天翼云是中国电信倾力打造的云服务品牌,致力于成为领先的云计算服务提供商。提供云主机、cdn、云电脑、大数据及ai等全线产品和场景化凯发app官方网站的解决方案。
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
分类: 高性能计算
2024-04-23 14:58:25
本文分享自天翼云开发者社区《》,作者:l****n
首先,我们先回顾下一致性hash以及其在经典存储系统中的应用。
一致性hash的基本原理
一致性hash的基本思想是,有一个hash函数,这个hash函数的值域形成了一个环(收尾相接:the largest hash value wraps around to the smallest hash value),然后存储的节点也通过这个hash函数随机的分配到这个环上,然后某个key具体存储到哪个节点上,是由这个key取hash函数对应到环的一个位置,然后沿着这个位置顺时针找到的di一个节点负责这个key的存储。这样环上的每个节点负责和它前面节点之间的这个区间的数据的存储。
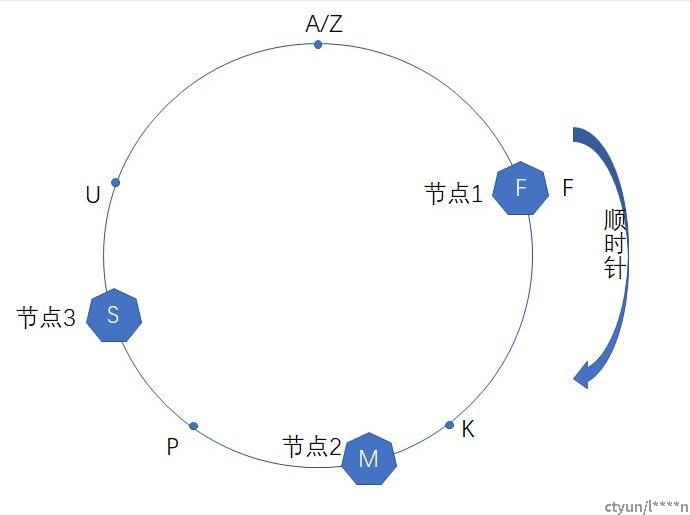
如上图所示,hash函数的总区间是[a, z],有3个存储节点分别对应到f、m和s的位置上,那么hash值为a或者z的key将会顺时针查找它遇到的di一个节点,因此会存储到节点1上,同理hash值为k的key存储到第二个节点上。咱们再观察下一致性hash在增删节点的时候,数据迁移的情况,在上图的场景中,如果删除节点2的话,节点1上面的不会发生变化,原来存储在节点2上的(f,m]区间会迁移存储到节点3上;在上图的场景中,如果在u位置增加一个节点的话,原来存储到节点1上的(s, f]区间会分割成两个区间其中(s, u]会存储到新的节点上,而(u, f]不发生变化还是存储到节点1上。从上面的例子中可以看到,一致性hash在增删节点的时候,只影响与其相邻的节点,并且需要迁移的数据zui少。
上面这种朴素的一致性hash有两个问题,di一个问题是如果节点较少,节点在环上的分布可能不均匀,导致每个节点的负载不均衡,比如上图中场景,如果节点3故障被剔除的话,节点1和节点2的负载会非常的不均衡;第二个问题是不支持异构的机型,比如如果有的存储节点是4tb的,有的存储节点是8tb的,每个节点对应环上的一个位置,无法感知到节点的权重。为了解决这两个问题,一般都是把每个节点对应到环上的多个位置,称为vnode,vnode足够多的话,可以认为是均衡打散的,如果有节点故障下线的话,这个节点在环上对应的vnode存储的数据就可以均匀分给其他的vnode,zui终存储到对应的node上,因此在增删节点的时候,负载都是在所有的节点中均匀分摊。另外针对异构的机型,比如说4tb和8tb的节点,8tb的节点的vnode是4tb节点的2倍就可以了。
如果vnode节点和环上的点一一对应的话,可以认为是一致性hash的一个特殊的场景,比如说上图中的例子,这个hash环一个有a到z 25个点(a、z重合了),如果有25个vnode和其对应的话,这样一致性hash只需要记录每个物理node节点到vnode的映射关系就可以了,会非常的简单。开源swift对象存储使用的是这种一致性hash,参考:
在分布式系统中为了保障可靠性一般都是多副本存储的,在dynamo存储系统中,用一致性hash算法查找到di一个vnode节点后,会顺序的向下找更多vnode节点,用来存储多副本(中间会跳过同台机器上的vnode,以达到隔离故障域的要求),并且di一个vnode是协调节点。在开源swift对象存储系统中,节点会先分组,比如3个一组,形成一个副本对,然后vnode会分配到某组机器上,一组机器上会有很多的vnode,并且这组机器上的vnode的leader节点在3台机器上会打散,分摊压力。
crush算法的核心思想
crush算法是一个伪随机的路由选择算法,输入pg的id,osdmap等元信息,通过crush根据这个pool配置的crush rule规则的伪随机计算,zui终输出存储这个pd的副本的osd列表。由于是伪随机的,只要osdmap、crush rule规则相同,在任意的机器上,针对某个pg id,计算的zui终的osd列表都是相同的。
crush算法支持在crush rule上配置故障域,crush会根据故障域的配置,沿着osdmap,搜索出符合条件的osd,然后由这些osd抽签来决定由哪个osd来存储这个pg,crush算法内部核心是这个称为straw2的osd的抽签算法。straw2的名字来源于draw straw(抽签:)这个短语,针对每个pg,符合故障域配置条件的osd来抽检决定谁来存储这个pg,osd抽签也是一个伪随机的过程,谁抽到的签zui长,谁赢。并且每个osd的签的长度,都是osd独立伪随机计算的,不依赖于其他osd,这样当增删osd节点时,需要迁移的数据zui少。
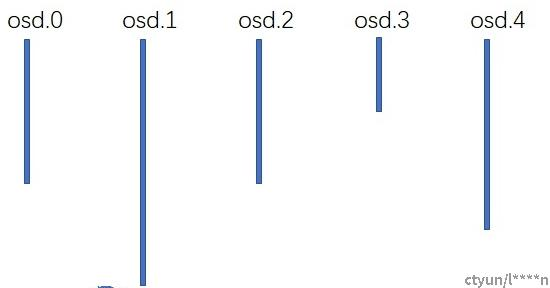
如上图的一个示例,这是针对某个pg的一次抽签结果,从图中可以看到osd.1的签zui长,所以osd.1赢了,zui终osd.1会存储这个pg,在这个时候,如果osd.4由于故障下线,osd.4的故障下线并不会影响其他osd的抽签过程,针对这个pg,zui终的结果还是osd.1赢,因此这个pg不会发生数据的迁移;当然,在上图从场景中,如果osd.1下线的话,osd.1上的pg会迁移到其他的osd上。增加osd节点的情况类似,比如在上图的场景中,如果新增加一个osd.5节点的话,每个osd都是独立抽签,只有osd.5赢的那些pg才会迁移到osd.5上,对其他的pg不会产生影响。因此,理论上,crush算法也和一致性hash一样,在增加删除osd节点的时候,需要迁移的数据zui少。
另外straw2抽签算法也是支持异构的机型的,比如有的osd是4tb,有的osd是8tb,straw2的抽签算法会保证,8tb的osd抽签赢的概率是4tb的osd的两倍。背后的原理是,每个osd有个crush weight,crush weight正比于osd的磁盘大小,比如8tb的osd的crush weight是8左右,4tb的osd的crush weight是4左右。然后每个osd抽签的过程是,以osd的crush weight为指数分布的λ,产生一个指数分布的随机数,zui后再比大小。
另外在ceph中,每个osd除了crush weight,还有个osd weight,osd weight的范围是0到1,表示的含义是这个osd故障的概率,crush算法在伪随机选择pg放置的osd的时候,如果遇到故障的osd,会进行重试。比如说某个osd weight是0的话,说明这个osd彻底故障了,通过上面straw2步骤计算出来的pg会retry重新分配到其他的osd上,如果某个osd的osd weight是0.8的话,这个osd上20%的pg会被重新放置到其他的osd上。通过把osd weight置为0,可以把某个osd节点从集群中临时剔除,通过调整osd weight也可以微调osd上的pg的分布。
总结
ceph分布式存储系统数据分布的基石crush算法,是一个伪随机的路由分布算法,对比一致性hash,它的核心的优点是元数据少,集群增删osd节点时,要迁移的数据少,并且crush算法支持异构的机型,支持各种级别的故障域的配置,它的缺点是在实际应用中发现,由于pg会占用一定的资源,一般每个osd zui多200个pg左右,导致整个集群中pg数并不会特别的多,pg在osd上分布并不是非常的均衡,经常需要微调。
参考: