ocp考试资料群:569933648 验证码:ocp ocp 12c 19c考试题库解析与资料群:钉钉群号:35277291
全部博文(486)
- postgresql(55)
- ocp 12c(175)
- ocp(102)
- 未分配的博文(154)
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
分类: mysql/postgresql
2023-11-01 17:09:58

postgresql从小白到专家,是从入门逐渐能力提升的一个系列教程,内容包括对pg基础的认知、包括安装使用、包括角色权限、包括维护管理、、等内容,希望对热爱pg、学习pg的同学们有帮助,欢迎持续关注cuug pg技术大讲堂。
第31讲:sql调优技巧
第31讲预告:10月28日(周六)19:30-20:30,钉钉群直播,群号:35822460
内容1 : sql调优范式
内容2 : 多表查询调优技巧
内容3 : 多表查询应用案例
开发范式一
· 不要轻易把字段嵌入到表达式
在sal列上有索引,但是条件语句中把sal列放在了表达式当中,导致索引被压抑,因为索引里面储存的是sal列的值,而不是sal加上100以后的值。
testdb=# explain select * from emp2 where sal 100 = 2000;
query plan
-------------------------------------------------------------------------
gather (cost=1000.00..7796.60 rows=2294 width=36)
workers planned: 2
-> parallel seq scan on emp2 (cost=0.00..6567.20 rows=956 width=36)
filter: ((sal 100) = 2000)
(4 rows)
· 改写成
通过等式等换,把sal列从表达式中剥离出来,就会用到索引。
testdb=# explain select * from emp2 where sal = 2000 - 100;
query plan
--------------------------------------------------------------------------
index scan using emp2_sal_ind on emp2 (cost=0.42..8.44 rows=1 width=36)
index cond: (sal = 1900)
(2 rows)
开发范式二
· 不要轻易把字段嵌入到函数中
在hiredate列上有索引,但是条件语句中把该列放在了函数当中,导致索引被压抑,因为索引里面储存的是该列的值,而不是函数处理以后的值。
testdb=# explain select * from emp2 where to_char(hiredate,'dd-mm-yyyy')='22-05-2022';
query plan
----------------------------------------------------------------------------------------------------
seq scan on emp2 (cost=0.00..289.32 rows=50 width=62)
filter: (to_char((hiredate)::timestamp with time zone, 'dd-mm-yyyy'::text) = '22-05-2022'::text)
· 改写成
通过等式转换,把列从函数中剥离出来,就会用到索引,比较成本,差别很大。
testdb=# explain select * from emp2 where hiredate=to_date('22-05-2022','dd-mm-yyyy');
query plan
----------------------------------------------------------------------------
index scan using emp2_hiredate on emp2 (cost=0.29..8.30 rows=1 width=62)
index cond: (hiredate = to_date('22-05-2022'::text, 'dd-mm-yyyy'::text))
开发范式三
· 如果查询中比较固定查询某些列,可以基于这几个列建复合索引,直接查询索引,避开回表扫描。
create index emp2_empno on emp2 (empno,sal);
testdb=# explain select empno,sal from emp2 where empno=7788;
query plan
-----------------------------------------------------------------------------
index only scan using emp2_empno on emp2 (cost=0.29..10.09 rows=2 width=8)
index cond: (empno = 7788)
多表查询指导方针
· oltp应用sql调优指导方针
-- 驱动表上有很好的条件限制,同时,驱动表上的限制性条件字段上应该有索引,包括主键、唯一索引或其它索引、复合索引等。
-- 在每次连接操作之后尽量保证返回记录数{banned}最佳少,传递给下一个连接操作。
-- 根据返回的行的数量对应正确的连接方式。
-- 尽量通过在被驱动表的连接字段上的索引,访问被驱动表。
-- 单表扫描应该有效率,如果被驱动表上还有其它限制条件,可以遵循复合索引创建原则,创建合适的复合索引(连接字段与条件字段)。
-- 全表扫描也许是合理的,例如若干小表、代码表的访问。
-- 依次类推,顺序完成所有表的连接操作。
· 多表连接调优总体思路
>> 如果是oltp应用,则优化的思路是由小到大,即从限制性{banned}最佳强,返回记录{banned}最佳少的连接开始,依次完成其它表的连接,并在访问每张表时,合理使用索引,特别是复合索引技术。
>> 如果是olap应用,则优化思路基本是hash连接加并行处理,表连接顺序不是{banned}最佳主要的。
· 多表连接优化案例一
testdb=# explain select e.*,d.*
from emp e,dept d
where d.deptno=e.deptno
and e.empno=7499;
query plan
-----------------------------------------------------------------------------
nested loop (cost=0.30..16.36 rows=1 width=192)
-> index scan using pk_emp on emp e (cost=0.15..8.17 rows=1 width=98)
index cond: (empno = 7499)
-> index scan using pk_dept on dept d (cost=0.15..8.17 rows=1 width=94)
index cond: (deptno = e.deptno)
执行计划解读:
1、先按照建立在empno字段上的索引去emp表查询empno为7499的员工信息。
2、再根据7499所在的部门号(deptno)去dept表查询该部门的详细信息,而且dept表的deptno字段上应该有索引。
3、{banned}最佳后使用嵌套循环连接方式处理数据。
建议:
“如果是多表连接sql语句,注意驱动表的连接字段是否需要创建索引”。
在上例中,被驱动表是dept,dept表的连接字段是deptno,而emp的deptno字段是可以不需要建索引的,因为已经根据条件字段上列访问驱动表。
· 多表连接优化案例二
testdb=# explain select e.*,d.*
from emp e,dept d
where d.deptno=e.deptno
and e.empno=7499
and d.dname='dallas';
query plan
-----------------------------------------------------------------------------
nested loop (cost=0.30..20.35 rows=1 width=192)
-> index scan using pk_emp on emp e (cost=0.15..8.17 rows=1 width=98)
index cond: (empno = 7499)
-> index scan using pk_dept on dept d (cost=0.15..8.17 rows=1 width=94)
index cond: (deptno = e.deptno)
filter: ((dname)::text = 'dallas'::text)
执行计划解读:
1、先按照建立在empno字段上的索引去emp表查询empno为7499的员工信息。
2、再根据7499所在的部门号(deptno)去dept表查询该部门的详细信息。此时dept表还有一个条件字段loc=‘dallas’,因此可考虑按(deptno,loc)复合索引方式去查询dept表,效率更高,即可建立(deptno,loc)字段上的复合索引(idx_dept_2)。
3、{banned}最佳后以嵌套循环的连接方式处理数据。
建议:
“如果是多表连接sql语句,注意是否可以在被驱动表的连接字段与该表的其它约束条件字段上创建复合索引”。索引可以在dept表上创建(deptno与dname)字段的复合索引。
执行计划解读(续)
应该遵循关于复合索引创建时的建议:
“如果单个字段是主键或者唯一字段,或者可选性非常高的字段,尽管约束条件字段比较固定,也不一定要建成复合索引,可建成单字段索引,降低复合索引开销”。
*而且通过比较发现这种情况创建单列索引比创建复合索引查询的时候代价要低的多。所以在本例中,不应该创建复合索引。
多表查询应用案例
· 5张查询应用案例
select emp.last_name,emp.first_name,j.job_title,d.department_name,l.city,l.state_province,l.postal_code,l.street_address,emp.email,emp.phone_number,emp.hire_date,emp.salary,mgr.last_name
from hr.employees emp,hr.employees mgr,hr.departments d,hr.locations l,hr.jobs j
where l.city='south san francisco'
and emp.manager_id=mgr.employee_id
and emp.department_id=d.department_id
and d.location_id=l.location_id
and emp.job_id=j.job_id;
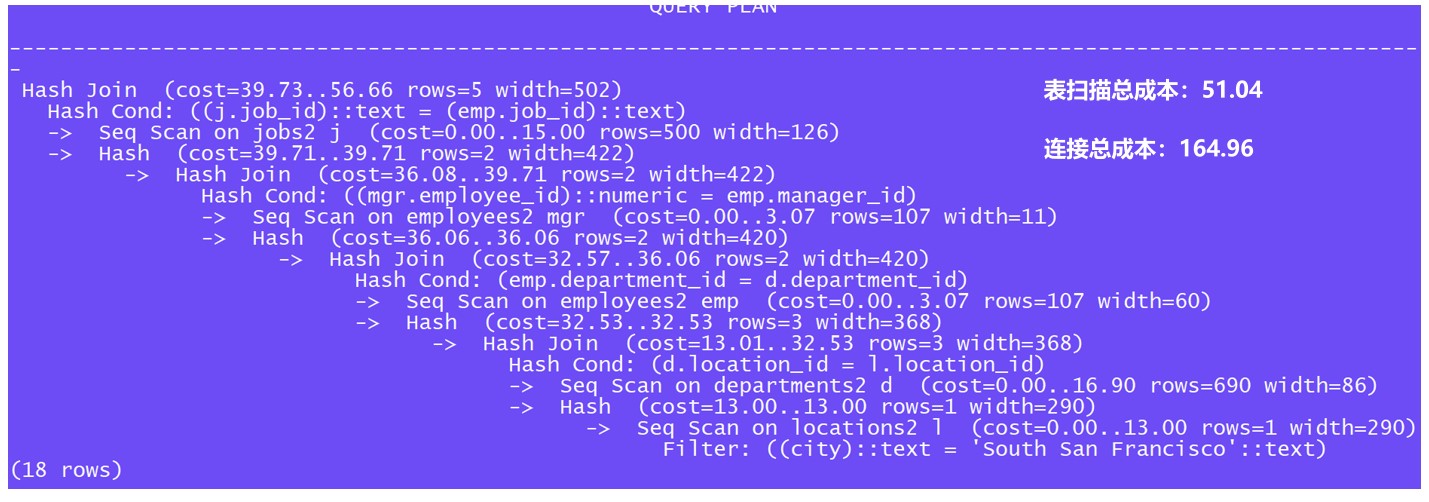
· {banned}中国第一种情况:无索引
在没有任何索引的情况下查看其执行计划 ,由于没有索引,所以所有扫描方式均为全表扫描,连接方式为hash join。
· 第二种情况:创建单列索引
在locations的city、location_id列上创建索引。
在departments的location_id上创建索引
在departments的department_id上创建主键约束
在employees的employee_id上创建主键约束
在jobs的job_id上创建主键约束。

· 第三种情况:创建复合索引
在locations的city、location_id列上创建复合索引。
在departments的department_id 、location_id上创建复合索引
在employees的employee_id、 department_id、manager_id、job_id上创建复合索引(或者单列索引)
在jobs的job_id上创建主键约束。

· 三种执行计划成本对比

经过分析发现,如果连接方式能够走嵌套循环,那么其成本比其它连接方式都低,当然我们要提供条件让优化器自动选择成本{banned}最佳低的连接方式,只要有一张表的访问方式是索引扫描,那么连接方式一般会选择嵌套循环。
employees表的复合索引在执行计划中起到了作用,或者选择在连接条件列上( employee_id,department_id,manager_id )创建单列索引。
departments和locations表的记录比较少,即使创建了单列或者多列索引,都不会使用索引。
连接顺序是l->d->emp-mgr-j