小公司研发总监,既当司令也当兵!
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
分类: linux
2021-06-15 10:49:48
一文读懂内核spin lock接口原理及使用-凯发app官方网站
1.1
内核控制路径
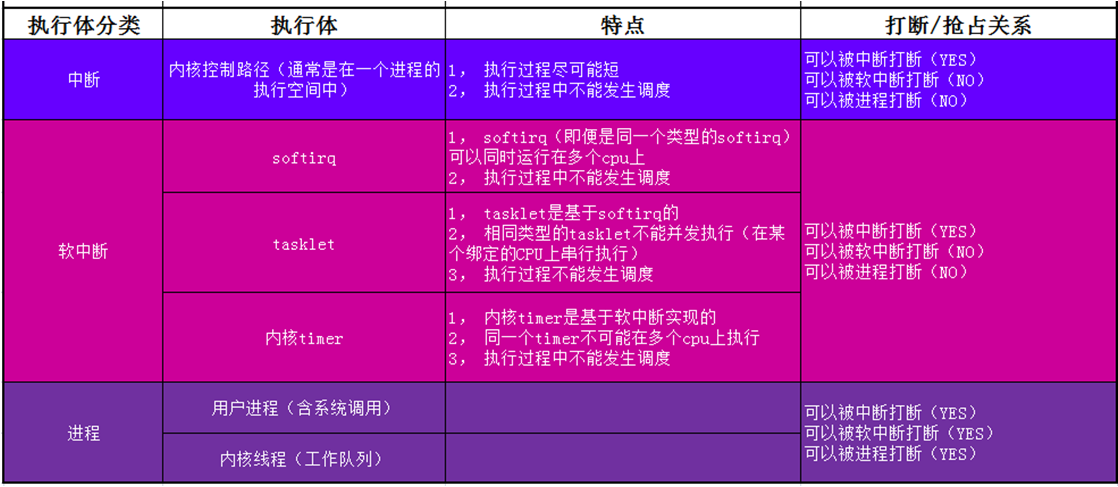
首先,申明一组术语。在内核中,cpu执行一段特定的代码或流程,我们称之为一个“内核控制路径”或“执行体”(它包括执行代码,以及执行代码所需的环境:寄存器状态,内存分配状态,中断打开/关闭状态等等)。它通常又被分为(称为):进程上下文(用户进程,内核线程,workqueue),中断上下文(硬中断,软中断)。下表是linux内核(2.6之前还有一个bh的执行体,后被软中断替代实现)的核心执行体概述:
表1-1 内核执行体
1.2 内核竞态与临界区
当多个内核控制路径,对同一个资源(共享资源)进行访问(同时有读取和修改)时,就可能存在访问一致性的问题(比如控制路径a正在修改资源v1 -> v2,控制路径b正在读取资源;这种情况b可能读取到的信息,部分是v1数据,部分是v2数据的混乱状态)。这种情况,我们称之为“存在竞争条件”,或“竞态”。
为了保障对共享资源的访问的一致性,将对存在竞态资源的访问过程,定义为“临界区”。并且规定:任何情况下,只能有一个内核控制路径,进入到一个特定的“临界区”。为了达到这个目的,内核同步被设计出来,而本文后续讲解的自旋锁,就是其中的一个实现。
1.2.1 并发执行产生的竞态
在多处理器环境中,多个内核控制路径,在不同的cpu上同步执行;如果他们之间有共享资源的访问,则很容易产生 竞态。示意入下图: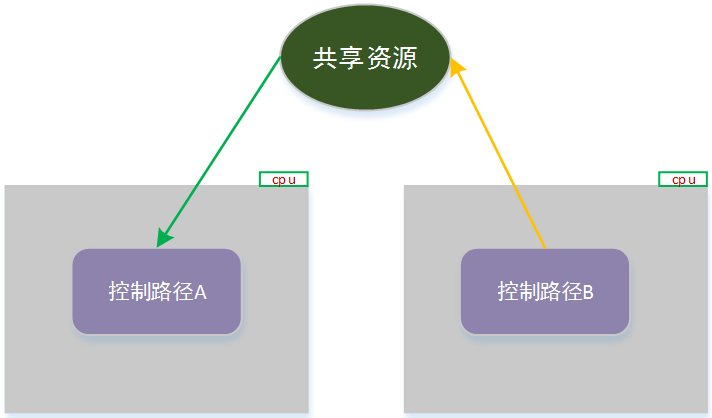
1.2.2 控制路径嵌套产生的竞态
内核控制路径嵌套,指在一个控制路径未执行完毕的情况下,当前cpu被调度运行另外一个内核控制路径。
见第一节表1-1,内核控制路径在执行过程中,是可以被其它内核控制路径所打断/抢占的;同样,如果这两条控制路径,存在对某一个共享资源的访问,也会出现“竞态”。如下图示例:
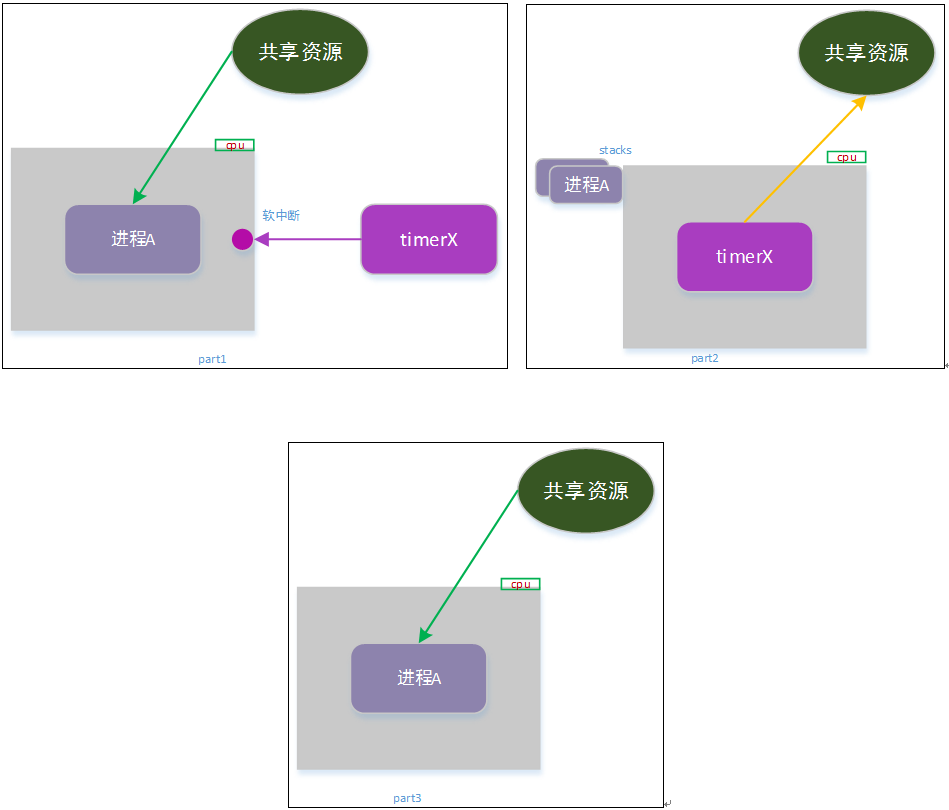
如上图所示
part1:进程a正在读取共享资源(完成部分读取),此时产生一个定时任务事件,中断了进程a;
part2:定时任务同时修改了共享资源v1 -> v2;
part3:定时任务执行完成后,恢复进程a的执行,a继续完成资源读取。
此时a读取的资源也是介于v1 和v2的混乱数据,出现了一致性问题。
注意:内核控制路径的嵌套,往往使得场景变得复杂(产生死锁的常见原因之一),在实现过程中,务必谨慎分辨是否存在控制路径嵌套,并予以处理。
结合第一节 表1-1,总结出,内核控制路径嵌套主要有以下几种情况:
1) 执行进程主动放弃cpu:主动调用schedule、sleep等函数,或调用可能引起schedlu的函数如kmalloc等;
2) 执行进程被执行进程打断:内核抢占;
3) 执行进程被软中断、硬件中断、异常打断:中断和异常;
4) 软中断执行过程中被硬件中断打断:中断(内核中,通常不考虑异常);
5) 中断执行过程中被中断打断:中断嵌套。
后续,我们将针对以上场景,说明spin_lock,spin_lock_bk,spin_lock_irq(spin_lock_irqsave)的对应使用场景和使用注意事项。
2.1 spin lock基本功能
spin lock和sem一样,是一个基本的互斥锁;与sem不同的是,spin lock在请求锁的过程中(如果没有取到),当前执行体不会休眠,而是采用忙等待。示意图如下:
也因为内核spin lock等待锁的一方是忙等待,因此,要求持锁方在处理时要尽可能的快(即,要求临界区尽可能的短)。
spin lock 为何会设计成忙等待呢?我认为,其一:sem的 机制保护临界区,实时性太差,不能满足实时性严格的使用场景;其二:在中断环境中,不能执行调度,因此sem不适用。
注意:临界区一定要控制简短,否则会极大的浪费cpu,而降低性能(spin lock持锁时间过长,也会引起内核告警)。
经过上面分析,我们可以写出my_spin_lock()的伪代码如下:
点击(此处)折叠或打开
- void my_spin_lock(locker)
- {
- while(true)
- {
- //原子接口:如果锁空闲,则转为繁忙状态,并返回true;如果当前已经是繁忙
-
//状态,则返回false。
-
- if ( try_get_lock(locker))
- //成功获取到锁
- return;
- else
- // 未取得锁,优化cpu忙查询逻辑,防止过于高频空转
- cpu_relax();
- }
- }
上面的实现,可以解决 “控制路径并发执行” 产生的竞态问题了!
但在上面的实现,可以解决“控制路径嵌套”产生的竞态问题么?
我们接下来逐一分析...
2.2 执行进程主动放弃cpu 引起的控制路径嵌套
考虑如下场景:
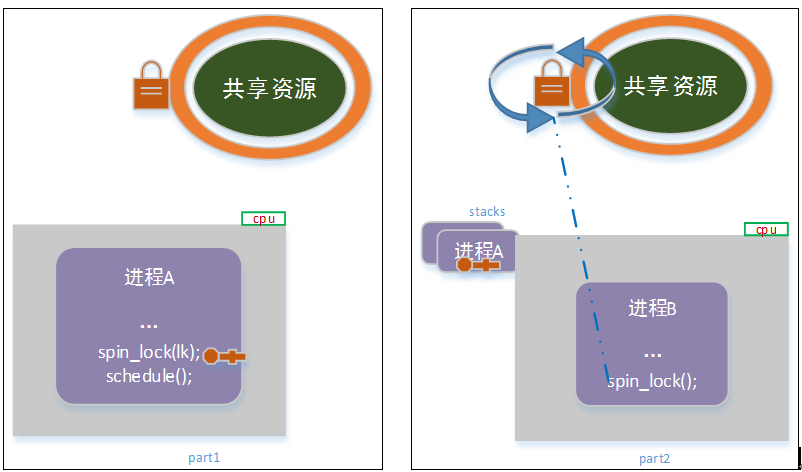
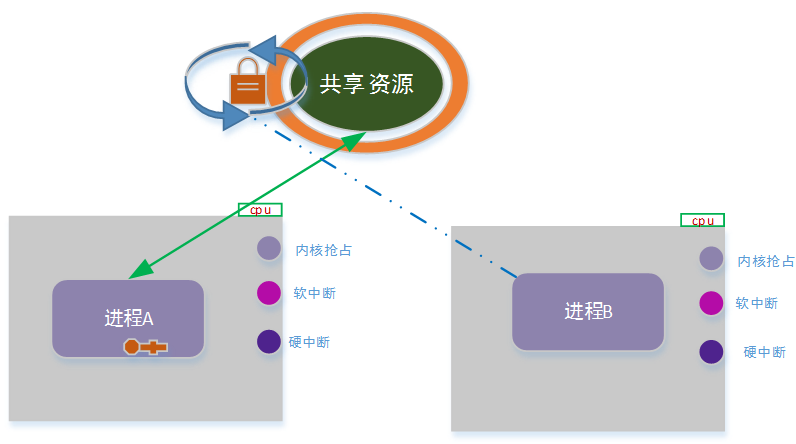
如上图示意,进程a在取得锁进入临界区后,调用了schedule主动放弃cpu;而此时,进程b被在该cpu上调度执行;进程b尝试获取共享资源锁的时候,将陷入无限循环中。
此时,进程b占有cpu资源,但无法获取锁,而陷入无穷的忙等待;进程a持有资源锁,但永远得不到调度,而无法释放锁!
这就是传说中的“死锁”!
对于这种情况,spin lock并没有给出凯发app官方网站的解决方案(系统会因为死锁而停摆,或被系统看门狗重启)。原因是,这种情况,属于业务流程上的问题,应该由开发者予以规避!
注意:上面的例子是极端情况,违背了我们开发常识:临界区内禁止调度(休眠)!但是初学者,还是很容易掉入这个陷阱里面;因为他们经常,不经意间,在临界区调用一些系统函数(比如kmalloc),而这些函数可能引起调度!在实践中,我们必须非常非常谨慎地,在临界区调用系统接口(或其他第三方模块导出的接口),除非你非常明确你正在面对什么;并且,临界区内调用自己模块的函数,都必须谨慎(在被调用的函数上做好充分的注释说明)。2.3 内核抢占引起的控制路径嵌套 (spin_lock())
考虑如下场景: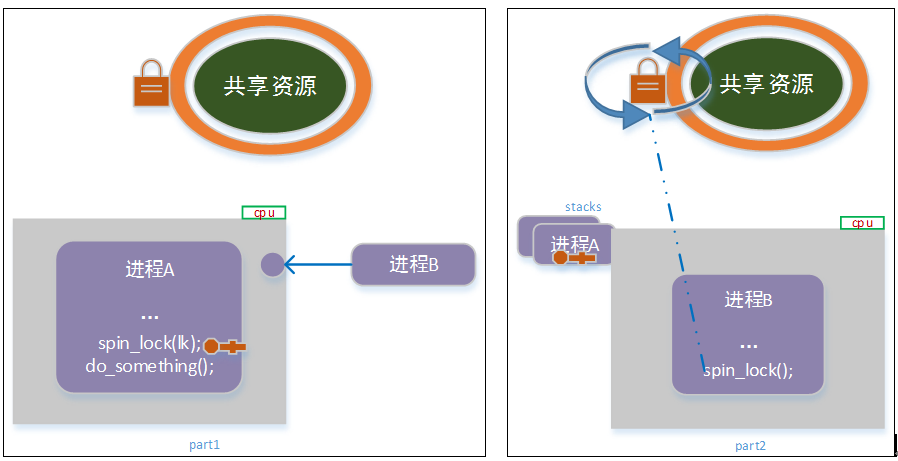
如上图所示,a进程获取锁,正在执行临界区代码;此时进程b通过内核抢占,调度到该cpu上执行;b尝试获取共享资源 spin lock锁时,产生死锁。
事实上,内核实现spin_lock()函数,在获取锁的过程中,以及进入临界区处理的过程中,是禁止本地(本cpu)的内核抢占功能。
内核spin_lock() 伪代码如下:
点击(此处)折叠或打开
-
void spin_lock(locker)
-
{
-
preempt_disable(); // 禁用内核抢占
-
while(true)
-
{
-
//原子接口:如果锁空闲,则转为繁忙状态,并返回true;如果当前已经是繁忙
-
//状态,则返回false。
-
if ( try_get_lock(locker))
-
//成功获取到锁
-
return;
-
else
-
// 未取得锁,优化cpu忙查询逻辑,防止过于高频空转
-
cpu_relax();
-
}
- }
调整后的场景如下:
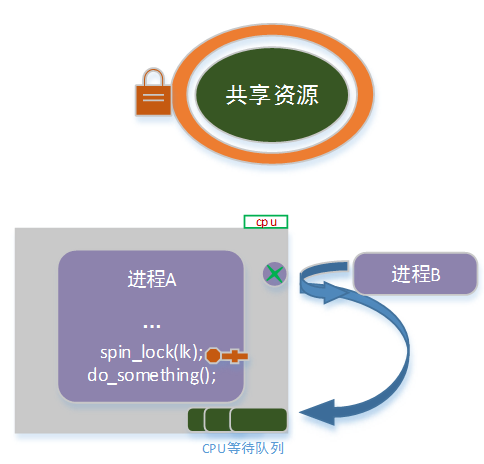
这样可以保证,进程a在访问临界区的过程中,不会被进程b抢占;从而避免形成嵌套路径造成死锁。
2.4 软中断引起的内核控制路径嵌套(spin_lock_bh())
考虑如下场景:
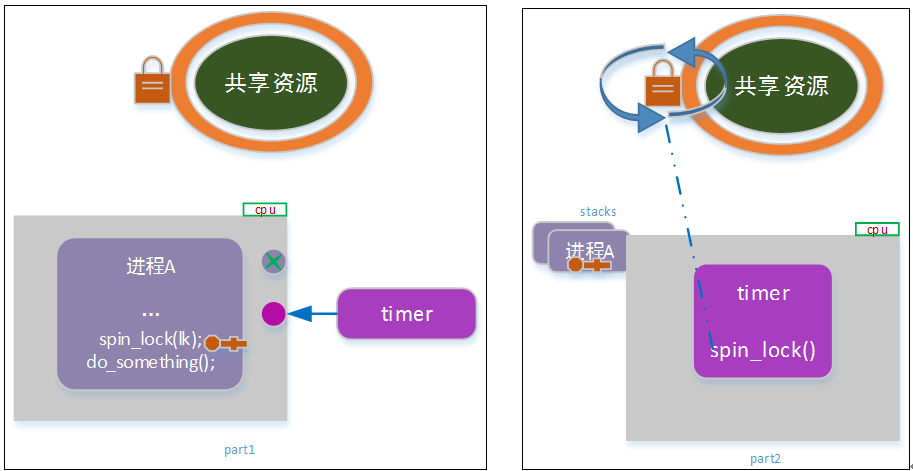
如上图,进程a持锁进入临界区,此时内核定时任务(软中断)发生,并调度到当前cpu上;timer尝试获取共享资源锁时,发生死锁。
为了避免软中断引起的内核路径嵌套导致死锁,在进入临界区之前,可以把本地(本cpu)的软中断禁止。
示意代码如下:
点击(此处)折叠或打开
-
...
-
local_bh_disable(); // 关闭本地软中断
-
spin_lock(lk);
-
do_something();
-
spin_unlock(lk);
-
local_bh_enable();
- ...
实际上,内核spin lock封装了一个快捷的接口实现该功能:spin_lock_bh()。
点击(此处)折叠或打开
-
void spin_lock_bh(locker)
-
{
-
local_bh_disable(); //关闭本地软中断
-
preempt_disable(); // 禁用内核抢占
-
while(true)
-
{
-
//原子接口:如果锁空闲,则转为繁忙状态,并返回true;如果当前已经是繁忙
-
//状态,则返回false。
-
if ( try_get_lock(locker))
-
//成功获取到锁
-
return;
-
else
-
// 未取得锁,优化cpu忙查询逻辑,防止过于高频空转
-
cpu_relax();
-
}
-
}
-
-
void spin_unlock_bh(locker)
-
{
-
put_lock(locker); //原子接口,锁状态清理到空闲状态
-
local_bh_enable(); // 使能本地软中断
-
preempt_enable(); // 使能内核抢占
- }
调整后使用场景如下:
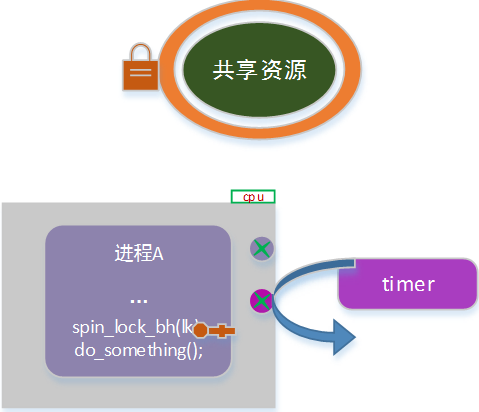
注意:关闭本地软中断后,会导致本cpu对软中断响应不及时,从而降低系统性能。因此,需要谨慎选择使用spin_lock 还是spin_lock_bh(需得使用时才使用)。
注:_bh 这个命名,继承自中断的上半部(top half)、下半部(bottom half, 简称bh)。在linux较老的内核版本中,中断下半部有独立的实现。后在linux2.6版本后,逐步都替代为软中断实现,但沿用了之前的命令方式。所以,后续的bh,可以通俗的理解为softirq。
2.5 中断引起的内核控制路径嵌套(spin_lock_irq()、spin_lock_irqsave())
考虑如下场景:
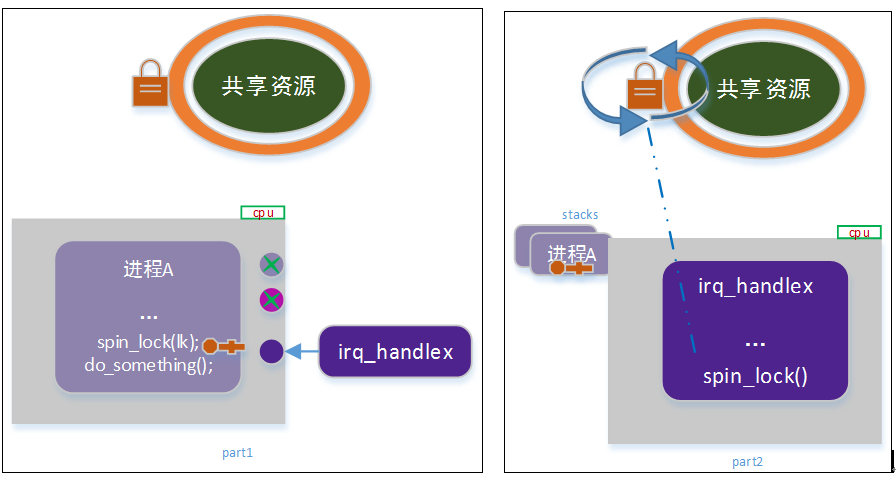
如上图所示,进程a获取共享资源锁,并处于临界区,此时该cpu上有硬件中断产生;中断服务例程中,尝试请求共享资源锁时,出现死锁。
为了避免这种情况,进程a在进入临界区之前,可以关闭本地中断。伪代码如下:
点击(此处)折叠或打开
-
...
-
local_irq_disable (); // 关闭本地软中断
-
spin_lock(lk);
-
do_something();
-
spin_unlock(lk);
-
local_irq_enable();
- ...
同样,内核spin lock封装了一个快捷的接口实现该功能:spin_lock_irq()。
spin_lock_irq() 伪代码:
点击(此处)折叠或打开
-
void spin_lock_irq(locker)
-
{
-
local_irq_disable (); //关闭本地中断
-
preempt_disable(); // 禁用内核抢占
-
while(true)
-
{
-
//原子接口:如果锁空闲,则转为繁忙状态,并返回true;如果当前已经是繁忙
-
//状态,则返回false。
-
if ( try_get_lock(locker))
-
//成功获取到锁
-
return;
-
else
-
// 未取得锁,优化cpu忙查询逻辑,防止过于高频空转
-
cpu_relax();
-
}
-
}
-
-
void spin_unlock_irq(locker)
-
{
-
put_lock(locker); //原子接口,锁状态清理到空闲状态
-
local_irq_enable(); //使能本地中断
-
preempt_enable(); // 使能内核抢占
- }
注意:spin_lock_irq 中,禁止了本地中断和内核抢占,但并没有禁止软中断。对于该设计原由,笔者尚未查证,望读者注意!个人理解:如果一个临界区 同时被进程、软中断、硬中断访问,这设计上是不合理的(是否有硬性限制或者设计潜规则禁止这样做?我还未找到出处。一般认为,禁止了硬中断,就隐性禁止了软中断,因为大多数软中断是由硬中断触发的;但这个描述不全面,因为有部分软中断是内核触发的)。如果确实有类似场景,也可以在临界区调用相关接口(local_bh_disable, local_bh_enable)进行切换。
硬件中断服务例程处理过程,与软中断服务例程处理有一点差异:软中断的服务例程不会被软中断打断,但硬件中断服务例程,却可能会被硬中断打断。因此,在临界区中,简单的禁用/启用本地中断,可能在某些极端情况下,依然有问题。
考虑以下场景: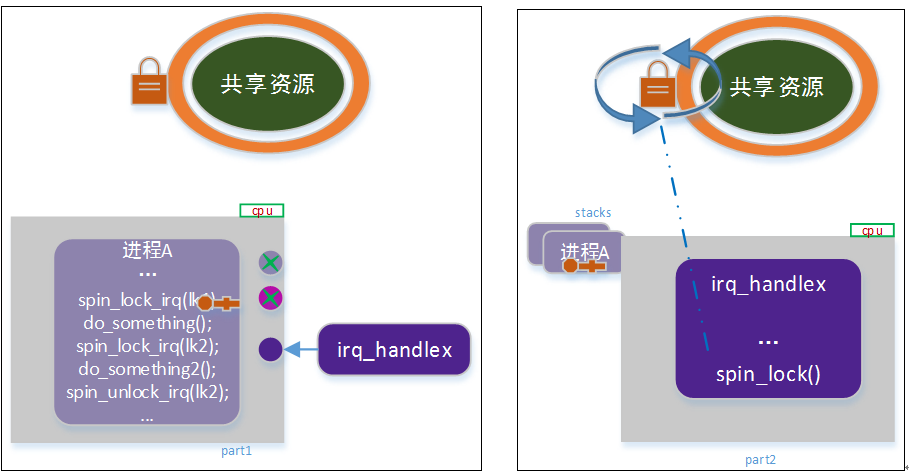
如上图,进程a获取共享资源锁并处于临界区,在临界区内,通过spin_lock_irq/spin_unlock_irq 访问了另外一个共享资源(访问结束后,本地中断被打开);此时,中断发生,中断服务例程中,又请求了当前共享资源。于是“死锁”又出现了!
显然,上述的问题出在,第二次共享资源访问后,打开中断。在这里,真正的述求是,“我在访问临界区时,保存中断关闭的”,而不是“访问完成后,打开中断”。正确的做法是:第一步,记录当前的中断开启状态(禁用/启用);第二步,禁用本地中断,并进入临界区;第三步,退出临界区时,恢复之前的中断状态(而不是打开)。
同样,内核提供了一个便捷的spin lock 接口:spin_lock_irqsave()。
点击(此处)折叠或打开
-
unsigned long spin_lock_irqsave(locker)
-
{
-
unsigned long flags;
-
local_irq_save (flags); //记录当前中断状态到flags中,同时禁用本地中断
-
preempt_disable(); // 禁用内核抢占
-
while(true)
-
{
-
//原子接口:如果锁空闲,则转为繁忙状态,并返回true;如果当前已经是繁忙
-
//状态,则返回false。
-
if ( try_get_lock(locker))
-
//成功获取到锁
-
return flags;
-
else
-
// 未取得锁,优化cpu忙查询逻辑,防止过于高频空转
-
cpu_relax();
-
}
-
}
-
-
void spin_unlock_irqrestore(locker, flags)
-
{
-
put_lock(locker); //原子接口,锁状态清理到空闲状态
-
local_irq_restore(flags); //恢复本地中断状态
-
preempt_enable(); // 使能内核抢占
- }
调整后示意图:
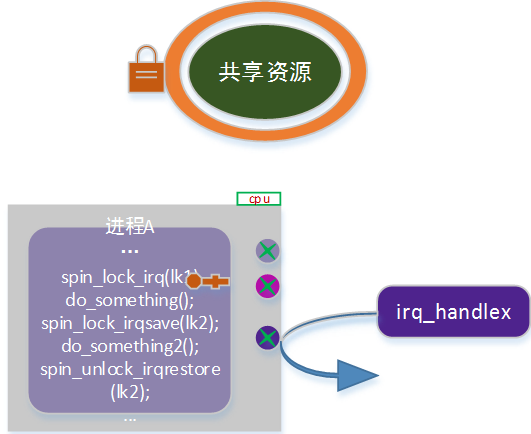
在第一章中,我们描述不同的控制路径,以及他们的一些特点。实际上,因为在设计和实现上的一些机制和要求,某些情况下,内核竞态是不存在,因此也不需要做内核同步(内核同步,会极大的影响系统性能,在不需要的情况下,尽量不要引入)。
3.1 不需要做内核同步情形
(一) 只在某一种特定的中断服务例程中访问的资源不需要做同步
所有的中断处理程序的响应来自于pic的中断并禁用irq线;在中断处理程序结束前,不允许产生相同的中断。
(二) 只在一个特定的tasklet中访问的资源不需要做同步
软中断,tasklet 既不能被抢占(不会被进程或软中断打断,可以被硬中断打断,但硬中断结束后,会恢复执行),也不可以阻塞;并且,同一个tasklet不可能在多个cpu上同时执行。
(三) 只在一个特定内核timer中访问的资源不需要做同步
同一个timer不可能在多个cpu上同时执行。
(四) 只在软中断或tasklet中访问的per-cpu 变量,不需要同步
per-cpu变量,是每一个cpu本地维护一份,因此不存在多处理器间的并发竞态;同时软中断处理程序也不会被软中断打断(不会自身嵌套)。
3.2 需要内核同步的情况下如何选择spin_lock 系列接口函数
1) 在多个进程上下文中访问临界区(task vs task)
标准的多处理器竞态,用spin_lock/spin_unlock函数对即可。
2) 在多个进程和软中断(包括tasklet和timer)中访问的临界区 (task vs softirq)
由于软中断会打断进程的处理,因此在进程上下文进入临界区时,必须要禁用软中断,否则会形成死锁。因此该场景下需要使用 spin_lock_bh /spin_unlock_bh函数对。
3) 在进程和中断处理例程中访问的临界区(task vs irq)
由于中断会打断进程的处理,因此进程上下文进入临界区时,必须要禁用本地中断,否则会形成死锁。该场景下,需要使用spin_lock_irq /spin_unlock_irq 或者spin_lock_irqsave/ spin_unlock_irqrestore函数对。
4) 在软中断,不同类型的tasklet之间,不同类型的timer之间访问的临界区(softirq vs softirq)
由于软中断之间不可以相互打断,因此他们之间的竞态是普通多处理器之间的竞态,用spin_lock函数对即可(无需使用_bh 版本)。
5) 在软中断(包括tasklet和timer)与中断处理例程中的访问的临界区(softirq vs irq)
由于中断会打断软中断,那么在软中断处理例程中,进入临界区必须要关闭中断,否则可能形成死锁。该场景下,需要使用spin_lock_irq/spin_unlock_irq 或者spin_lock_irqsave/ spin_unlock_irqrestore函数对。
6) 在不同的中断处理例程中访问的临界区( irq vs irq)
由于硬中断之间可以相互打断,因此在中断服务例程中,进入临界区时必须要关闭中断,否则可能形成死锁。该场景下,需要使用spin_lock_irq/spin_unlock_irq 或者spin_lock_irqsave / spin_unlock_irqrestore函数对。