小公司研发总监,既当司令也当兵!
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
分类: linux
2015-09-16 11:36:34
概述
tcp校验和是一个端到端的校验和,由发送端计算,然后由接收端验证。其目的是为了发现tcp首部和数据在发送端到接收端之间发生的任何改动。如果接收方检测到校验和有差错,则tcp段会被直接丢弃。
tcp校验和覆盖tcp首部和tcp数据,而ip首部中的校验和只覆盖ip的首部,不覆盖ip数据报中的任何数据。
tcp的校验和是必需的,而udp的校验和是可选的。
tcp和udp计算校验和时,都要加上一个12字节的伪首部。
伪首部
伪首部共有12字节,包含如下信息:源ip地址、目的ip地址、保留字节(置0)、传输层协议号(tcp是6)、tcp报文长度(报头 数据)。伪首部是为了增加tcp校验和的检错能力:如检查tcp报文是否收错了(目的ip地址)、传输层协议是否选对了(传输层协议号)等。
定义
(1) rfc 793的tcp校验和定义
the checksum field is the 16 bit one's complement of the one's complement sum of all 16-bit words in the header and text.
if a segment contains an odd number of header and text octets to be checksummed, the last octet is padded on the right
with zeros to form a 16-bit word for checksum purposes. the pad is not transmitted as part of the segment. while computing
the checksum, the checksum field itself is replaced with zeros.
上述的定义说得很明确:
首先,把伪首部、tcp报头、tcp数据分为16位的字,如果总长度为奇数个字节,则在最后增添一个位都为0的字节。把tcp报头中的校验和字段置为0(否则就陷入鸡生蛋还是蛋生鸡的问题)。
其次,用反码相加法累加所有的16位字(进位也要累加)。
最后,对计算结果取反,作为tcp的校验和。
实现
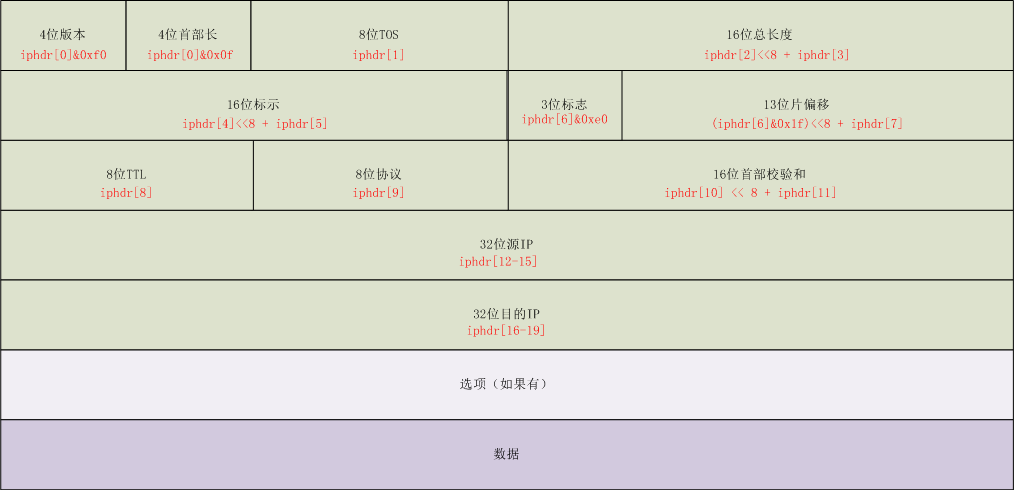
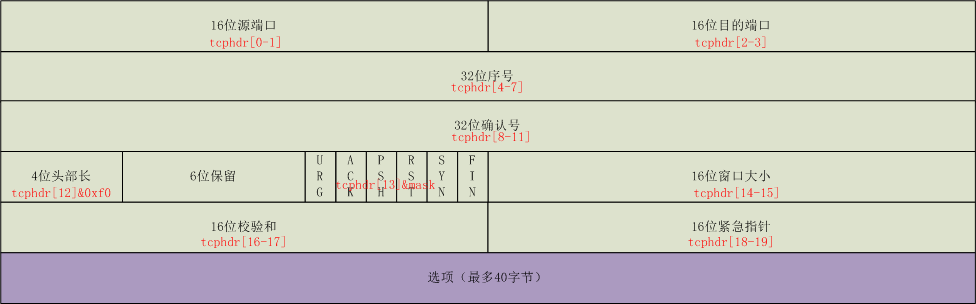
下面两图展示了ip头部和tcp头部内容和字节序号对应关系,方便后续代码阅读:
图一,ip头部
图二, tcp头部:
算法:
点击(此处)折叠或打开
-
/**********************************************************************
-
*function: computetcpchecksum
-
*
-
*arguments:
-
* iphdr -- pointer to ip header
-
* tcphdr -- pointer to tcp header
-
*
-
*returns:
-
* the computed tcp checksum
-
***********************************************************************/
-
uint16_t computetcpchecksum(unsigned char *iphdr, unsigned char *tcphdr)
-
{
-
uint32_t sum = 0;
-
-
// ip报文中长度
-
uint16_t count = iphdr[2] * 256 iphdr[3];
-
uint16_t tmp;
-
-
unsigned char *addr = tcphdr;
-
-
// 12字节伪首部
-
unsigned char pseudoheader[12];
-
-
// 计算tcp头部和数据总长度(按字节)
-
// ip报文总长度 - ip头部长度(按4字节计算) = ip负载长度(tcp总长度)
-
count -= (iphdr[0] & 0x0f) * 4;
-
-
// 复制ip头部中原地址和目的地址信息(iphdr[12-19])到伪头部中
-
memcpy(pseudoheader, iphdr12, 8);
-
-
// 伪头部填充
-
pseudoheader[8] = 0;
-
-
// ip头部中的上层协议
-
pseudoheader[9] = iphdr[9];
-
-
// 伪头部中tcp长度
-
pseudoheader[10] = (count >> 8) & 0xff;
-
pseudoheader[11] = (count & 0xff);
-
-
// 计算伪首部累加和
-
sum = * (uint16_t *) pseudoheader;
-
sum = * ((uint16_t *) (pseudoheader2));
-
sum = * ((uint16_t *) (pseudoheader4));
-
sum = * ((uint16_t *) (pseudoheader6));
-
sum = * ((uint16_t *) (pseudoheader8));
-
sum = * ((uint16_t *) (pseudoheader10));
-
-
// 计算tcp头部和数据累加和
-
while (count > 1)
-
{
-
memcpy(&tmp, addr, sizeof(tmp));
-
sum = (uint32_t) tmp;
-
addr = sizeof(tmp);
-
count -= sizeof(tmp);
-
}
-
-
// 如果tcp总长度为奇数,最后一个字节单独计算
-
if (count > 0)
-
{
-
sum = (unsigned char) *addr;
-
}
-
-
// 如果所有累加和超过16位,把进位继续类型,然后重新验证
-
// 知道累加和可以用16位表达
-
while(sum >> 16)
-
{
-
sum = (sum & 0xffff) (sum >> 16);
-
}
-
-
// 累加和取反
-
return (uint16_t) ((~sum) & 0xffff);
- }