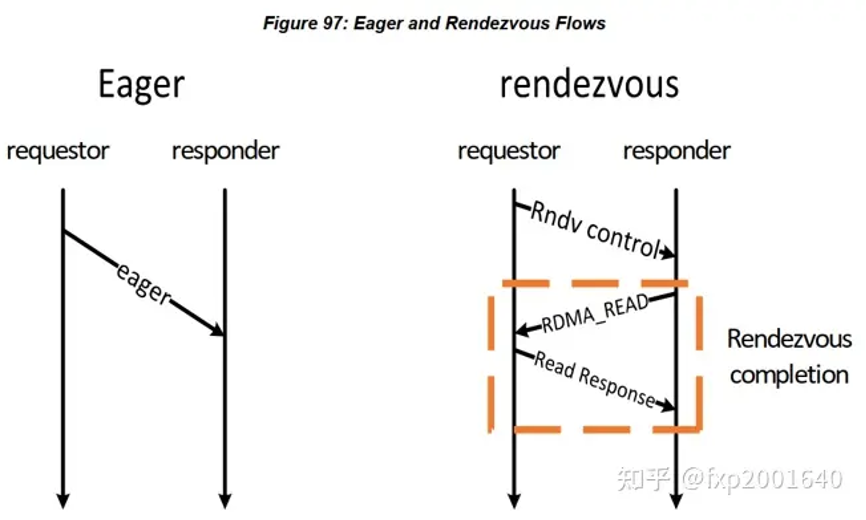
发送端发一个小消息给接收端时直接将数据放在报文里带过去,这称之为eager protocol。但若是一个大消息则可能因为接收侧没有这么大的接收缓冲区而失败,所以另一种做法是先发送一个小的控制消息rndv给接收侧告诉它真正消息的地址和长度以及key,接收侧会在接收缓冲区ready后反向来读数据。 rendezvous protocol可以用软件实现也可以由硬件实现,但硬件实现可以让rendezvous send变成类似read/write的单边操作,节省cpu资源。
点击(此处)折叠或打开
-
qp = ibv_create_qp(pd, &qp_init_attr);
-
// create ibv_tm_info *tm with header information (tm, rndv, dc)
-
int size = ibv_pack_tm_info(buf, tm);
-
// merge buf with the payload – create work requests *wr
-
ibv_post_send(qp, wr, bad_wr);
-
// if the protocol is rendezvous, wait for the final (fin) message.
- ibv_poll_cq_ex(send_cq, 1, wc);
srq
为什么需要shared receive queue (srq)
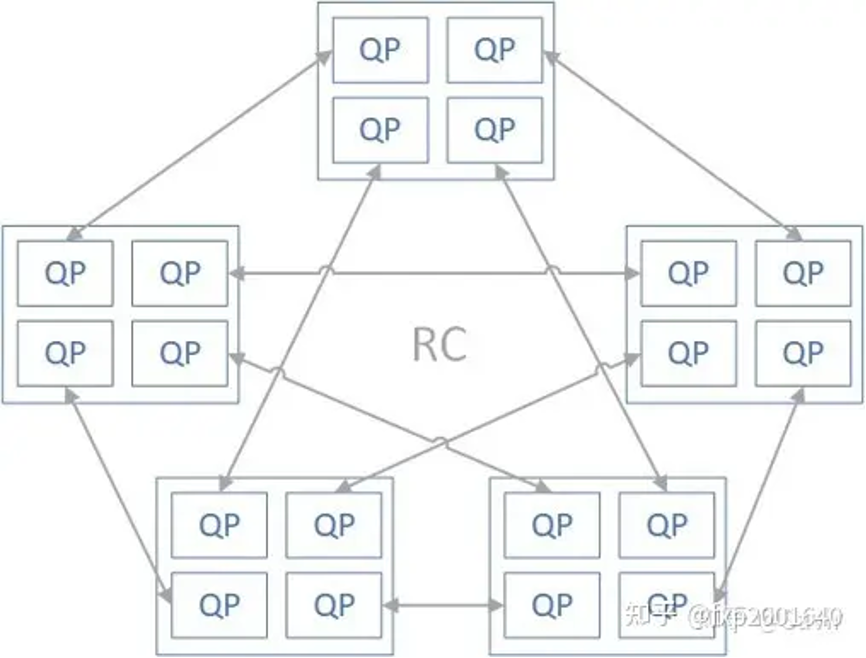
但是正如我们前文所说,{banned}中国第一种方法由于是为{banned}最佳坏情况准备的,大部分时候有大量的rq wqe处于空闲状态未被使用,这对内存是一种极大地浪费;第二种方法虽然不用下发那么多rq wqe了,但是流控是有代价的,即会增加通信时延。
而srq通过允许很多qp共享接收wqe(以及用于存放数据的内存空间)来解决了上面的问题。当任何一个qp收到消息后,硬件会从srq中取出一个wqe,根据其内容存放接收到的数据,然后硬件通过completion queue来返回接收任务的完成信息给对应的上层用户。
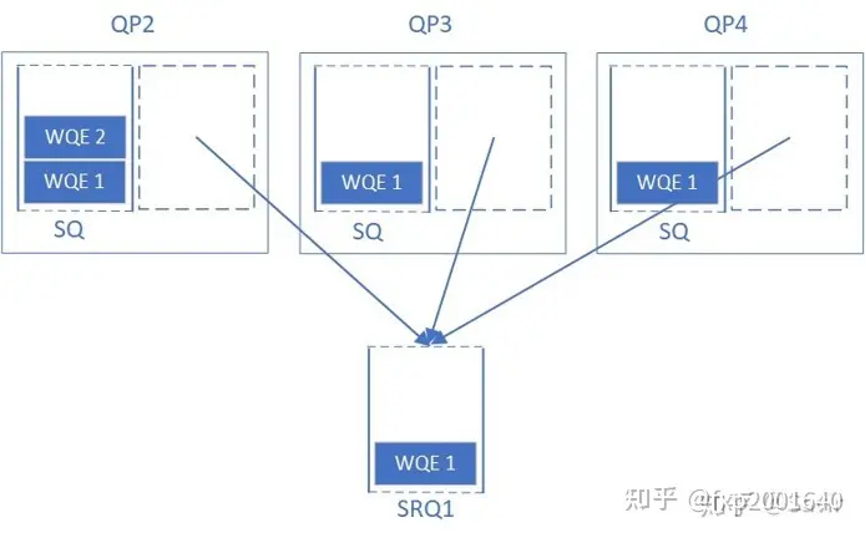
srq使用流程
点击(此处)折叠或打开
-
attr = {.attr = {.max_wr = rx_depth, .max_sge = 1}};
-
srq = ibv_create_srq(pd, &attr);
-
srq_attr = {.max_wr=1024, .max_sge=8, .srq_limit=800};
-
ibv_modify_srq(srq, &srq_attr, isrq_attr_mask);
-
-
for (i = 0; i < num_qp; i) {
-
init_attr = { .send_cq = cq, .recv_cq = cq, .srq = srq,
-
.cap = {.max_send_wr = 1, .max_send_sge = 1},
-
.qp_type = ibv_qpt_rc };
-
qp[i] = ibv_create_qp(ctx->pd, &init_attr);
-
}
-
-
sge_list = {.addr = buf, .length = size, .lkey = lkey};
-
wr = {.wr_id = pingpong_recv_wrid, .sg_list = &list, .num_sge = 1};
- ibv_post_srq_recv(srq, &wr, &bad_wr);
other processing is the same with normal qp
srq limit
srq可以设置一个水线/阈值,当队列中剩余的wqe数量小于水线时,这个srq会就上报一个异步事件。提醒用户“队列中的wqe快用完了,请下发更多wqe以防没有地方接收新的数据”。这个水线/阈值就被称为srq limit,这个上报的事件就被称为srq limit reached。
xrc
为什么需要the extended reliable connected transport service (xrc)
当前的计算节点一般都有多核,因此可以运行多进程。在这样的计算节点组成的集群中,如果想用rc连接建立full mesh的全连接拓扑时,每个节点就需要建立n*p*p个qp(这里假设集群有n个节点,每个节点上有p个进程,需要让任何2个进程都连通)。当集群扩张,n和p同时增长时,一个节点所需的rc qp资源将变得不可接受。
xrc的思想是当一个进程想与某个远程节点的p个进程通信时不需要跟各个进程建立p个连接而只需要跟对端节点建立一个连接,连接上传输的报文携带了对端目的进程号(xrc srq),报文到达连接对端(xrc tgt qp)时根据进程号分发至各个进程对应的xrc srq。这样源端进程只需要创建一个源端连接(xrc ini qp)就能跟对端所有进程通信了,这样所需总的qp数量就会除以p。
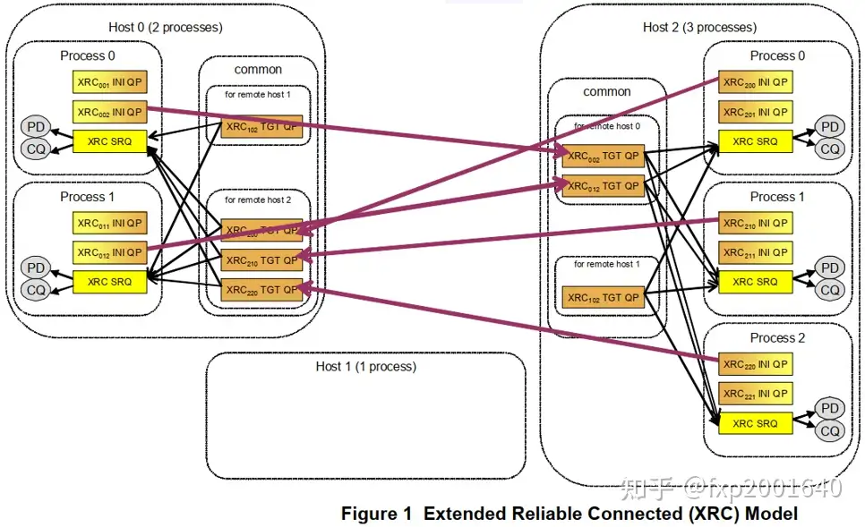
xrc ini qp:xrc发起端qp,是xrc操作的源端队列,用于发出xrc操作,但它没有接收xrc操作的功能,对比常规rc qp来说可以认为它是只有sq没有rq。xrc操作在对端由xrc tgt qp处理。
xrc tgt qp:xrc接收端qp,它处理xrc操作将其分发至报文srq number对应的srq。xrc tgt qp只能接收xrc操作,但它没有发出xrc操作的功能,对比常规rc qp来说可以认为它是只有rq没有sq。xrc操作在对端由xrc ini qp发出。
xrc srq:接收缓冲区(receive wqe)被放在xrc srq中以接收xrc请求,xrc请求中携带了xrc srq number,所以xrc tgt qp收到报文后会从报文指定的xrc srq中取receive wqe来存放xrc请求。
xrc domain:用于关联xrc tgt qp和xrc srq,xrc报文只能指定与xrc tgt qp在同一domain内的xrc srq,否则报文会被丢弃。这起到了隔离资源的作用,防止攻击报文随意指定xrc srq。
xrc ini qp和xrc tgt qp是一一对应的,host2上的每个进程在远端节点host0上都有自己对应的xrc tgt qp。xrc的共享体现在一个xrc tgt qp可以分发至多个xrc srq。一个进程一般只有一个xrc srq,它可以接收多个xrc tgt qp来的包。
xrc使用流程
点击(此处)折叠或打开
-
fd = open("/tmp/xrc_domain", rdonly | creat);
-
xrcd_attr.fd = fd;
-
xrcd = ibv_open_xrcd(ctx, &xrcd_attr);
-
-
cq = ibv_create_cq(ctx, rx_depth, null, null, 0);
-
attr = {.srq_type = ibv_srqt_xrc, .xrcd = xrcd, .cq = cq, .pd = pd};
-
srq = ibv_create_srq_ex(ctx, &attr);
-
-
init = {.qp_type = ibv_qpt_xrc_recv, .comp_mask = attr_xrcd, .xrcd = xrcd};
-
recv_qp = ibv_create_qp_ex(ctx, &init);
-
ibv_modify_qp(recv_qp, ibv_qp_state|ibv_qp_access_flags);
-
-
init = {.qp_type = ibv_qpt_xrc_send, .send_cq = cq, .pd = pd};
-
send_qp = ibv_create_qp_ex(ctx, &init);
-
ibv_modify_qp(recv_qp, ibv_qp_state|ibv_qp_access_flags);
-
-
ibv_post_srq_recv(ctx.srq, &wr, &bad_wr);
- ibv_post_send(send_qp, wr = {sge, ibv_wr_send, srqn}, &bad_wr);
dct
为什么需要dynamically connected transport (dct)
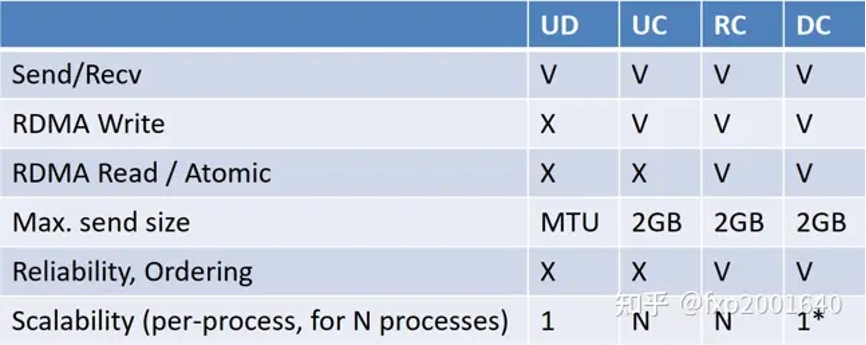
ud虽然扩展性很好,但是不支持read/write单边语义。rc虽然支持read/write单边语义,但是扩展性不好。dct的初衷就是融合2者的优点,保持rc的read/write单边语义和可靠连接特性,同时像ud一样用一个qp去跟多个远端通信,保持良好的可扩展性。dct一般用于稀疏数据场景。
什么是dct
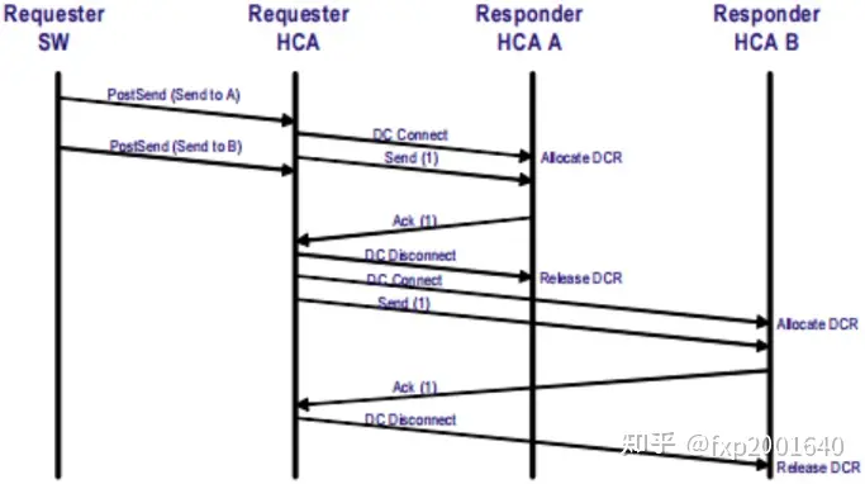
dct具有非对称的api:dc在发送侧的部分称为dc initiator(dci),在接收侧的部分称为dc target(dct)。dci和dct不过是特殊类型的qp,它们依然遵循基本的qp操作,比如post send/receive。
dc意味着临时连接,在dci上发送的每个send-wr都携带了目的地址信息,如果dci当前连接的对端不是send-wr里携带的对端,则它会首先断开当前的连接,再连接到send-wr里携带的对端。只要后续的send-wr里携带的都是当前已连接对端,则都可以复用当前已建立的连接。如果dci在一段指定的时间内都没有发送操作则也会断开当前连接。注意dct每次临时建立的是一个rc可靠连接。
dct的池化:每个dct有一个responders(dcrs)池,新进的dc连接会在这个池里分配一个dcr。当池资源不足时dct会向发起新建连接的dci回复connection nak(cnak),同时丢弃来自这个dci的后续报文。
dci的池化:当我们需要跟多个对端通信时,为避免一个dci频繁建立/断开连接从而影响性能,一般需要建立一个
半握手:{banned}中国第一个建链报文之后不等ack就发数据报文,能有效减少小包时延。全握手:类似tcp三次握手,能减少潜在的竞争条件。
create qp
点击(此处)折叠或打开
-
struct mlx5dv_qp_init_attr dv_init_attr = {0};
-
struct ibv_qp_init_attr_ex init_attr = {0};
-
-
init_attr.qp_type = ibv_qpt_driver;
-
init_attr.send_cq = send_cq;
-
init_attr.recv_cq = recv_cq;
-
init_attr.pd = pd;
-
-
if (initiator) {/** dci **/
-
init_attr.comp_mask |= ibv_qp_init_attr_send_ops_flags | ibv_qp_init_attr_pd;
-
init_attr.send_ops_flags |= ibv_qp_ex_with_send;
-
-
dv_init_attr.comp_mask |= mlx5dv_qp_init_attr_mask_dc |
-
mlx5dv_qp_init_attr_mask_qp_create_flags;
-
dv_init_attr.create_flags |= mlx5dv_qp_create_disable_scatter_to_cqe;
-
dv_init_attr.dc_init_attr.dc_type = mlx5dv_dctype_dci;
-
} else {/** dct **/
-
init_attr.comp_mask |= ibv_qp_init_attr_pd;
-
init_attr.srq = srq;
-
dv_init_attr.comp_mask = mlx5dv_qp_init_attr_mask_dc;
-
dv_init_attr.dc_init_attr.dc_type = mlx5dv_dctype_dct;
-
dv_init_attr.dc_init_attr.dct_access_key = dc_key;
-
}
-
- qp = mlx5dv_create_qp(context, &init_attr, &dv_init_attr);
12.4 dci post send
点击(此处)折叠或打开
-
struct ibv_ah_attr ah_attr = {rem_dest->lid, ib_port};
-
ah = ibv_create_ah(pd, &ah_attr);
-
-
ibv_wr_start(ex_qp);
-
ex_qp->wr_id = send_wrid;
-
ex_qp->wr_flags = ibv_send_signaled;
-
ibv_wr_send(ex_qp);
-
mlx5dv_wr_set_dc_addr(dv_qp, ah, rem_dest->dctn, dc_key);
-
ibv_wr_set_sge(ex_qp, mr->lkey, (uint64_t)mr->addr, size);
- ibv_wr_complete(ex_qp);