ocp考试资料群:569933648 验证码:ocp ocp 12c 19c考试题库解析与资料群:钉钉群号:35277291
全部博文(486)
- postgresql(55)
- ocp 12c(175)
- ocp(102)
- 未分配的博文(154)
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
分类: mysql/postgresql
2023-09-22 14:46:37

postgresql从小白到专家,是从入门逐渐能力提升的一个系列教程,内容包括对pg基础的认知、包括安装使用、包括角色权限、包括维护管理、、等内容,希望对热爱pg、学习pg的同学们有帮助,欢迎持续关注cuug pg技术大讲堂。
第30讲:多表连接方式
第30讲预告:9月23日(周六)19:30-20:30,钉钉群直播,群号:35822460
内容1 : nested loop join连接方式
内容2 : merge join连接方式
内容3 : hash join连接方式
多表连接方式
多表连接方式
三种连接方式:
nested loop join
merge join
hash join
支持所有join操作:
natural inner join
inner join
left/right outer join
full outer join
嵌套循环连接方式
nested loop join
嵌套循环联接是{banned}最佳基本的联接操作,它可以用于任何联接条件。

nested loop join图解
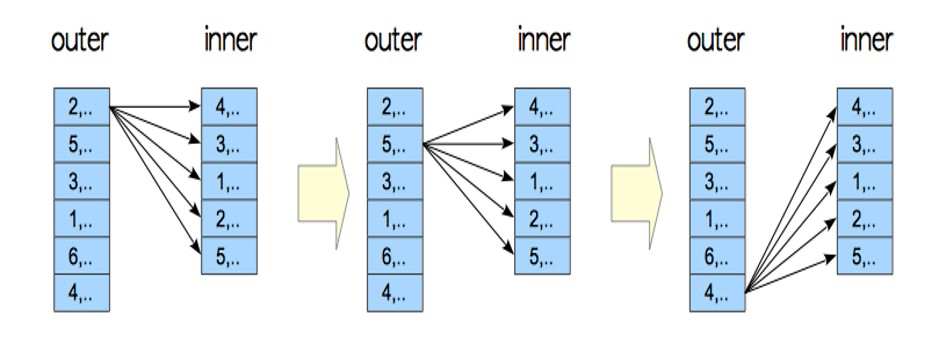
materialized nested loop join
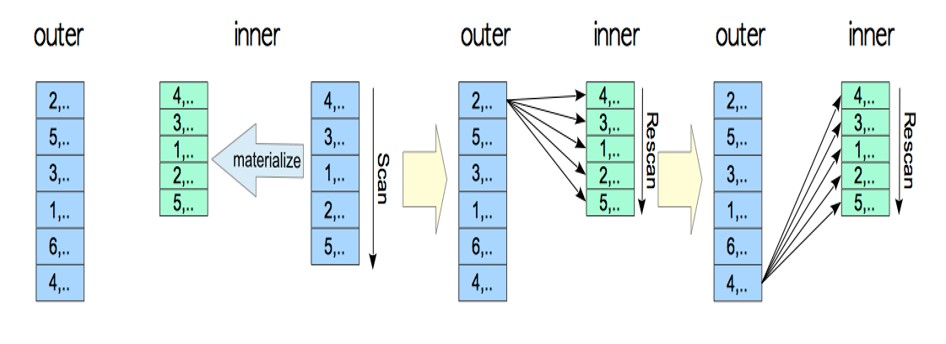
我们使用下面的具体示例来探索执行器如何处理具体化嵌套循环连接的计划树,以及如何估计成本。
testdb=# explain select * from tbl_a as a, tbl_b as b where a.id = b.id;
query plan
-----------------------------------------------------------------------
nested loop (cost=0.00..750230.50 rows=5000 width=16)
join filter: (a.id = b.id)
-> seq scan on tbl_a a (cost=0.00..145.00 rows=10000 width=8)
-> materialize (cost=0.00..98.00 rows=5000 width=8)
-> seq scan on tbl_b b (cost=0.00..73.00 rows=5000 width=8)
(5 rows)
materialize成本估算

(materialized) nested loop成本估算

indexed nested loop join
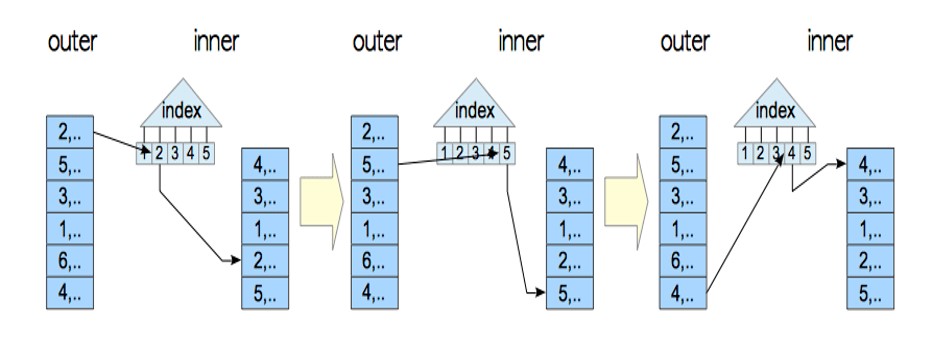
testdb=# explain select * from tbl_c as c, tbl_b as b where c.id = b.id;
query plan
--------------------------------------------------------------------------------
nested loop (cost=0.29..1935.50 rows=5000 width=16)
-> seq scan on tbl_b b (cost=0.00..73.00 rows=5000 width=8)
-> index scan using tbl_c_pkey on tbl_c c (cost=0.29..0.36 rows=1 width=8)
index cond:(id=b.id)
(4 rows)
具有外部索引扫描的嵌套循环联接的三种变体
merge join连接方式
merge join
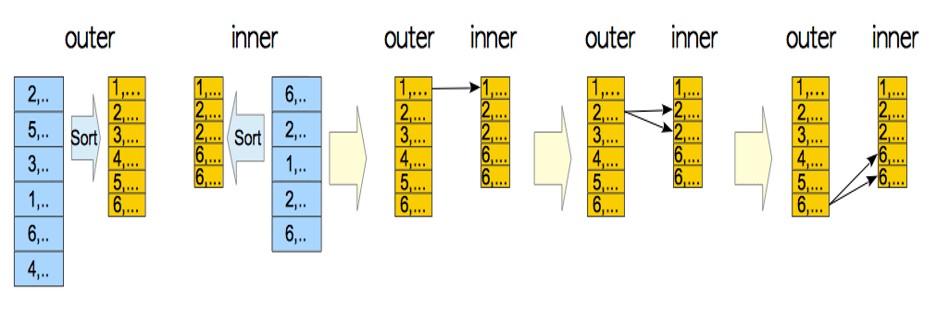
merge join成本估算
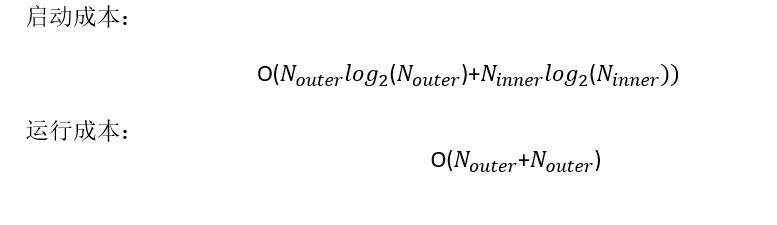
testdb=# explain select * from tbl_a as a, tbl_b as b where a.id = b.id and b.id < 1000;
query plan
-------------------------------------------------------------------------
merge join (cost=944.71..984.71 rows=1000 width=16)
merge cond: (a.id = b.id)
-> sort (cost=809.39..834.39 rows=10000 width=8)
sort key: a.id
-> seq scan on tbl_a a (cost=0.00..145.00 rows=10000 width=8)
-> sort (cost=135.33..137.83 rows=1000 width=8)
sort key: b.id
-> seq scan on tbl_b b (cost=0.00..85.50 rows=1000 width=8)
filter: (id < 1000)
(9 rows)
materialized merge join

other variations
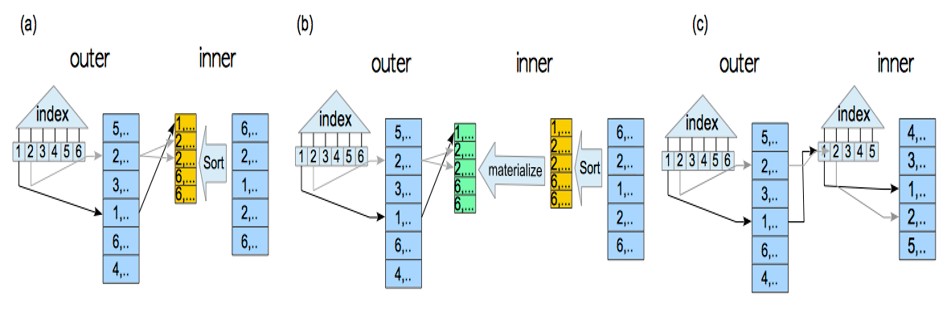
强制使用merge join
testdb=# set enable_hashjoin to off;
testdb=# set enable_nestloop to off;
testdb=# explain select * from tbl_c as c, tbl_b as b where c.id = b.id and b.id < 1000;
query plan
--------------------------------------------------------------------------------------
merge join (cost=135.61..322.11 rows=1000 width=16)
merge cond: (c.id = b.id)
-> index scan using tbl_c_pkey on tbl_c c (cost=0.29..318.29 rows=10000 width=8)
-> sort (cost=135.33..137.83 rows=1000 width=8)
sort key: b.id
-> seq scan on tbl_b b (cost=0.00..85.50 rows=1000 width=8)
filter: (id < 1000)
(7 rows)
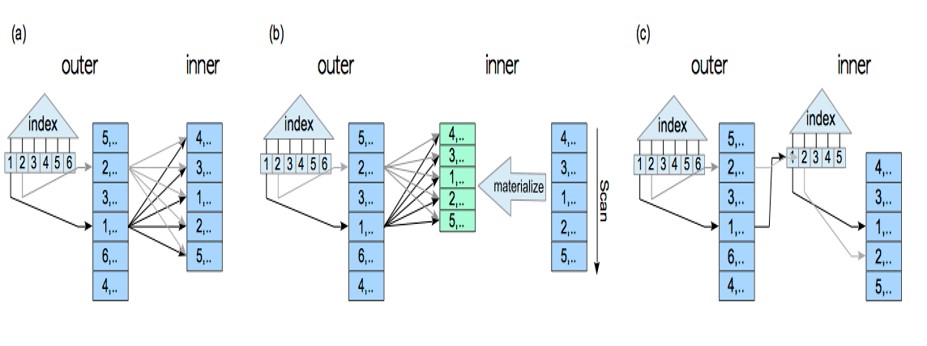
materialized merge join with outer index scan
testdb=# set enable_hashjoin to off;
testdb=# set enable_nestloop to off;
testdb=# explain select * from tbl_c as c, tbl_b as b where c.id = b.id and b.id < 4500;
query plan
--------------------------------------------------------------------------------------
merge join (cost=421.84..672.09 rows=4500 width=16)
merge cond: (c.id = b.id)
-> index scan using tbl_c_pkey on tbl_c c (cost=0.29..318.29 rows=10000 width=8)
-> materialize (cost=421.55..444.05 rows=4500 width=8)
-> sort (cost=421.55..432.80 rows=4500 width=8)
sort key: b.id
-> seq scan on tbl_b b (cost=0.00..85.50 rows=4500 width=8)
filter: (id < 4500)
(8 rows)
indexed merge join with outer index scan
testdb=# set enable_hashjoin to off;
testdb=# set enable_nestloop to off;
testdb=# explain select * from tbl_c as c, tbl_d as d where c.id = d.id and d.id < 1000;
query plan
--------------------------------------------------------------------------------------
merge join (cost=0.57..226.07 rows=1000 width=16)
merge cond: (c.id = d.id)
-> index scan using tbl_c_pkey on tbl_c c (cost=0.29..318.29 rows=10000 width=8)
-> index scan using tbl_d_pkey on tbl_d d (cost=0.28..41.78 rows=1000 width=8)
index cond: (id < 1000)
(5 rows)
hash join连接方式
hash join

in-memory hash join
构建阶段:
将内部表的所有元组插入到一个批处理中
探测阶段:
将外部表的每个元组与批处理中的内部元组进行比较,如果满足连接条件,则进行连接
hash join

计划器处理转变
预处理
1、计划和转换cte(如果查询中带有with列表,则计划器通过ss_process_ctes()函数处理每个with查询)
2、向上拉子查询
根据子查询的特点,改为自然连接查询。
testdb=# select * from tbl_a as a, (select * from tbl_b) as b where a.id = b.id;
testdb=# select * from tbl_a as a, tbl_b as b where a.id = b.id;
3、将外部联接转换为内部联接
优化器可用规则
getting the cheapest path
1、表数量小于12张,应用动态规划得到{banned}最佳优的计划
2、表数量大于12张,应用遗传查询优化器
参数 geqo_threshold指定的阈值(默认值为12)
3、分为不同的级别层次来处理
多表查询连接顺序选择
sgetting the cheapest path of a triple-table query
testdb=# select * from tbl_a as a, tbl_b as b, tbl_c as c
testdb=# where a.id = b.id and b.id = c.id and a.data < 40;
考虑3种组合:
{tbl_a,tbl_b,tbl_c}=min({tbl_a,{tbl_b,tbl_c}},{tbl_b,{tbl_a,tbl_c}},{tbl_c,{tbl_a,tbl_b}}).
创建多表查询的计划树· 此查询的explain命令的结果如下所示
