将晦涩难懂的技术讲的通俗易懂
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
分类: 云计算
2023-11-05 16:52:19
nvdia ai硬件产品介绍-凯发app官方网站
近年来ai大模型的火热,无疑让nvdia称为炙手可热的明星。究其原因是其以gpu为核心的一些列软硬件产品和生态在ai大模型中扮演着核心作用。我们经常听到a100,h100,a800等gpu型号,那么他们究竟是什么关系?以及{banned}最佳近nvdia又推出的dgx hg200又是什么东西?本节内容就是介绍nvdia ai相关的硬件相关的产品体系,让大家明白这些名词背后代表的含义。
从硬件到生态的野心
首先看下面这张大图,就是整个nvdia的整个产品和生态。其中{banned}最佳下面是硬件,以gpu,cpu,dpu三大芯片体系为基础,其中gpu是nvdia的发家产品,也是核心,而dpu是nvdia在完成对以色列mlx收购后,将bluefield系列智能网卡改名为dpu发展而来的,没错就是改名而已。所以nvdia在造概念上还是挺有一套的,时至今日很多人在网上讨论智能网卡和dpu的区别,甚至大书特书,也确实够无聊的,同样的一个bluefield 2,在nvdia收购前叫智能网卡,收购后叫dpu,你说是什么区别?
好了,回到图中,在三大芯片之上是dgx,hgx,egx等一些列硬件平台,他们有的是将gpu以及nvlink组合做成硬件模块组,有的是将gpu、dpu,cpu通过nvlink、pcie等互联直接组成服务器,有的则是使用服务器加上交换机和ib网络直接构成集群。换句话说nvdia的产品不仅仅是芯片,而是还有通过自己的一些列总线技术,服务器技术,交换机技术将芯片进行包装的平台产品。
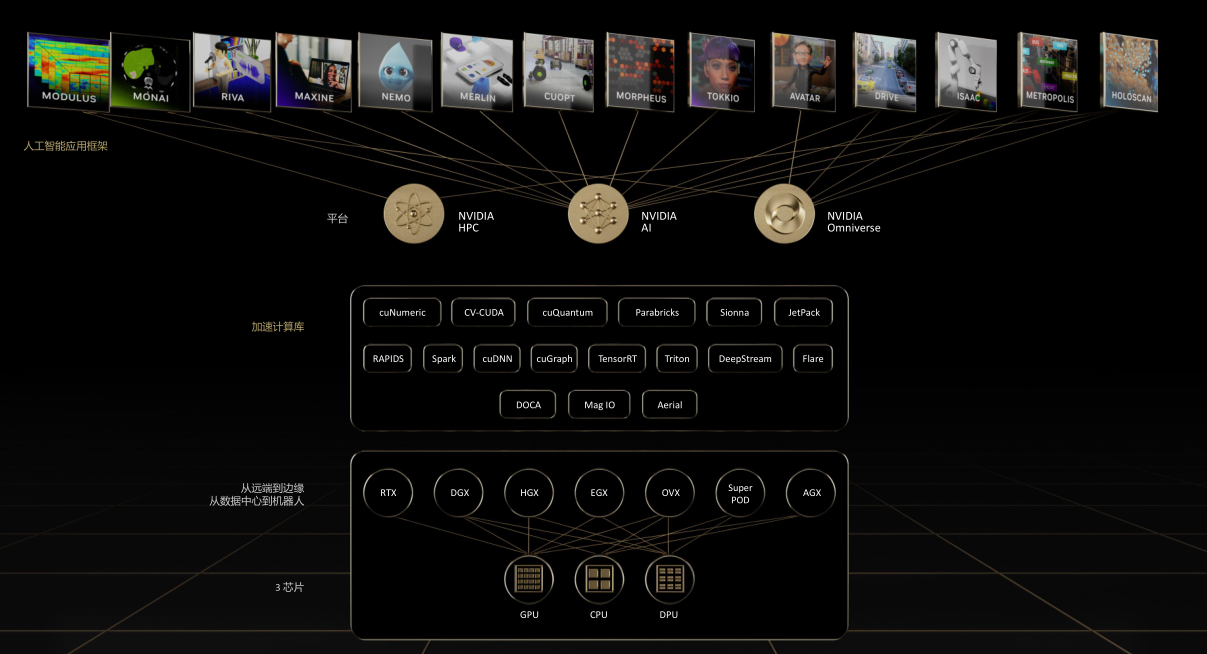

继续向上看,是一个单独的方框,里面是以cuda,doca为代表的软件库,其中cuda是以gpu编程为核心的软件库,而doca是以dpu为核心的软件库。当然还有其他一些,比如rapids是nvdia推出的一台开源数据科学和机器学习加速工具。总之就是nvdia在自己的硬件体系架构上,自己又主导了一些列软件生态,从而向更上层应用层提供服务。让用户深度绑定其软硬件,其野心不可谓不大。
gpu的飞速发展
gpu作为nvdia的核心产品,可用于大模型训练,高性能计算,ai推理,图形渲染,个人游戏等场景。

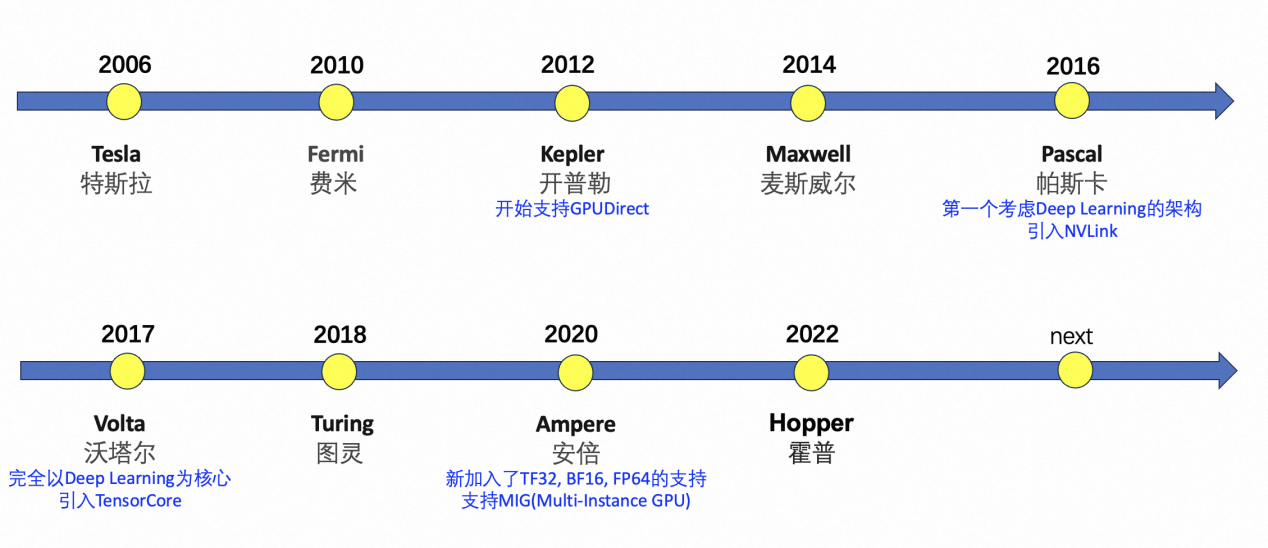
下面我们看一下nvdia的gpu的发展历程。nvdia整体大概没两年推出一个gpu架构,如下图所示,从{banned}最佳早的tesla到当前的hopper架构。这里就不再详细展开,感兴趣可以参考这篇文章。
另一方面,nvdia的显卡目前可以按照应用领域大致分为三种类型:
geforce消费卡:面向游戏娱乐领域:如geforce rtx? 3090、geforce rtx? 3080等。
quadro专业卡:面向专业设计和虚拟化领域:如nvidia rtx? a6000、nvidia? t1000等。
tesla企业级卡:面向深度学习、人工智能和高性能计算领域:如nvidia a100\a30 tensor core gpu等。

这里我们重点讨论一下数据中心gpu,同样是数据中心gpu,同一代架构nvdia也推出了多种不同产品用于不同场景,以ampere系列产品为例,如下图所示。

下面我们讲一下经常听到的几种gpu型号:v100,a100,a800,h100,h800的关系。首先这里的v,a,h分别对应着上图中的三代gpu架构:volta,ampere以及hopper。
l v100
v100是nvdia推出的高性能计算和人工智能加速器,属于volta架构系列。它采用16nm finfet工艺,拥有5120个cuda核心和16gb到32gb的hbm2显存。v100还配备tensor cores加速器,可提供高达120倍的深度学习性能提升。此外,v100支持nvlink技术,实现高速的gpu到gpu通信,加速大规模模型的训练速度。v100被广泛应用于各种大规模ai训练和推理场景,包括自然语言处理、计算机视觉和语音识别等领域。
l a100
a100是nvdia推出的一款强大的数据中心gpu,采用全新的ampere架构。它拥有高达6,912个cuda核心和40gb的高速hbm2显存。a100还包括第二代nvlink技术,实现快速的gpu到gpu通信,提升大型模型的训练速度。此外,a100还支持英伟达自主研发的tensor cores加速器,可提供高达20倍的深度学习性能提升。a100广泛应用于各种大规模ai训练和推理场景,包括自然语言处理、计算机视觉和语音识别等领域。、
l h100
而h100是nvdia基于{banned}最佳新一代hopper架构,采用先进的台积电4nm工艺制造,拥有超过 800 亿个晶体管。nvidia hopper 架构通过 transformer 引擎推进 的发展,hopper tensor core 能够应用混合的 fp8 和 fp16 精度,以大幅加速 transformer 模型的 ai 计算。与上一代相比,hopper 还将 tf32、fp64、fp16 和 int8 精度的每秒浮点运算 (flops) 提高了 3 倍。同时hopper架构支持第四代 nvlink,nvlink switch 系统现在可以跨多个服务器以每个 gpu 900 gb/s 的双向带宽扩展多 gpu io,比 pcie 5.0 的带宽高 7 倍。nvlink switch 系统支持由多达 256 个相互连接的 h100 组成的集群,且带宽比 ampere 架构上的 infiniband hdr 高 9 倍。{banned}最佳后hopper支持第二代mig,借助多实例 gpu (mig),gpu 可以分割成多个较小的、完全独立的实例,并拥有自己的内存、缓存和计算核心。hopper 架构通过多达 7 个 gpu 实例在虚拟化环境中支持多租户、多用户配置,进一步增强了 mig,在硬件和管理程序级别使用机密计算安全地隔离每个实例。
那么a800和h800又是什么呢?a800和h800主要是受限于美国管制,无法直接输出a100和h100,从而推出的阉割产品分别作为a100和h100的代替品。下图整理了相对a100和h100,a800和h800具体有哪些差异。可以看出核心在nvlink带宽的差异,以及fp64的能力上。
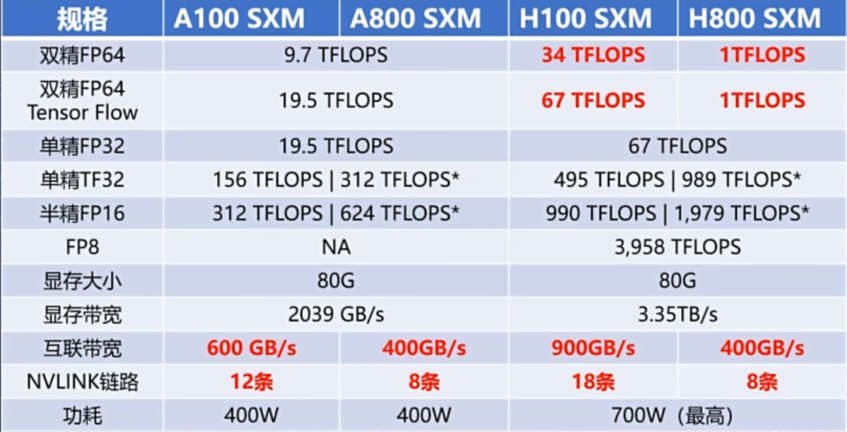
所以与国外厂商相比,如果我们想达到同样的性能,就需要更多的成本。
硬件平台的开枝散叶
我们经常听到的dgx,hgx,egx其实是nvdia提供的三种服务器参考架构,三种架构的配置和性能都有较大差异,应用场景也不同,在数据中心常用的是dgx和hgx(egx常用于边缘),也就是大家常说的“大狗熊”和“黑狗熊”。而这些架构通常后面接的是芯片名称,如dgx a100就是基于a100推出的dgx服务器架构,而hgx a100就是基于a100推出的hgx服务器架构。下面我们分别以dgx 100和hgx 100为例来看dgx和hgx的不同。
dgx a100
dgx a100是nvida继dgx-1和dgx-2之后推出的第三代ai服务器平台,单台服务器就可以用于ai训练,推理,以及大数据分析。其基本配置如下图所示,它有8个a100 gpu,6个nvswitch,15tb的 nvme ssd,9个cx-6dx 200gb网卡,以及双路64 core的amd rome cpu,1tb内存。


nvdia dgx a100 配备 8 块 nvdia a100 tensor core gpu,可帮助用户出色地完成加速任务,同时也针对 nvidia cuda-x? 软件和端到端 nvidia 数据中心解决 方案堆栈进行了全面优化。nvdia a100 gpu 实现了 与 fp32 原理相同的全新精度级别 tf32,相较于上一代 产品,可提供高达 20 倍 flops 的 ai 性能。而{banned}最佳重要 的是,实现此类加速无需改动任何代码。通过 nvdia 自动混合精度功能,只需要增加一行代码 a100 就可以 提供额外两倍的 fp16 精度性能的提升。同时,a100 gpu 拥有世界领先的显存带宽 (1.6 tb/s),与上一代 产品相比,增幅超过 70%。另外,a100 gpu 有超大 片上内存,包括 40 mb 的二级缓存,比上一代产品大 近 7 倍,可更大限度地提升计算性能。dgx a100 还 推出速度为上一代 2 倍的全新 nvdia nvswitch 和 新一代 nvdia nvlink? 技术,后者可将 gpu 之间的 直连带宽增加一倍,从而达到 600 gb/s,而这几乎是 pcie gen 4 的 10 倍。这种强大的功能可助力用户更快 解决问题,以及应对此前无法解决的难题。
所以dgx就是nvdia做好的一个现成的服务器,上面有nvdia的商标,买过来就自己能用,不用自己买其他硬件组装。
hgx a100
hgx a100是第三方服务器厂商(如浪潮,h3c等)按照nvdia提供的specification设计的gpu服务器,且服务器出厂前会经由nvdia进行严格的认证。为什么会有这样一个形态呢?主要是nvdia并没有nvlink的接口设计暴露给服务器厂商,不想pcie一样服务器厂商可以自行设计互联,而是由nvdia自己将gpu通过nvlink,nvswitch连接好的一个模组交给服务器厂商,服务器厂商决定如何适配这个模组即可。尽管如此,相比dgx,hgx也给了不同厂商更多定制空间,比如各个云厂商并不想使用nvdia的网卡,而使用自己的dpu。
此外,相比dgx a100,hgx a100提供了更多的配置,比如产品上有4 gpu的模组,也有8gpu的模组。甚至可以将两个8卡gpu通过nvswitch连接,实现16gpu全互联。并且a100 gpu在选择上可以是40gb或者80gb两种选型,也可以选择nvlink或者pcie接口的gpu。对内存,cpu和网络没有统一的标准规定,各个服务器厂商可以自己设计,只要能通过nvdia的官方认可即可。
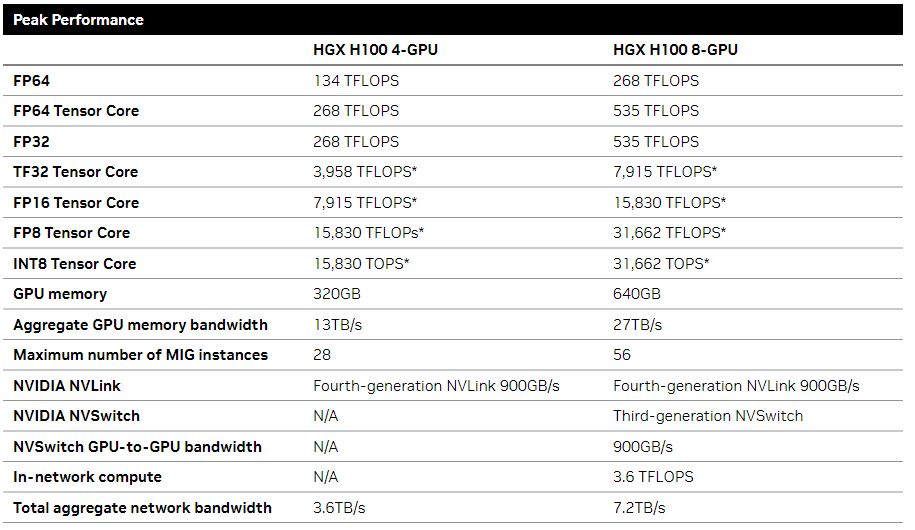
知道了dgx a100和hgx a100,我们如果再看到hgx h100这种就不难理解了,无非是一些参数和特性的变化。
dgx superpod
dgx superpod就是由dgx产品组成的大的网络pod。如下图所示就为有dgx h100构成的dgx h100 superpod的构成。
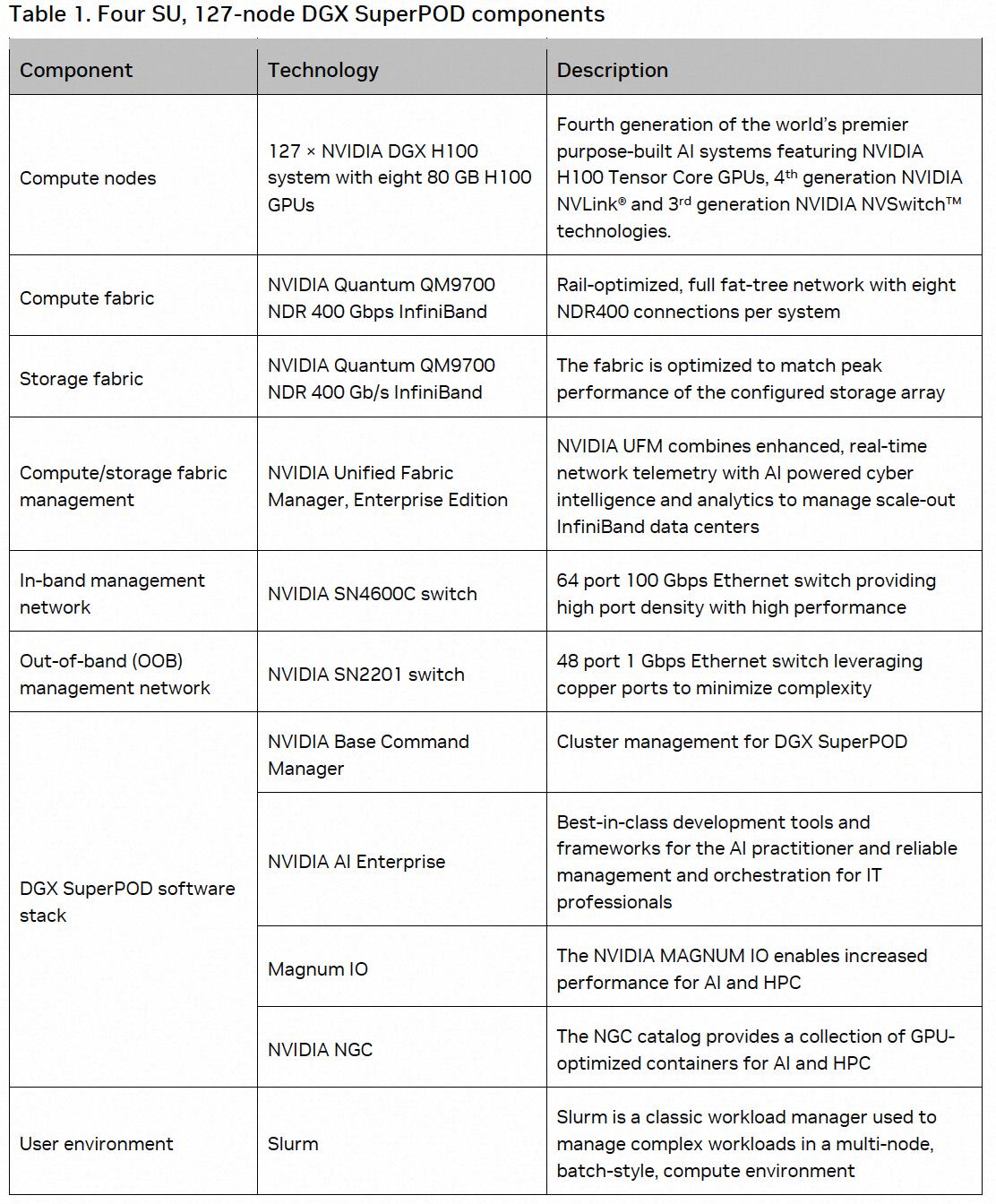
通过nvdia提供的dgx h100和相关存储及网络软硬件组成一个超级pod用于高性能ai计算。
grace hopper架构
在gtc 2022上,nvdia发不了grace hopper superchip架构,它主要包含一下几个创新点。grace是只nvdia自研的grace cpu,而hopper就是hopper架构的gpu。
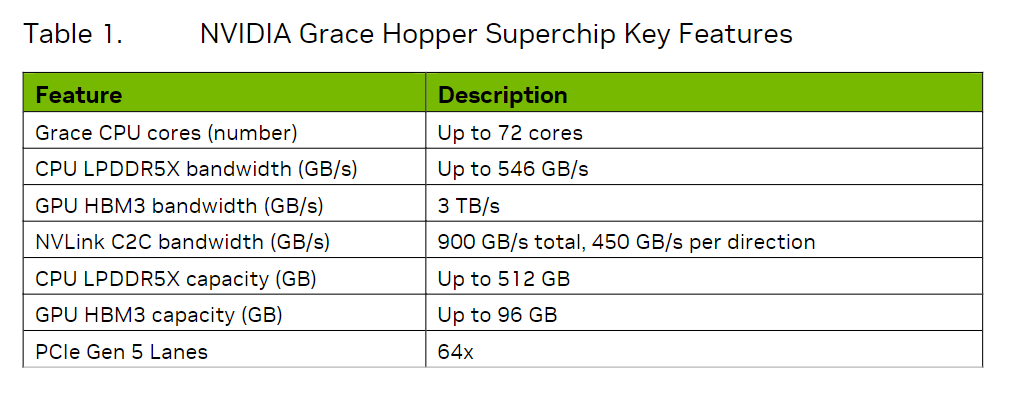
grace cpu是英伟达的{banned}中国第一个数据中心cpu,拥有{banned}最佳多72个arm neoverse v2核心,支持{banned}最佳多512gb的lpddr5x内存,每个cpu的内存带宽可达546gb/s。
hopper是英伟达第九代数据中心gpu,相较于上一代ampere 有很多提升,前文已经介绍过,这里就不再介绍了。
grace hopper superchip将grace cpu和hopper gpu放到了一块电路板上,上一次cpu和gpu走这么近的时候,还是集成显卡“寄生”在cpu时候。如下图所示,在单个超级芯片中,grace和hopper之间通过一个叫nvlink chip-2-chip(c2c)的互联技术连在了一起,提供高达900 gb/s的总带宽(单向是450gb/s),是x16的pcie gen5的7倍,可以为两个芯片提供内存一致性、高带宽和低延迟的通信。nvlink c2c所提供的内存一致性优势,可以提高开发者的生产力,可以提高性能,可以提高gpu的可访问的内存容量。在nvlink c2c的帮助下,cpu和gpu现在可以同时且透明地访问对方的内存,这使得开发者可以专注于算法设计,而不用花时间做内存管理。nvlink c2c所提供的内存一致性,允许开发者只传输他们需要的数据,而不需要把整个页面数据迁移到gpu或从gpu迁出。
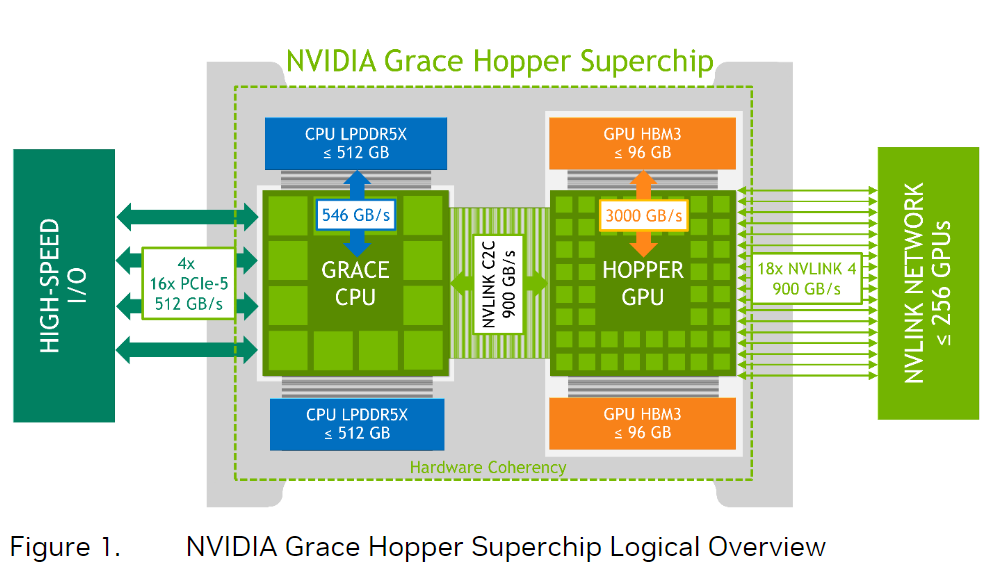
在nvlink c2c的帮助下,应用程序可访问的内存不止gpu所提供的96gb,可用的还有来自grace cpu的内存,每一个grace hopper superchip可提供{banned}最佳多512gb的lpddr5x的cpu内存。加起来就是512 96=608gb!
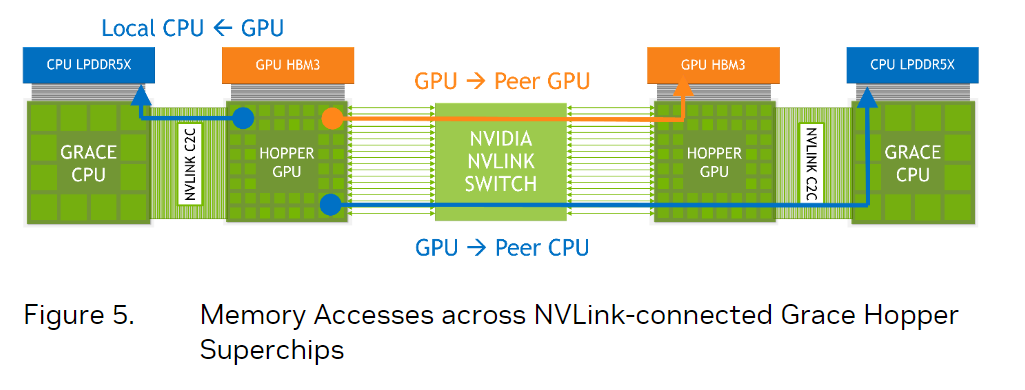
另外,nvlink c2c还支持nvlink switch system,这使得一块hopper gpu不仅可以访问本地grace cpu的内存,还能透过交换机访问远端的hopper gpu以及远端的grace cpu的内存。也就是说,每一个hopper gpu都可以访问集群里的所有内存。值得注意的是,nvlink switch和nvlink c2c的带宽一样是900gb/s的,这为跨节点的内存访问一致性提供了基础。由于nvlink可连接{banned}最佳多256张grace hopper superchip,算下来,{banned}最佳多可以访问150tb(256x608gb)的内存。
总之,nvlink c2c能让应用程序能够更容易地直接读取、储存数据,更方便地进行原子操作,有助于处理更大、更复杂的问题。有了grace hopper超级芯片,与之对应的就有相关的dgx和hgx产品。
dgx gh200
nvidia此前的 dgx a100 系统只能将八个 a100 gpu 联合起来作为一个单元,面对生成式人工智能大模型对于算力的爆炸式增长,nvidia的客户迫切需要更大、更强大的系统。dgx gh200就是为了提供{banned}最佳大的吞吐量和可扩展性而设计的。
如下图所示,dgx gh200通过定制的nvlink switch system(包含 36 个 nvlink switch)将256个gh200超级芯片和高达144tb的共享内存连接成一个单元,避免标准集群连接选项(如 infiniband 和以太网)的限制,这种新的互连方式使dgx gh200系统中的256个h100 gpu作为一个整体协同运行,使其成为了专为{banned}最佳高端的人工智能和高性能计算工作负载而设计的系统和参考架构。可支持数万亿参数ai大模型训练。

dgx gh200系统中的每个grace hopper superchip 都与一个nvidia connectx-7网络适配器和一个nvidia bluefield-3 nic配对。dgx gh200 拥有 128 tbps 对分带宽和 230.4 tflops 的 nvidia sharp 网内计算,可加速 ai 中常用的集体操作,并通过减少集体操作的通信开销,将 nvlink 网络系统的有效带宽提高一倍。connectx-7 适配器还可以互连多个dgx gh200 系统,以扩展到超过256个gpu的更大的凯发app官方网站的解决方案。此外nvidia也{banned}中国第一次使用 nvlink switch 拓扑结构来构建整个超级计算机集群,之前nvlink switch只是以芯片形式在主机内,而在dgx gh200中nvlink switch也被实现为交换机形式,负责多级gpu互联,这种结构提供了比前一代系统高出10倍的gpu到gpu带宽,以及7倍的cpu到gpu的带宽。
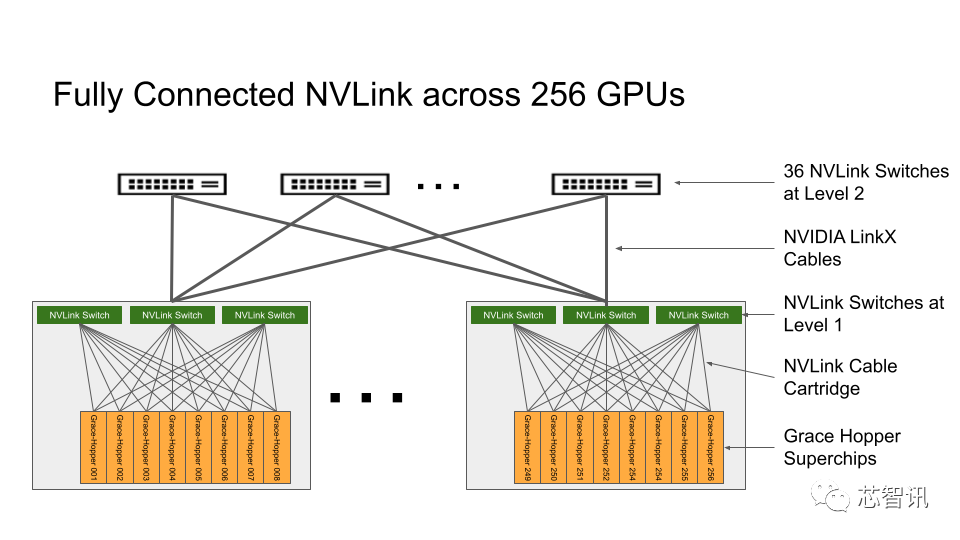
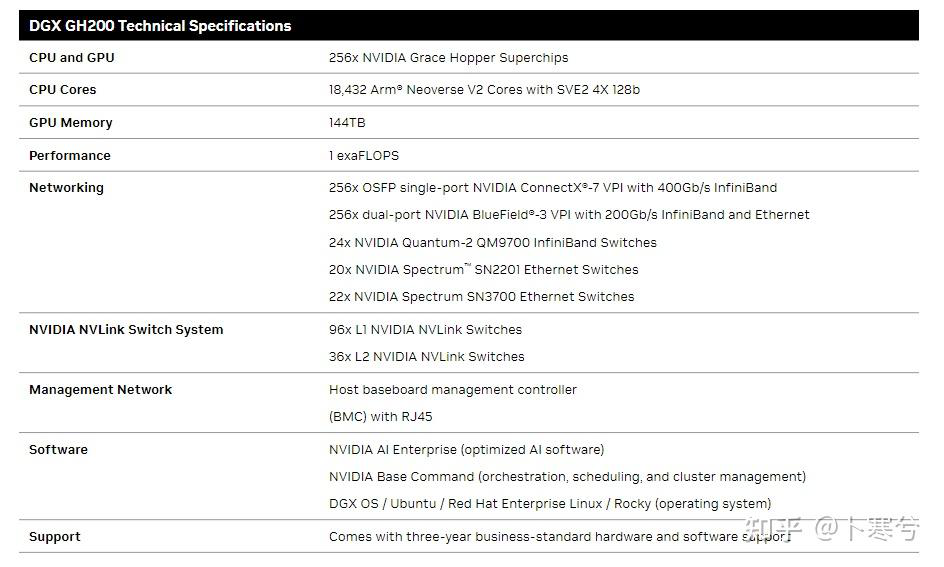
下表是dgx gh200的配置,总之dgx gh200对标的dgx a100,可以将dgx gh200看做一个大的gpu芯片。
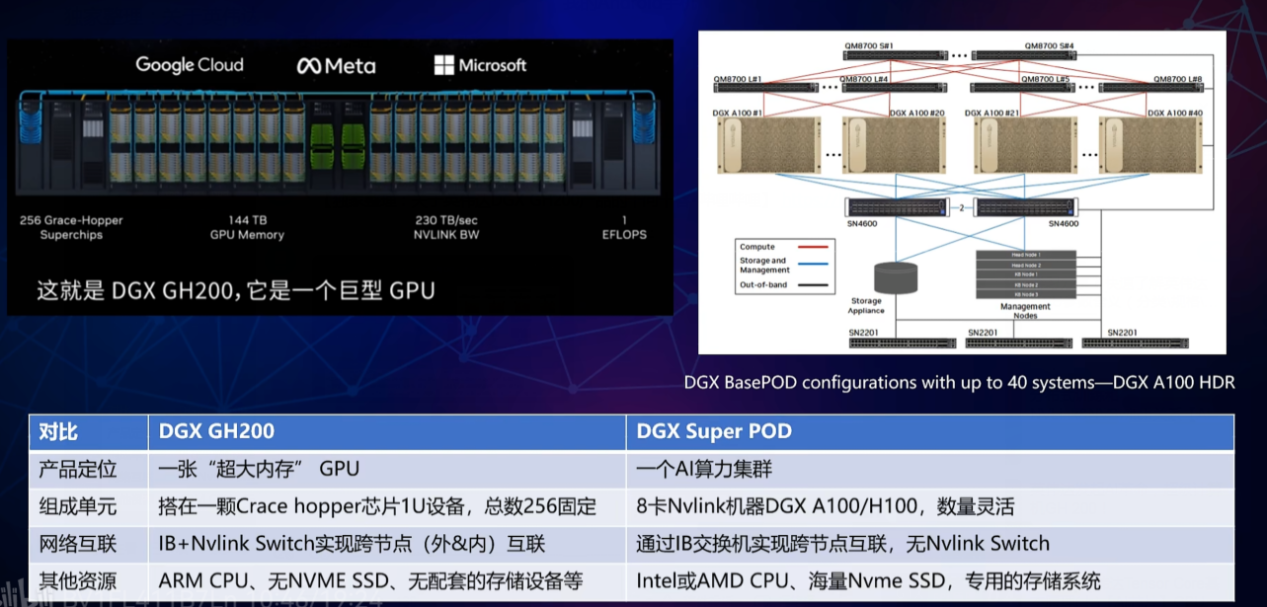
那么dgx gh200和上文介绍的dgx superpod在产品定位有什么不同呢?下图是一个总结,核心是dgx gh200只是gpu的固定组合(256),而dgx superpod是一个集群。
hgx gh200
类似dgx产品,hgx grace hopper每个节点都有一个grace hopper超级芯片,与bluefield-3 nic或oem定义的i/o以及可选的nvlink switch系统配对。

上图展示的是基于grace hopper superchip的一个hgx grace hopper superchip节点,单节点的tdp高达1000瓦,风冷散热和水冷散热都行。这么一个东西要怎么用呢?大体上有两种组织形式:
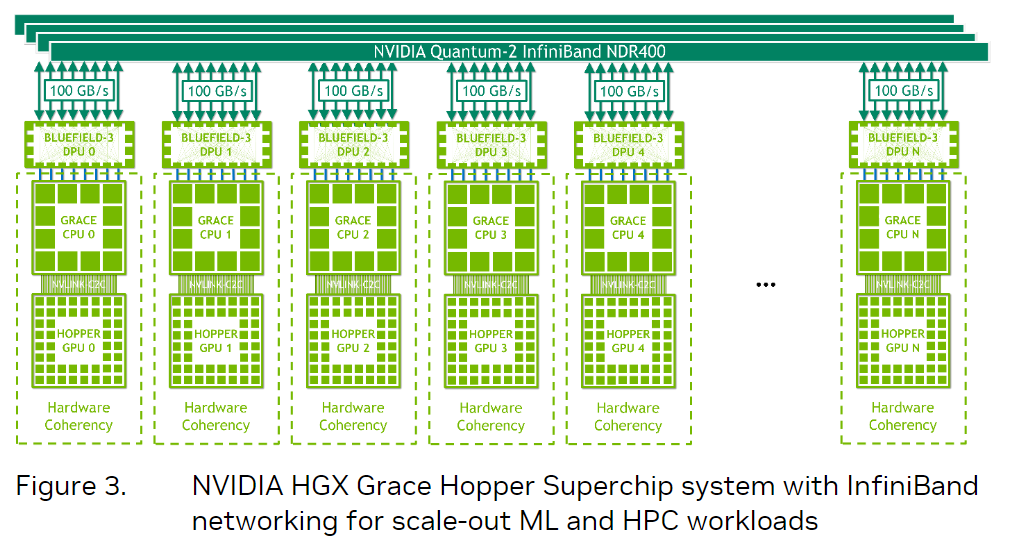
{banned}中国第一种是只用infiniband,配合英伟达的bluefield-3 dpu,本质上还是传统的rdma加速网络,这种适合横向扩展的机器学习和高性能计算工作负载。每个节点包含一个grace hopper superchip和一个或多个pcie设备,例如nvme固态驱动器和bluefield-3 dpu、nvidia connectx-7 nic 或oem定义的i/o。ndr400 infiniband nic具有16个pcie gen 5通道,可在超级芯片上提供高达100 gb/s的总带宽。结合nvidiabluefield-3 dpu,该平台易于管理和部署,并使用传统的hpc和ai集群网络架构。
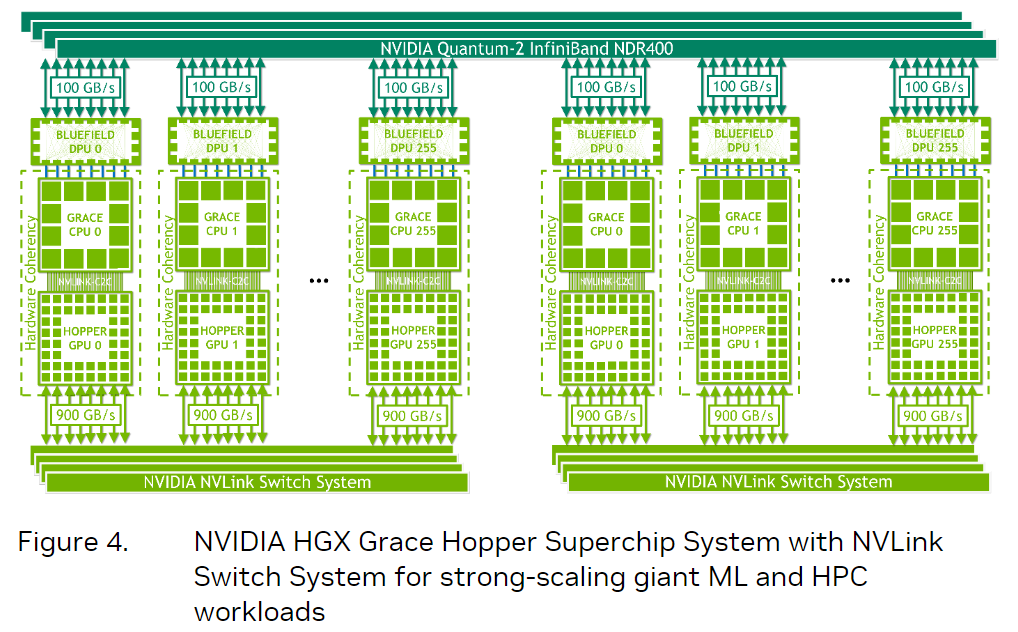
另一种,在用了infiniband的基础上,还在显卡那一头用nvlink switch system把显卡连在了一起,这种连接256个grace hopper superchip的完全体适合用来解决世界上规模{banned}最佳大,{banned}最佳具挑战性的ai训练和hpc工作负载。
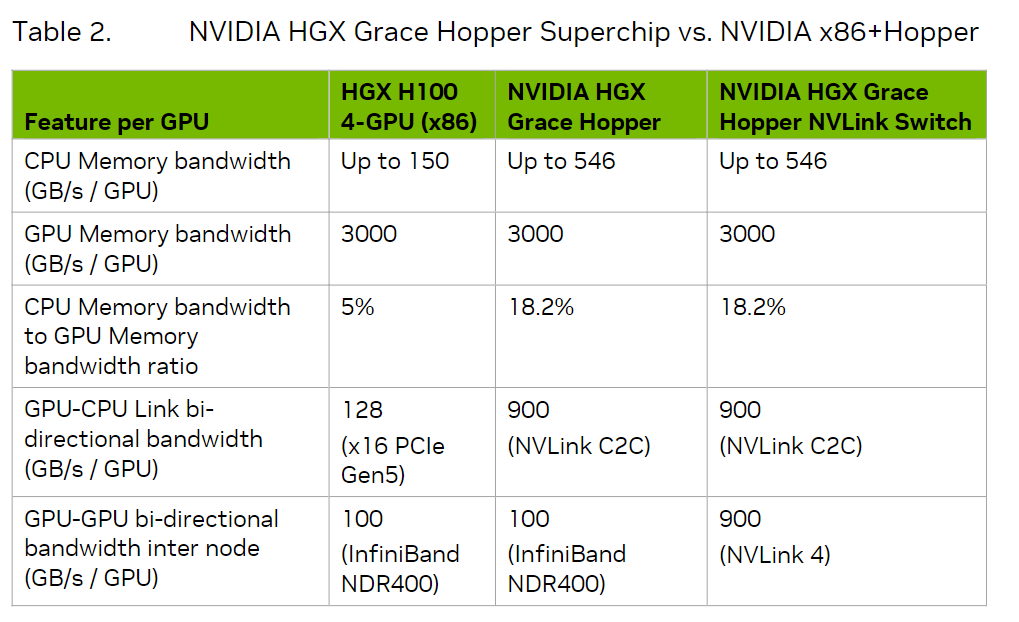
上图对比了cpu 显卡传统组合,grace hopper一体的组合以及配上了nvlink switch的grace hopper三者之间的对比。对比之下,cpu-gpu靠16通道的pcie 5.0连接的速度与有了nvlink c2c的grace hopper相比实在是太慢了。而gpu-gpu之间通过infiniband的传输速度跟基于nvlink 4的nvlink switch相比,也差距甚远。
总之,hgx gh200给了服务器厂商一定灵活性,选择是否使用nvlink switch,以及采用多少个节点。
mgx
nvidia dgx 面向{banned}最佳高端市场的ai系统,hgx 系统则是面向超大规模数据中心,此次nvidia还新推出了介于这两者之间的的nvidia mgx 系统。
nvidia 表示,其oem凯发k8官网下载客户端中心的合作伙伴在为 ai 中心设计服务器时面临着新的挑战,这些挑战可能会减慢设计和部署的速度。nvidia 的全新 mgx 参考设计架构旨在加速这一过程,可以将开发时间缩短2/3至仅需6个月,开发成本也可以减少3/4。

据介绍,mgx 系统由模块化设计组成,涵盖了 nvidia 的 cpu 和 gpu、dpu 和网络系统的所有方面,但也包括基于通用 x86 和 arm 处理器的设计,拥有100 多种参考设计。nvidia 还提供风冷和液冷设计选项,以适应各种应用场景。

asrock rack(永擎)、华硕、gigabyte(技嘉)、和硕、qct、超微(supermicro)都将使用 mgx 参考架构来开发将于今年晚些时候和明年初上市的系统。