小公司研发总监,既当司令也当兵!
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
分类: linux
2015-05-20 10:42:44
netfilter iptables 实现分析-凯发app官方网站
netfilter/iptables是linux的第三代防火墙,在此之前有ipfwadm和ip chains两种防火墙。在网络数据包处理过程中,按照数据包的来源和去向,可以分为三类:流入的(in)、流经的(forward)和流出的(out),其中流入和流经的报文需要经过路由才能区分,而流经和流出的报文则需要经过投递,此外,流经的报文还有一个forward的过程。netfilter/iptables 正是通过将一系列调用接口,嵌入到内核ip协议栈的报文处理的路径上来完成对数据包的过滤,修改,跟踪等功能。
本文主要是结合tr781项目中实际代码和实现,梳理netfilter/iptables工作原理和基本流程。为了叙述方便,我们用netfilter描述netfilter/iptables框架的内核部分,iptables描述用户空间部分。本文除了简要介绍netfilter/iptables框架所涉及到一些概念外,致力于理解清楚以下三个问题:
(1) netfilter/iptables 是如何介入数据报处理过程的?
(2) netfilter 是如何工作的?
(3) netfilter/iptables框架下,内核空间与用户空间的数据交互是怎么进行的?
下面,我们一同走进netfilter/iptables的缤纷世。
要想理解netfilter的工作原理,必须从对linux ip报文处理流程的分析开始,netfilter正是将自己紧密地构建在这一流程之中的。关于ip协议栈的实现不在本文讨论范围内,所以不细讲。下图仅仅示意了数据包在ip协议栈中的处理流程:
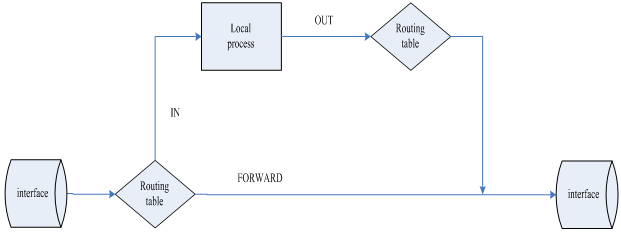
图 2-1 ip数据包处理流程示意图
报文接收从网卡驱动程序开始,当网卡收到一个报文时,会产生一个中断,其驱动程序中的中断服务程序将调用确定的接收函数来处理。驱动程序处理报文时,会生成一个skb_buff,同时将其放入一个全局的存储结构当中,同时设置软中断net_rx_softirq等待内核处理;内核收到软中断后,报文便开始了协议栈之旅。关于中断处理不是本文的重点,笔者也不甚了解,所以从略从简。我们用图2-2的流程图来表示接收报文(图2-1中,从interface经过routing table到local process)时整个处理的流程(主要是协议栈部分):
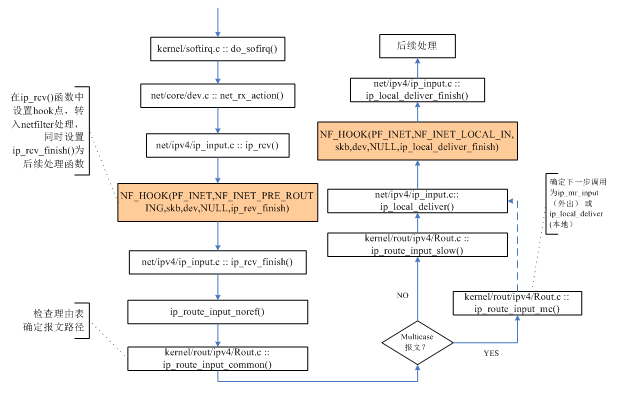
图2-2 流入ip报文处理流程
从图2-2的流程可以看出,netfilter以nf_hook形式挂载到ip协议栈对报文的处理过程中,然后将相应的数据包转入到netfilter中来处理。通常,我们将ip协议栈中调用nf_hook的地方称之为挂载点(或hook点)。除了图2-2中指出的两处挂载点外,netfitler还在ip协议栈的多处进行了挂载,下图2-3是融合了netfilter的ip协议栈流程示意图:
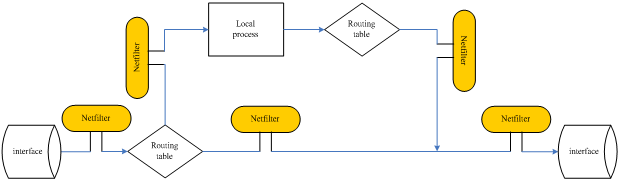
图2-3 加入netfilter的ip协议栈流程示意图
由图2-3我们可以看到共有5个挂载点(hook点)。每一个挂载点,都会指定一个唯一的hook类型,它们是(图2-3由左至右):
(1)nf_inet_pre_routing ,在完整性校验之后,选路确定之前;
(2)nf_inet_local_in , 在路由确定之后,且数据包的目的是本地主机;
(3)nf_inet_forward , 目的地是其它主机地数据包;
(4)nf_inet_local_out ,来自本机进程的数据包在其离开本地主机的过程中;
(5)nf_inet_post_routing ,在数据包离开本地主机“上线”之前。
hook类型决定了在不同的hook点上,所调用的hook处理函数。后续的讲解中,我们将看到这一点。
通过第2节讲解,我们已经成功将ip数据包引入到netfilter中。本节我们将进一步挖掘netflter内部对数据包的处理机制。在正式开始之前,我们先对netfilter中几个关键的名称和关键的数据结构做一个简单介绍。
3.1 netfilter中几个常用名称解释
(1)target,规则匹配后的处理方法。
一般将target分为两类,一类为标准的target,即下面的宏定义:
nf_drop , 丢弃该数据包;
nf_accept , 保留该数据包;
nf_stolen,忘掉该数据包;
nf_queue , 将该数据包插入到用户空间;
nf_repeat, 再次调用该hook函数。
另一类为由模块扩展的target:reject 、log、ulog、tos 、dscp、mark、redirect、masquerade、netmap、trigger等等。
(2)chain,相同类型的hook的所有操作以优先级升序排列所组成的链表。
(3)match,匹配方式。
和target类似,也将match分为两类,一类是标准的match,如:
interface,匹配网络接口(iptables设置中使用-i参数);
ip address,匹配网络地址(iptables设置中使用-d参数);
protocol,匹配数据包协议类型(-p参数)。
另一类是有模块延伸出来的匹配:tcp协议高级匹配、udp协议高级匹配、mac address 匹配,multiport匹配、匹配包的mark值、owner匹配、ip范围匹配、包的状态匹配、ah和esp协议的spi值匹配、pkttype匹配、(mtu)匹配、limit特定包的重复率匹配、recent,特定包重复率匹配、ip报头中的tos值匹配、匹配包中的数据内容等等。
(4)table,netfilter中规则都存放在此结构中。table是netfilter的核心结构,后续将作重讲解其数据结构。
3.2 重要数据结构
3.2.1 xt_table与xt_table_info
xt_table是netfilter的核心数据结构,它包含了每个表的所有规则信息,以及匹配处理方法。数据包进入netfilter后通过查表,匹配相应的规则来决定对数据包的处理结果。下面是xt_table的完整定义(在x_tables.h中):
struct xt_table {
struct list_head list;
/* what hooks you will enter on */
unsigned int valid_hooks;
/* man behind the curtain... */
struct xt_table_info *private;
/* set this to this_module if you are a module, otherwise null */
struct module *me;
u_int8_t af; /* address/protocol family */
int priority; /* hook order */
/* a unique name... */
const char name[xt_table_maxnamelen];
};
每个成员意思见上文定义中的注释,个别成员说明如下:
valid_hooks,所支持的hook点类型,决定后续注册hook操作的位置。比如filter表的valid_hoos被指定为:(1 << nf_inet_local_in) | (1 << nf_inet_forward) | (1 << nf_inet_local_out)),即在nf_inet_local_in、nf_inet_forward、nf_inet_local_out三处注册hook操作;
private,xt_table的数据区,包含了所有规则和规则处理方法等信息。xt_table_info详细信息见下文。
xt_table的所有数据都存在private的成员变量中,private是结构体struct xt_table_info,其定义如下:
/* the table itself */
struct xt_table_info {
/* size per table */
unsigned int size;
/* number of entries: fixme. --rr */
unsigned int number;
/* initial number of entries. needed for module usage count */
unsigned int initial_entries;
/* entry points and underflows */
unsigned int hook_entry[nf_inet_numhooks];
unsigned int underflow[nf_inet_numhooks];
/*
* number of user chains. since tables cannot have loops, at most
* @stacksize jumps (number of user chains) can possibly be made.
*/
unsigned int stacksize;
unsigned int __percpu *stackptr;
void ***jumpstack;
/* ipt_entry tables: one per cpu */
/* note : this field must be the last one, see xt_table_info_sz */
void *entries[1];
};
重要成员说明:
hook_entry, 不同hook点的规则的偏移量;
entries, 规则存储的入口,为可变区域,必须放在结构末尾。entries本质上是ipt_entry结构。关于ipt_entry定义和成员介绍见下文。
3.2.2 ipt_entry
ipt_entry结构是对规则的描述,其定义如下:
/* this structure defines each of the firewall rules. consists of 3
parts which are 1) general ip header stuff 2) match specific
stuff 3) the target to perform if the rule matches */
struct ipt_entry {
struct ipt_ip ip;
/* mark with fields that we care about. */
unsigned int nfcache;
/* size of ipt_entry matches */
u_int16_t target_offset;
/* size of ipt_entry matches target */
u_int16_t next_offset;
/* back pointer */
unsigned int comefrom;
/* packet and byte counters. */
struct xt_counters counters;
/* the matches (if any), then the target. */
unsigned char elems[0];
};
成员elems中,保存了一条规则的所有匹配(matchs),以及匹配后的处理操作(target)。在iptables.c中,generate_entry()方法新建一个ipt_entry,可以看到如何将matchs和target添加到ipt_entry中的:
static struct ipt_entry *
generate_entry(const struct ipt_entry *fw,
struct xtables_rule_match *matches,
struct ipt_entry_target *target)
{
unsigned int size;
struct xtables_rule_match *matchp;
struct ipt_entry *e;
size = sizeof(struct ipt_entry);
for (matchp = matches; matchp; matchp = matchp->next)
size = matchp->match->m->u.match_size;
e = xtables_malloc(size target->u.target_size);
*e = *fw;
e->target_offset = size;
e->next_offset = size target->u.target_size;
size = 0;
for (matchp = matches; matchp; matchp = matchp->next) {
memcpy(e->elems size, matchp->match->m, matchp->match->m->u.match_size);
size = matchp->match->m->u.match_size;
}
memcpy(e->elems size, target, target->u.target_size);
return e;
见上文的程序片段,ipt_entry的空间占用为:ipt_entry结构自身的size,加之所有match的size总和,加之target的size。填写elems时,首先将所有的match依次拷贝到elems指向的存储位置,紧接着将target拷贝到其后。下图是ipt_entry存储示意图:
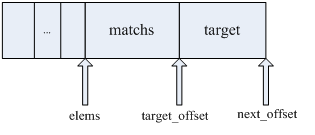
图3-1 ipt_entry存储分布示意图
3.2.3 nf_hook_ops
nf_hook_ops用于注册一个hook操作,它主要包含了hook操作执行函数、hook类型,以及优先级。我们可以认为,一个nf_hook_ops表征了一个表的一条链,因为它与一个表的一个hook类型唯一对应。其完整定义如下:
struct nf_hook_ops {
struct list_head list;
/* user fills in from here down. */
nf_hookfn *hook;
struct module *owner;
u_int8_t pf;
unsigned int hooknum;
/* hooks are ordered in ascending priority. */
int priority;
};
重要成员说明:
hook,hook操作函数;
owner,所属的表;
hooknum,hook类型;
priority,优先级,决定同一hook点,链(不同表在同一个hook点的链)的执行次序。
3.3 表注册与扩展机制
在3.2节中,我们了解了一些与表相关的重要数据结构。本节我们详细讨论在netfilter中,这些数据结构是如何整合,注册提交到系统中的。为了讨论方便,我们以常见的filter表为例,讲解表的注册过程。
3.3.1 netfilter表注册过程
(1)初始化表结构
每一个“表”,都是xt_table的一个实例。首先iptable_filter模块初始化时注册一个packet_filter表:
static const struct xt_table packet_filter = {
.name = "filter",
.valid_hooks = filter_valid_hooks,
.me = this_module,
.af = nfproto_ipv4,
.priority = nf_ip_pri_filter,
};
其中,filter_valid_hooks指定了filter所支持挂载的hook点(支持nf_inet_local_in,nf_inet_forward,nf_inet_local_out三种hook类型),定义如下:
#define filter_valid_hooks ((1 << nf_inet_local_in) | \
(1 << nf_inet_forward) | \
(1 << nf_inet_local_out))
(2)注册hook操作
在iptable_filter模块中,实现了iptable_filter_hook()方法作为该模块所有hook操作函数。在模块初始化时,调用xt_hook_link()方法将hook操作函数注册到系统中:
static int __init iptable_filter_init(void)
{
int ret;
if (forward < 0 || forward > nf_max_verdict) {
pr_err("iptables forward must be 0 or 1\n");
return -einval;
}
ret = register_pernet_subsys(&iptable_filter_net_ops);
if (ret < 0)
return ret;
/* register hooks */
filter_ops = xt_hook_link(&packet_filter, iptable_filter_hook);
if (is_err(filter_ops)) {
ret = ptr_err(filter_ops);
goto cleanup_table;
}
return ret;
cleanup_table:
unregister_pernet_subsys(&iptable_filter_net_ops);
return ret;
}
xt_hook_link()分别为filter表的每一个hook类型绑定hook操作函数和hook优先级(填充一个nf_hook_ops实例),然后调用nf_register_hooks()方法将所有nf_hook_ops注册到系统中。程序片段如下:
for (i = 0, hooknum = 0; i < num_hooks && hook_mask != 0;
hook_mask >>= 1, hooknum) {
if (!(hook_mask & 1))
continue;
ops[i].hook = fn;
ops[i].owner = table->me;
ops[i].pf = table->af;
ops[i].hooknum = hooknum;
ops[i].priority = table->priority;
i;
}
ret = nf_register_hooks(ops, num_hooks);
最后nf_register_hooks()调用nf_register_hook()将filter表所有nf_hook_ops添加到全局变量nf_hooks中。hook注册过程函数调用关系如下:
xt_hook_link() -> nf_register_hooks() -> nf_register_hook(), 将每一条nf_hook_ops信息添加到nf_hooks全局变量的对应协议族类型、hook类型的list中。
(3) 表注册
与hook注册类似,在iptable_filter模块初始化时,会调用ipt_register_table对filter表进行注册:
net->ipv4.iptable_filter =
ipt_register_table(net, &packet_filter, repl);
其中ipt_register_table会调用xt_register_table完成注册,此处不再详细说明此过程。
经过以上三步,表注册就算完成了。表注册完成后,相当于我们有了仓库,待后续各种各样的target和match注册后,通过用户空间iptables提交设置,填充filter的数据区域,filter就可以工作了。
3.3.2 netfilter扩展机制
netfilter有良好的扩展性,表现在我们自己可以自定义match、target、table等注册到系统中,实现各种丰富的功能。netfilter通过注册hook与ip协议栈关联起来,然后通过注册sockopts与用户空间关联起来(参看第4章,内核空间与用户空间的交互),使ip协议栈、netfilter、iptables(用户空间)三者贯通。在netfilter内部,通过match、target、table的注册,使netfilter功能更丰富。下图展示了netfilter的扩展机制:
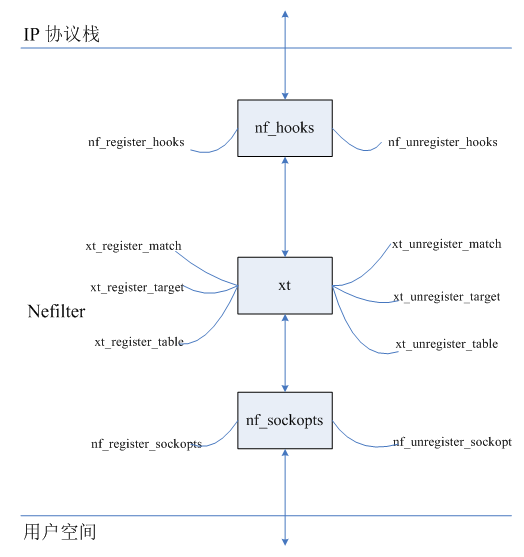
图3-2 netfilter扩展机制示意图
其中,nf_sockopts是netfilter与用户空间交互的关键,我们将在后文中讲解其原理和流程。
3.4 netfilter内部数据包处理流程
在第二章我们成功将数据包从ip协议栈的流程中转入到netfilter中,本节我们主要讨论在netfilter内部,数据包的处理流程。回想图2-2,netfilter介入到ip协议栈,是通过nf_hook,那么我们就从nf_hook开始吧,有图有真相:
图3-3 netfilter内部数据包处理流程
见上图,nf_iterate()方法,循环处理不同table在同一个hook点注册的hook操作,可以理解为数据包经过不同表的处理。比如,如果hook点在nf_inet_pre_routing,经过nf_iterate()方法,相当于依次经过了nat表的prerouting链、raw表的prerouting链、contract表的prerouting链、mangle的prerouting链的处理(nat、raw、contract、mangle在nf_inet_pre_routing均注册hook操作)。在这里我们进一步扩展ip数据包处理流程图,加入表和链,示意图如下:

图3-4 扩展ip数据包处理流程示意图
图3-4 较为清晰的示意了数据包在链与链之间的处理流程。每条链内部,则由ipt_do_table()方法处理:依次执行每一条规则的匹配,如果匹配,则执行对应的target方法。ipt_do_table()方法源码较长,这里就不展示源码了,简要介绍其核心工作流程:
(1) 获取table的数据区
private = table->private;
(2) 获取内存中所有该table的规则信息(match和target)
table_base = private->entries[cpu];
(3) 获取指定hook类型相对应的所有规则
e = get_entry(table_base, private->hook_entry[hook]);
(4) 匹配一条规则的所有match(获取match的data,调用match方法)
xt_ematch_foreach(ematch, e) {
acpar.match = ematch->u.kernel.match;
acpar.matchinfo = ematch->data;
if (!acpar.match->match(skb, &acpar))
goto no_match;
}
(5) 获取该规则的target
t = ipt_get_target(e);
(6) 获取target的数据,执行target的target方法
verdict = t->u.kernel.target->target(skb, &acpar);
(7) 获取下一条规则,重复执行(4)、(5)、(6)各步骤。
至此,netfilter数据包处理脉络大致梳理完毕;关于match和target内部处理和实现细节,因功能不同实现不尽相同,本文不再详细讨论。在后面实践章节中,讲解了trigger内部实现,可供参考。
内核空间与用户空间的数据交互通过getsockopt和setsockopt来完成,这个两个函数用来控制相关socket文件描述符的的选项值。先来看这两个函数的原型:
set/getsockopt(2)函数的基本使用格式为:
int setsockopt(int sockfd, int proto, int cmd, void *data, int datalen)
int getsockopt(int sockfd, int proto, int cmd, void *data, int datalen)
第一个参数为socket的文件描述符,第2个参数proto是sock协议,ip raw的就用sol_socket/sol_ip等,tcp/udp socket的可用sol_socket/sol_ip/sol_tcp/sol_udp等,即高层的socket是都可以使用低层socket的命令字 的;第3个参数cmd是操作命令字,由自己定义;第4个参数是数据缓冲区起始位置指针,set操作时是将缓冲区数据写入内核,get的时候是将内核中的数 据读入该缓冲区;第5个参数数据长度。
我们可以通过扩充新的命令字段来实现特殊应用程序的内核与用户空间的数据交换,内核实现新的sockopt命令字有两类,一类是添加完整的新的协议后引入,一类是在原有协议命令集的基础上增加新的命令字。netfilter就是在原有的基础上扩展命令字,实现了内核与用户空间的数据交换。
4.1 命令字扩展与nf_sockopt_ops注册
4.1.1 命令字定义
在ip_tables.h中,netfilter定义了对sockopt命令字,定义如下:
/*
* new ip firewall options for [gs]etsockopt at the raw ip level.
* unlike bsd linux inherits ip options so you don't have to use a raw
* socket for this. instead we check rights in the calls.
*
* attention: check linux/in.h before adding new number here.
*/
#define ipt_base_ctl 64
#define ipt_so_set_replace (ipt_base_ctl)
#define ipt_so_set_add_counters (ipt_base_ctl 1)
#define ipt_so_set_max ipt_so_set_add_counters
#define ipt_so_get_info (ipt_base_ctl)
#define ipt_so_get_entries (ipt_base_ctl 1)
#define ipt_so_get_revision_match (ipt_base_ctl 2)
#define ipt_so_get_revision_target (ipt_base_ctl 3)
#define ipt_so_get_max ipt_so_get_revision_target
在iptables中,通过这些命令字使用setsockopt来更新用户空间提交,或者返回当前设置给用户空间,用于搜索或查询。例如,iptables向内核提交规则时:
ret = setsockopt(handle->sockfd, tc_ipproto, so_set_replace, repl,
sizeof(*repl) repl->size);
其中,so_set_replace 就是上面定义的ipt_so_set_replace,只不过在libip4tc.h中被重命名:
#define so_set_replace ipt_so_set_replace
4.1.2 nf_sockopt_ops结构介绍
与命令字配套的还有其对应的处理方法。netfilter维护一个nf_sockopt_ops结构,在netfilter初始的时候,将其注册到系统中(添加到全局变量nf_sockopts中),其中包含了set方法,是处理用户空间传入的数据,get方法返回请求数据给iptables。nf_sockopt_ops完整定义如下:
struct nf_sockopt_ops {
struct list_head list;
u_int8_t pf;
/* non-inclusive ranges: use 0/0/null to never get called. */
int set_optmin;
int set_optmax;
int (*set)(struct sock *sk, int optval, void __user *user, unsigned int len);
#ifdef config_compat
int (*compat_set)(struct sock *sk, int optval,
void __user *user, unsigned int len);
#endif
int get_optmin;
int get_optmax;
int (*get)(struct sock *sk, int optval, void __user *user, int *len);
#ifdef config_compat
int (*compat_get)(struct sock *sk, int optval,
void __user *user, int *len);
#endif
/* use the module struct to lock set/get code in place */
struct module *owner;
};
4.1.3 nf_sockopt_ops初始化与注册
在ip_tables.c中,初始化一个nf_sockopt_ops 结构,指定其set操作函数为do_ipt_set_ctl()方法,get操作函数为do_ipt_get_ctl()方法,代码如下:
static struct nf_sockopt_ops ipt_sockopts = {
.pf = pf_inet,
.set_optmin = ipt_base_ctl,
.set_optmax = ipt_so_set_max 1,
.set = do_ipt_set_ctl,
#ifdef config_compat
.compat_set = compat_do_ipt_set_ctl,
#endif
.get_optmin = ipt_base_ctl,
.get_optmax = ipt_so_get_max 1,
.get = do_ipt_get_ctl,
#ifdef config_compat
.compat_get = compat_do_ipt_get_ctl,
#endif
.owner = this_module,
};
关于do_ipt_set_ctl()方法的功能和具体实现,我们后面在详细说明。
随后,在模块初始化的时候,调用nf_register_sockopt()方法,将ipt_sockopts添加到nf_sockopts全局变量中:
/* register setsockopt */
ret = nf_register_sockopt(&ipt_sockopts);
4.2 iptables规则提交过程
在iptables的main方法中,处理用户输入(do_command方法),将结果封装在iptc_handle结构中,然后通过iptc_commit方法,提交到内核:
ret = do_command(argc, argv, &table, &handle);
if (ret) {
ret = iptc_commit(handle);
iptc_free(handle);
}
iptc_commit又调用setscokopt方法,以so_set_replace命令字向内核提交:
ret = setsockopt(handle->sockfd, tc_ipproto, so_set_replace, repl,
sizeof(*repl) repl->size);
iptc_commit内函数调用如下图:
图4-1 规则提交函数调用示意图
上图中,从setsockopt()到ip_setsockopt()是常规的setsockopt调用流程;在新的流程中,netfilter加入的自己的处理函数——nf_setsockopt()。nf_setsockop()调用nf_sockopt(),从nf_sockopts全局变量中,查找与命令字相匹配的nf_sockopt_ops(初始化时注册的),然后执行nf_sockopt_ops注册的set函数。代码片段如下:
/* call get/setsockopt() */
static int nf_sockopt(struct sock *sk, u_int8_t pf, int val,
char __user *opt, int *len, int get)
{
struct nf_sockopt_ops *ops;
int ret;
ops = nf_sockopt_find(sk, pf, val, get);
if (is_err(ops))
return ptr_err(ops);
if (get)
ret = ops->get(sk, val, opt, len);
else
ret = ops->set(sk, val, opt, *len);
module_put(ops->owner);
return ret;
}
在4.1.3节中,我们讲到nf_sockopt_ops初始化的时候,注册的set操作函数是do_ipt_set_ctl(), 源码如下:
static int
do_ipt_set_ctl(struct sock *sk, int cmd, void __user *user, unsigned int len)
{
int ret;
if (!capable(cap_net_admin))
return -eperm;
switch (cmd) {
case ipt_so_set_replace:
ret = do_replace(sock_net(sk), user, len);
break;
case ipt_so_set_add_counters:
ret = do_add_counters(sock_net(sk), user, len, 0);
break;
default:
duprintf("do_ipt_set_ctl: unknown request %i\n", cmd);
ret = -einval;
}
return ret;
}
do_replace()方法复制用户空间数据到内核空间,并对其做一些必要检查,然后调用__do_replace()保存到对应的table中:
static int
do_replace(struct net *net, const void __user *user, unsigned int len)
{
int ret;
struct ipt_replace tmp;
struct xt_table_info *newinfo;
void *loc_cpu_entry;
struct ipt_entry *iter;
// 复制用户空间数据到内核
if (copy_from_user(&tmp, user, sizeof(tmp)) != 0)
return -efault;
/* overflow check */
if (tmp.num_counters >= int_max / sizeof(struct xt_counters))
return -enomem;
tmp.name[sizeof(tmp.name)-1] = 0;
newinfo = xt_alloc_table_info(tmp.size);
if (!newinfo)
return -enomem;
/* choose the copy that is on our node/cpu */
loc_cpu_entry = newinfo->entries[raw_smp_processor_id()];
// 将用户空间传入的数据中的规则部分复制到newinfo的entries中
if (copy_from_user(loc_cpu_entry, user sizeof(tmp),
tmp.size) != 0) {
ret = -efault;
goto free_newinfo;
}
// 对用户空间的数据进行检查,同时为每个cpu做一份copy
ret = translate_table(net, newinfo, loc_cpu_entry, &tmp);
if (ret != 0)
goto free_newinfo;
duprintf("translated table\n");
// 查找所属表,将newinfo(包含用户空间提交的规则)替换到对应的表
// 的数据区中。
ret = __do_replace(net, tmp.name, tmp.valid_hooks, newinfo,
tmp.num_counters, tmp.counters);
if (ret)
goto free_newinfo_untrans;
return 0;
free_newinfo_untrans:
xt_entry_foreach(iter, loc_cpu_entry, newinfo->size)
cleanup_entry(iter, net);
free_newinfo:
xt_free_table_info(newinfo);
return ret;
}
iptables获取规则信息的过程,与上面所述的提交流程基本一致,所以不再花费篇幅去讲解了。
目标(target)是防火墙规则策略中的结果部分,定义对数据包要进行如何处理,如接受、丢弃、修改、继续等。在具体实现时分为两部分,内核部分和用户空间部分:内核中是以netfilter的扩展模块实现,定义该模块并将其挂接到netfilter的目标链表中后,在内核进行目标检测时自动根据目标名称查找该模块而调用相应的目标函数,完成真正的目标功能。在用户空间,目标模块是作为iptables的一个扩展动态库来实现(android中使用静态库),只是一个用户接 口,不完成实际目标功能,完成接收用户输入并将目标数据结构传递到内核的功能,该库的名称有限制,必须为libipt_xxx.so,其中“xxx”是该 目标的名字,为区别于匹配,通常目标的名称一般都是用大写。
本章围绕着如何在现有的netfilter/iptables框架中,添加trigger支持,实现端口触发的功能。本文实践是在tr781项目(android平台)中,内核版本3.0,iptables版本1.4;不同版本在实现细节上略有差异(包括编译),请读者注意。
5.1 trigger内核模块
5.1.1 主要数据结构介绍
首先,需要定义目标模块的数据结构,用来描述目标条件。
我们新建ipt_trigger.h(添加路径:kernel/include/linux/netfilter_ipv4/),添加trigger目标模块的数据结构ipt_trigger_info。代码如下:
#define trigger_timeout 600 /* 600 secs */
enum ipt_trigger_type
{
ipt_trigger_dnat = 1,
ipt_trigger_in = 2,
ipt_trigger_out = 3
};
struct ipt_trigger_ports {
u_int16_t mport[2]; /* related destination port range */
u_int16_t rport[2]; /* port range to map related destination port range to */
};
struct ipt_trigger_info {
enum ipt_trigger_type type;
u_int16_t proto; /* related protocol */
struct ipt_trigger_ports ports;
};
然后,定义内核模块处理,最主要的是定义一个xt_target目标结构,用于向系统注册。
xt_target结构在include/linux/netfilter/x_tables.h中定义(注:2.6内核该数据结构与3.0内核不一致,但主体大致相同;同时,该结构的名称和定义的位置也有差异):
/* registration hooks for targets. */
struct xt_target {
structlist_head list;
const char name[xt_extension_maxnamelen];
u_int8_t revision;
/* returns verdict. argument order changed since 2.6.9, as this
must now handle non-linear skbs, using skb_copy_bits and
skb_ip_make_writable. */
unsigned int (*target)(struct sk_buff *skb,
const struct xt_action_param *);
/* called when user tries to insert an entry of this type:
hook_mask is a bitmask of hooks from which it can be
called. */
/* should return 0 on success or an error code otherwise (-exxxx). */
int (*checkentry)(const struct xt_tgchk_param *);
/* called when entry of this type deleted. */
void (*destroy)(const struct xt_tgdtor_param *);
#ifdef config_compat
/* called when userspace align differs from kernel space one */
void (*compat_from_user)(void *dst, const void *src);
int (*compat_to_user)(void __user *dst, const void *src);
#endif
/* set this to this_module if you are a module, otherwise null */
struct module *me;
const char *table;
unsigned int targetsize;
#ifdef config_compat
unsigned int compatsize;
#endif
unsigned int hooks;
unsigned short proto;
unsigned short family;
};
重要成员介绍:
list:用来挂接到目标链表,必须初始化为{null, null};
name:该目标名称的名称,必须是唯一的;
checkentry函数:用于对用户层传入的数据进行合法性检查,如目标数据长度是否正确,是否是在正确的表中使用等;
destroy函数:用于释放该目标中动态分配的资源,在规则删除时会调用;
target 函数:该函数是最主要函数,完成对数据包的策略处理,包括对包中的数据进行修改,函数返回结果可能是nf_accept(接受),nf_drop(丢弃) ,nf_stolen(偷窃,指该包处理由该目标接管,不再由系统网络栈处理),ipt_continue(继续,继续按后面的规则对该包进行检查)等;
hooks:指定target适用的链。
5.1.2 trigger初始化与注册
trigger目标结构定义如下:
static struct xt_target ipt_trigger_target = {
.name = "trigger",
.family = nfproto_ipv4,
.target = trigger_target,
.targetsize = sizeof(struct ipt_trigger_info),
.hooks = (1 << nf_inet_local_in) | (1 << nf_inet_forward)
(1 << nf_inet_local_out) | (1 << nf_inet_pre_routing),
.checkentry = trigger_check,
.me = this_module,
};
trigger_target为该模块的核心处理函数,完成trigger的基础功能(后文单独介绍此函数);trigger_check对用户空间提交的数据进行检查。值得注意的是,checkentry函数的返回值的意义内核2.6和内核3.0定义不一致。前者用1表示正常,0表示检查出错;后者用0表示正常,负值表示检查出错,大于0表示检测异常,返回i/o错误。
最后,在模块初始化函数中要调用xt_register_target()函数将一个xt_target目标结构挂接到系统目标链表中,在模块的结束函数中调用xt_unregister_target()函数将目标结构从目标链表中去除。代码如下:
static int __init init(void)
{
int ret;
debugp(" lqt === 7777\n");
ret = xt_register_target(&ipt_trigger_target);
debugp(" init ret:%d\n", ret);
return ret;
}
static void __exit fini(void)
{
xt_unregister_target(&ipt_trigger_target);
}
module_init(init);
module_exit(fini);
target注册与table注册很类似(3.3节的表注册):实现一个标准结构,然后调用相关函数注册到系统中。
5.1.3 主要函数介绍
注:本节主要介绍trigger实现端口触发的原理(核心函数),如果对此不感兴趣,可以越过本小结。
在trigger实现中,维护了一个ipt_trigger的数据结构链表(trigger_list,全局的)来记录端口触发的情况,每一个触发记录记载着触发的源ip地址,触发指向的目的地址,触发的协议类型,触发的端口范围,打开的协议类型,打开的端口范围,定时器等。ipt_trigger定义如下:
struct ipt_trigger {
struct list_head list; /* trigger list */
struct timer_list timeout; /* timer for list destroying */
u_int32_t srcip; /* outgoing source address */
u_int32_t dstip; /* outgoing destination address */
u_int16_t mproto; /* trigger protocol */
u_int16_t rproto; /* related protocol */
struct ipt_trigger_ports ports; /* trigger and related ports */
u_int8_t reply; /* confirm a reply connection */
};
trigger_target作为trigger处理的函数入口,根据传入的trigger-type不同,分别交予trigger_out,trigger_in,trigger_dnat三个方法各种处理。trigger_target定义如下:
static unsigned int
trigger_target(struct sk_buff *skb, const struct xt_action_param *param)
{
const struct ipt_trigger_info *info = param->targinfo;
const struct iphdr *iph = ip_hdr(skb);
debugp("%s: type = %s\n", __function__,
(info->type == ipt_trigger_dnat) ? "dnat" :
(info->type == ipt_trigger_in) ? "in" : "out");
/* the port-trigger only supports tcp and udp. */
if ((iph->protocol != ipproto_tcp) && (iph->protocol != ipproto_udp))
return xt_continue;
if (info->type == ipt_trigger_out)
return trigger_out(skb, param);
else if (info->type == ipt_trigger_in)
return trigger_in(skb, param);
else if (info->type == ipt_trigger_dnat)
return trigger_dnat(skb, param);
return xt_continue;
}
其中,skb是数据包,xt_action_param封装着ipt_trigger_info信息和hooknum等信息。xt_acton_param数据结构(该结构内核2.6和3.0略有差异),如下:
/**
* struct xt_action_param - parameters for matches/targets
*
* @match: the match extension
* @target: the target extension
* @matchinfo: per-match data
* @targetinfo: per-target data
* @in: input netdevice
* @out: output netdevice
* @fragoff: packet is a fragment, this is the data offset
* @thoff: position of transport header relative to skb->data
* @hook: hook number given packet came from
* @family: actual nfproto_* through which the function is invoked
* (helpful when match->family == nfproto_unspec)
*
* fields written to by extensions:
*
* @hotdrop: drop packet if we had inspection problems
* network namespace obtainable using dev_net(in/out)
*/
struct xt_action_param {
union {
const struct xt_match *match;
const struct xt_target *target;
};
union {
const void *matchinfo, *targinfo;
};
const struct net_device *in, *out;
int fragoff;
unsigned int thoff;
unsigned int hooknum;
u_int8_t family;
bool hotdrop;
};
5.1.3.1 trigger_out
为了便于理解,我们看一条trigger使用的iptables设置实例:
iptables -a forward -i br0 -p tcp –j trigger –trigger-type out –trigger-proto tcp –trigger-match 80-80 –trigger-relate 21-21
当数据包流经filter表的forward链时,如果满足数据包来自接口br0、协议类型为tcp,则交由trigger对数据包进行处理:调用trigger的trigger_target方法,传入数据包(skb)和ipt_trigger_info(记录着trigger-type,trigger-proto,tirgger-match,trigger-relate等信息,被封装在param中)。
trigger_out 依据传入数据包的协议类型和端口号,以及打开端口的范围,在trigger_list中遍历,如果有满足条件的记录(数据包的端口包含在记录触发端口范围内,打开端口包含在记录打开端口范围内,数据包协议类型与记录的触发协议类型相同),则更新该记录的timer;否则,添加一条新记录到trigger_list中,同时为此新记录添加一条timer到timer_list中。代码如下:
static unsigned int
trigger_out(struct sk_buff *skb,
const struct xt_action_param *param) // [tanliyong] xt_target_param to xt_action_param
{
const struct ipt_trigger_info *info = param->targinfo;
struct ipt_trigger trig, *found;
const struct iphdr *iph = ip_hdr(skb);
struct tcphdr *tcph = (void *)iph iph->ihl*4; /* might be tcp, udp */
debugp("%s: \n", __function__);
/* if the pkt's dst port is not in the range of match ports
* nothing happened.
*/
if (info->ports.mport[0] > ntohs(tcph->dest) ||
info->ports.mport[1] < ntohs(tcph->dest))
return xt_continue;
debugp("############# %s ############\n", __function__);
/* check if the trigger range has already existed in 'trigger_list'. */
found = list_find(&trigger_list, trigger_out_matched,
struct ipt_trigger *, iph->protocol, ntohs(tcph->dest), info->ports.rport);
if (found) {
/* yeah, it exists. we need to update(delay) the destroying timer. */
trigger_refresh(found, trigger_timeout * hz);
/* in order to allow multiple hosts use the same port range, we update
the 'saddr' after previous trigger has a reply connection. */
if (found->reply)
found->srcip = iph->saddr;
}
else {
/* create new trigger */
memset(&trig, 0, sizeof(trig));
trig.srcip = iph->saddr;
trig.mproto = iph->protocol;
trig.rproto = info->proto;
memcpy(&trig.ports, &info->ports, sizeof(struct ipt_trigger_ports));
// add new trig only when the packet's dst port is in the range of mports
if (info->ports.mport[0] <= ntohs(tcph->dest) &&
info->ports.mport[1] >= ntohs(tcph->dest))
// end of added code
add_new_trigger(&trig); /* add the new 'trig' to list 'trigger_list'. */
}
return xt_continue; /* we don't block any packet. */
}
5.1.3.2 trigger_dnat
首先,我们先看一条trigger 做dnat的iptables设置:
iptables -t nat -a prerouting -d $wanip -j trigger --trigger-type dnat
在prerouting链中,目标地址为$wanip 的数据包将交由trigger处理,指定处理类型为dnat。
在trigger_dnat方法中,依据数据包的协议类型和端口号在trigger_list中搜索,如果满足:(1)数据包协议类型与记录的打开类型一致,(2)数据包端口在记录的打开端口范围内,则对该数据包做dnat操作,目的地址为记录的触发源ip地址。
5.1.3.3 trigger_in
同样,先看一条iptables设置:
iptables -a forward -j trigger --trigger-type in
在forward链上,如果数据包的协议类型和端口满足:(1)数据包协议类型与trigger_list中记录的打开协议类型一致,(2)数据包端口在记录的打开端口范围内,则accept该数据包,否则继续后续规则处理。
5.1.4 内核目标模块编译
注意:本文实践是在android平台上,其他平台不尽相同,请读者留意。
编译trigger模块,完成以下几步即可:
(1) 实现ipt_trigger.c,置于android_root/kernel/net/ipv4/netfilter/下;实现ipt_trigger.h置于android_root/kernel/include/linux/netfilter_ipv4/。
(2) 修改netfilter目录下makefile,在targets部分添加 :
obj-$(config_ip_nf_target_trigger) = ipt_trigger.o
(3) 修改netfilter目录下kconfig,添加模块配置说明:
config ip_nf_target_trigger
tristate "port trigger"
depends on nf_nat
default m if netfilter_advanced=n
help
port trigger support.
to compile it as a module, choose m here. if unsure, say n.
(4) 修改kernel/arch/arm/configs/tr781-perf_defconfig,添加编译配置:
config_ip_nf_target_trigger=y
完成以上配置后,make即可(注意:如果之前编译过代码,需要切换到kernel目录,执行make mrproper清空之前的中间文件和配置,再重新编译)。
5.2 trigger用户层模块
在linux 中,iptables中的扩展目标模块是以动态库方式处理,在命令行中用“-j xxx”来使iptables调用相应的libipt_xxx.so动态库,扩展的目标代码通常在 iptables-
目标动态库的作用用于解析用户输入的目标信息,显示目标信息等功能。
android中,扩展目标模块被编译成静态库,与linux有稍许区别。只要按照libipt_xxx.c命令后置于iptables/extension下,android可以自行编译(在android.mk按照此命名方式执行通配)。
对于目标,最重要的数据结构就是struct xtables_target结构,扩展的目标程序就是要定义一个这个结构并将其挂接到iptables目标链表中,该结构定义如下:
struct xtables_target
{
/*
* abi/api version this module requires. must be first member,
* as the rest of this struct may be subject to abi changes.
*/
const char *version;
struct xtables_target *next;
const char *name;
/* revision of target (0 by default). */
u_int8_t revision;
u_int16_t family;
/* size of target data. */
size_t size;
/* size of target data relevent for userspace comparison purposes */
size_t userspacesize;
/* function which prints out usage message. */
void (*help)(void);
/* initialize the target. */
void (*init)(struct xt_entry_target *t);
/* function which parses command options; returns true if it
ate an option */
/* entry is struct ipt_entry for example */
int (*parse)(int c, char **argv, int invert, unsigned int *flags,
const void *entry,
struct xt_entry_target **targetinfo);
/* final check; exit if not ok. */
void (*final_check)(unsigned int flags);
/* prints out the target iff non-null: put space at end */
void (*print)(const void *ip,
const struct xt_entry_target *target, int numeric);
/* saves the targinfo in parsable form to stdout. */
void (*save)(const void *ip,
const struct xt_entry_target *target);
/* pointer to list of extra command-line options */
const struct option *extra_opts;
/* new parser */
void (*x6_parse)(struct xt_option_call *);
void (*x6_fcheck)(struct xt_fcheck_call *);
const struct xt_option_entry *x6_options;
/* ignore these men behind the curtain: */
unsigned int option_offset;
struct xt_entry_target *t;
unsigned int tflags;
unsigned int used;
unsigned int loaded; /* simulate loading so options are merged properly */
};
xtables_target结构部分成员说明如下:
next:目标链表的下一个,目标链表是一个单向链表;
name:目标的名称,必须是唯一的;
version:iptables的版本;
size:目标结构的数据长度;
userspacesize:用于目标部分的数据长度,通常此值等于size,但某些情况可能会小于size
help函数:打印帮助信息,当 "-j xxx -h"时调用;
init函数:初始化函数,可对目标结构赋初值;
parse函数:解析用户输入参数,这是最主要的处理函数;
final_check函数:对用户数据进行最后的检查;
print函数:打印目标信息,iptables -l时调用
save函数:保存当前iptables规则时打印目标格式,被iptables-save程序调用;
extra_opts:选项信息,选项格式是标准的unix选项格式,通过getopt函数识
option_offset:选项偏移;
t:指向iptables规则;
tflags:规则相关标志
used: 模块使用计数。
libipt_trigger.c函数就是填写structxtable_target结构,然后定义动态库初始化函数_init()将该结构挂接到iptables的选项链表中。其他函数程序比较简单,不再一一列举。trigger的xtable_target如下(为了保证数据一致,沿用内核模块定义的ipt_trigger_info):
struct xtables_target trigger
= {
.next = null,
.name = "trigger",
.version = xtables_version,
.size = xt_align(sizeof(struct ipt_trigger_info)),
.userspacesize = xt_align(sizeof(struct ipt_trigger_info)),
.help = help,
.init = init,
.parse = parse,
.final_check = final_check,
.print = print,
.save = save,
.extra_opts = opts
};
调用xtables_register_target方法将trigger注册到系统中:
void _init(void)
{
xtables_register_target(&trigger);
}
netfilter/iptables在网络配置和网络安全中,提供了便捷、实用服务,在linux(android)系统中应该较为广泛。本文旨在梳理netfilter/iptables框架脉络,让读者对netfilter/iptables的实现原理、工作流程有概括性的认识。如果想了解netfilter/iptables更多实现细节,可以参看:;该文档从代码的角度,对netfilter实现有比较细致的说明。
netfilter/iptables中,有两条重要纽带:其一,nf_hooks(其本质是nf_hook_ops结构的一个链表),用于hook操作注册,将netfilter与协议栈关联起来;其二,nf_sockopts(其本质是nf_sockopt_ops结构的一个链表),用于get/setscokopt操作注册,将netfilter与用户空间(iptables)关联起来。netfilter的核心——表,所有功能的实际执行都是在表中完成的。这里重新概括netfilter/iptables执行步骤:
第一步,系统初始化时,初始化所有的table、match、target,并注册到系统中。注册完成后,我们就有了真正的执行体了。
第二步,table初始化时,注册hook操作,将netfilter与协议栈关联起来。
第三步,系统初始化时,注册get/setsockopt操作,将netfilter与iptables关联起来。
第四步,用户通过iptables设置规则,并提交到内核(在第三步基础上),这样就将特定的table、match、target关联起来。
第五步,数据包在协议栈中,流经hook点时,被导入到netfilter中(在第二步基础上);通过查找表,执行对应的match,根据match的结果执行对应的target,实现对数据包的过滤,修改,跟踪等功能。
另外,本文介绍了自定义目标——trigger的实现,以此介绍目标模块的初始化、注册、执行流程。同时,为android平台上,内核移植和编译提供一些参考。
最后,本文不完善的地方是:对iptables如何处理用户输入、如何将用户输入打包成标准的数据结构等实现细节尚未梳理。待后续补充吧。