将晦涩难懂的技术讲的通俗易懂
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
分类: linux
2023-11-18 21:39:07
snap:基于微内核的主机网络-凯发app官方网站
snap是google研发的一个基于微内核的主机网络框架,发表在sosp ’19(《snap: a microkernel approach to host networking》)。snap也是google 内部多个网络系统的基础,了解snap可以更加清晰的认识google内部其他相关系统的实现。例如将以下三篇论文结合起来可以更清晰的了解google主机网络的实现:
《andromeda: performance, isolation, and velocity at scale in cloud network virtualization》 2018 nsdi
《snap: a microkernel approach to host networking》 sosp ’2019
《picnic: predictable virtualized nic》 sigcomm ’2019
snap是什么?
snap是google研发的一个基于微内核的主机网络框架,这个网络框架包括多种功能,比如边缘数据包交换、云平台的虚拟化、流量整形策略执行,以及高性能可靠消息传递和类rdma服务等。snap的架构是囊括用户空间网络、在线升级、集中式资源统计、可编程数据包处理、内核绕行rdma功能、以及传输、拥塞控制和路由的优化设计等{banned}最佳思想的组合。
按照论文中的说法,snap已经在google生产环境中运行了三年(2016~2019),支撑了多个关键系统的可扩展通信需求。并且应用于多个生产系统中,如包括用于云虚拟机的网络虚拟化(andromeda的host switch,2018‘nsdi),用于互联网对等连接的数据包处理,可扩展的负载均衡(maglev,2016’nsdi),以及pony express,一个可靠的传输和通信栈(这部分将在后续介绍)。
而本篇论文主要介绍了两个方面,一是snap这个网络框架的整体架构和实现,二是着重讲了其中高性能协议栈pony express的实现。下面看一下论文的具体内容。
snap的背景
随着互联网的发展,主机网络需求日益增加,使用传统基于内核的网络技术在实现这些需求时遇到了许多问题:
1. 开发周期长:开发内核代码的速度较慢,熟悉内核开发相关的人员有限;
2. 运维效率低:内核发布周期较长,且通常需要断开应用程序的连接或重启物理机;
3. 优化空间小:linux的广泛通用性使得优化变得困难,因为任何改变都需要考虑现有各种系统的兼容性和通用性;
snap整体架构
微内核架构
如下图所示为一版网络框架的几种实现方式:
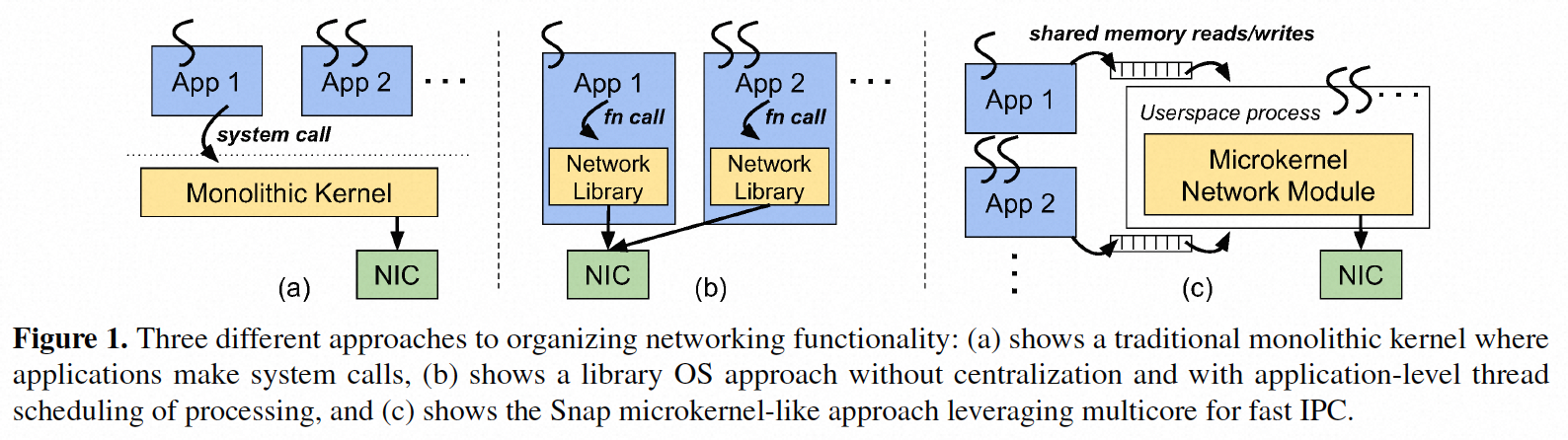
(a) 是传统内核网络架构,优点是对网络处理集中在内核网络系统管理,缺点如前所述,主要是开发和运维效率低,且优化空间小;
(b) 是网络lib库的方式,通过应用程序集成相应的lib库实现网络部分的替换,其优点是用户态开发,开发效率高;
(c) {banned}最佳后就是snap采用的微内核方案,首先它结合了方法(a)的集中化优势和方法(b)的用户空间开发优势;其次,新网络功能的发布与内核和应用程序二进制发布周期解耦;第三,与方法(b)中实现低延迟但通常依赖于应用程序polling的实现不同,方法(c)将应用程序线程和网络服务解耦。这对于通常运行数十个独立应用程序的主机系统至关重要。
snap仍然保持了微内核的优势,即网络组件与其他内核组件之间的地址空间隔离,提升开发者发布速度,因为在开发和测试过程中发现的错误不会导致机器崩溃,以及集中化,可以实现丰富的调度和管理策略,而传统的绕过操作系统的网络系统则不具备这些优势。而snap的微内核架构和传统微内核也有不同之处,主要表现在以下几个方面:
● snap利用多核硬件进行快速进程间通信(ipc);
关于这一点文中没有详细展开,只是说“早期的微内核工作发现,由于进程间通信(ipc)和地址空间更改,存在显著的性能开销,现代处理器中的标记tlb支持技术、随着虚拟化和ipc优化技术的进步,现代微内核基本上消除了直接系统调用和通过ipc进行间接系统调用之间的性能差距。”
● 不需要完整替换现有内核,因为snap只是作为一个用户空间进程与标准linux内核一起运行,不会影响应用对标准内核的依赖和使用;
● 支撑和linux标准内核通信(类似dpdk kni):snap支持一种内部开发的驱动程序,用于在snap和内核之间高效地传输数据包;
snap整体设计
下图显示了snap的架构以及它与外部系统的交互设计。snap整体分为“控制平面”(左侧)和“数据平面”(右侧)两部分。其中引擎(engines)作为数据平面操作的封装单元,图中给出了三个示例,分别是virt engine,pony engine和shaping engine。其中virt engine就是应用于google andromeda的host vswitch部分,发表于2018年nsdi;shaping engine是应用于发表于2015年的acm sigcomm会议上的《bwe: flexible, hierarchical bandwidth allocation for wan distributed computing》,这篇论文介绍了一种名为bwe的灵活、分层的广域网分布式计算带宽分配方法。在广域网环境下,不同计算任务的带宽需求是不同的,而传统的带宽分配方法通常采用固定的或静态的方式,无法有效适应动态的需求变化。因此,该论文提出了一种新的方法来解决这个问题;{banned}最佳后pony engine作为有状态高性能网络后面会重点介绍。
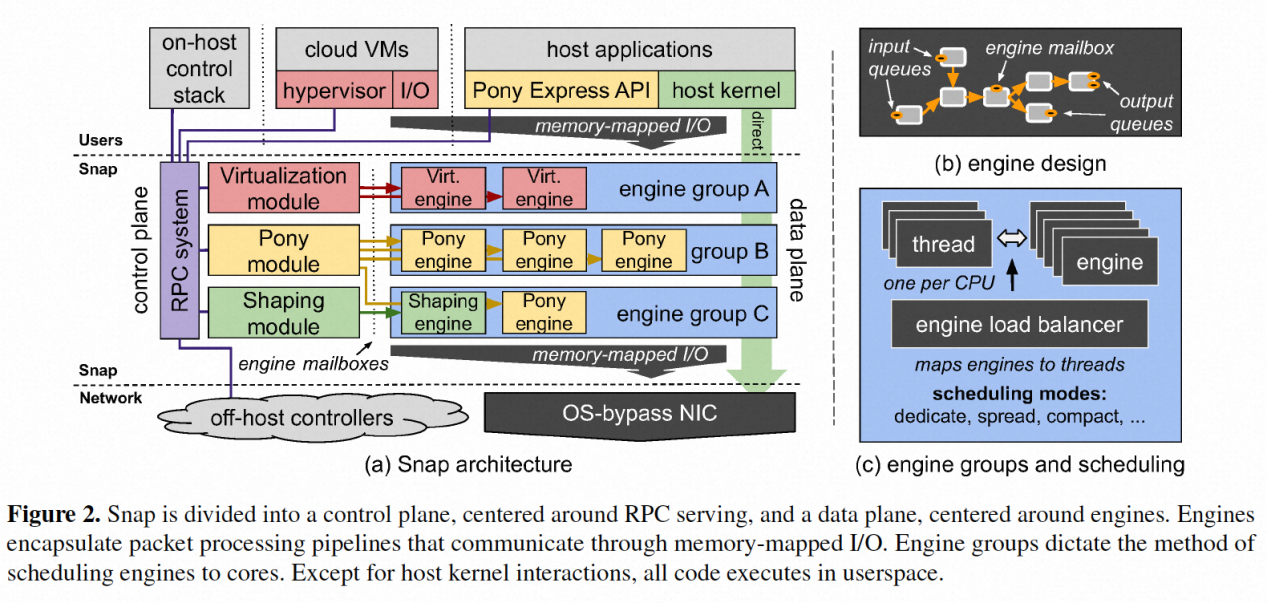
图2(a)还说明了在不同组件类型之间使用的不同通方式:在左侧,控制平面组件与外部系统之间的通信通过rpc进行编排;在右侧,数据平面组件之间的通信通过内存映射i/o进行;在中间,控制平面和数据平面组件通过一种称为引擎邮箱(engine mailbox)的单向rpc机制进行交互。{banned}最佳后,图上还显示了由多个engine构成的engine group作为一个共享“调度策略”的调度组。
引擎(engine)的设计原则
引擎(engines)是有状态的单线程任务,由snap runtime进行调度和运行。snap为引擎开发者提供了裸金属编程环境,包括kernel bypass、qos、acl、协议处理、优化后的一些lib库,以及click风格的插件式“元素”库,用于构建数据包处理流水线。
备注:所谓“click”是指论文题为"the click modular router"(发表于1999年的acm sosp会议上)提出的。该论文介绍了click模块化路由器,这是一种灵活且可扩展的路由器架构,传统的路由器通常使用固定的硬件和软件组件,限制了其灵活性和可定制性。而click路由器通过使用模块化的设计,可以根据具体需要配置和连接各种功能模块。click路由器由一系列模块组成,每个模块负责特定的功能,例如数据包处理、路由选择、队列管理等。这些模块通过连接器相互连接,形成数据包处理流水线。通过重新组合和定制这些模块,可以根据具体需求构建不同类型的路由器。
总结一下就是,snap提供了类似vpp一样,即提供了底层类似dpdk的各种kernel bypass能力和多种网络lib库,也提供了plugin的框架和一些预置常用的plugin。
图2(b)显示了snap engine的具体结构以及它通过队列和mailbox与外部系统的交互。引擎(engine)的输入和输出可以包括用户空间和客户应用程序、内核数据包ring、nic接收/发送队列、线程和其他engine。在这些情况下,engine的通信通过与输入或输出共享的内存映射区采用无锁方式进行,偶尔引擎还可以通过中断传递与输出进行通信(例如通过写入类似eventfd的结构)来通知任务的到来,而在某些引擎调度策略下,还可以在输入上接收中断。从snap框架的角度来看,引擎开发者的任务是确定需要多少个引擎,如何实例化这些引擎(静态或动态),以及如何在引擎之间分配工作,不过本文的重点不是这个。
模块(modules) 及控制面到引擎的通信
snap中的模块(modules)负责执行响应控制平面的rpc服务,创建/销毁引擎(engine),将加引擎载到引擎组中,并代理所有用户应用设置与这些引擎的交互。例如,对于pony express,图2(a)中显示的“pony模块”通过在本地rpc系统上交换文件描述符来验证用户并设置与用户应用程序共享的内存区域。它还处理其他对性能不敏感的功能,如兼容性检查和策略更新。
上述服务中的一些控制操作,如设置用户命令/完成队列、共享内存注册、轮换加密密钥等,需要控控制面与引擎进行同步。为了支持snap的实时高性能要求,控制面通过引擎邮箱(engine mailbox)与引擎无锁同步。该mailbox是一个深度为1的队列,每次控制面只会post一小段耗时短的任务给引擎上的一个线程同步执行, 从引擎来看它是非阻塞的。
引擎组的调度策略
上文提到引擎组(engine group)是采用同一种调度策略的一组引擎。而snap一共提供了三种调度策略,如下图所示:
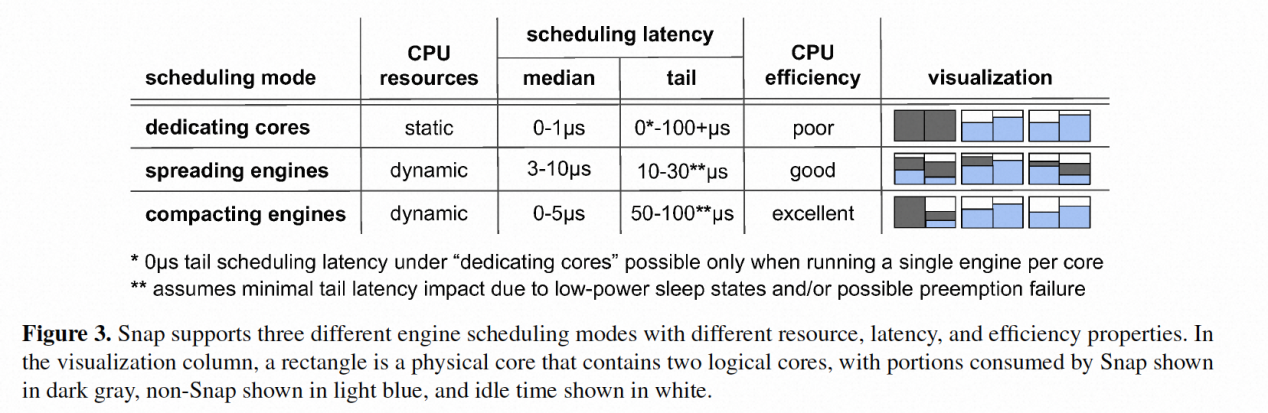
dedicating cores(专用核心)
这种模式下,引擎被固定在某个专用的ht上(类似dpdk的polling模式),其它线程不能在这个ht上运行。它可以通过spin-polling来{banned}最佳小化延迟并且可以使用mwait节省电力。但由于是静态配置,可能出现负载增高后不够或者负载低过度配置资源浪费的情况。
spreading engines(分布引擎)
这种方式即我们熟悉的中断方式,他的好处是{banned}最佳小化调度的尾延迟。具体方法是将每个引擎绑定到唯一的线程,仅在活动时调度,并在空闲时阻塞中断通知。然后,通过从nic或应用程序通过系统调用触发中断来调度引擎。在足够数量的可调度核心下,这种模式可以提供{banned}最佳佳的尾延迟特性。不过,使用中断模式时,有系统级的干扰效应必须仔细管理,如当线程被调度到处于低功耗睡眠状态或正在运行非可抢占内核代码的核心时可能出现的一些可调度性挑战。
compacting engines(集中引擎)
这种模式将工作合并到尽可能少的核心上,结合了中断模式的扩展性优势和polling模式专用核心的缓存效率优势。不过,它依赖于定期轮询引擎的排队延迟来检测负载不平衡,而不是像上面的“分布引擎”调度模式那样依赖于即时中断信号。因此,重新平衡的速度受到轮询这些排队延迟的延迟的限制,在我们目前的设计中,这是非抢占式的,并且需要引擎任务在固定的延迟预算内将控制权返回给调度器。
在实现方面,这种调度模式在单个线程上执行引擎,同时采用类似于shenango算法来测量由于cpu瓶颈引起的队列延迟,并通过调度保证其在预先配置的服务等级目标(slo)之下。具体实现是,通过将一个引擎扩展到另一个线程,或者当负载足够低时缩配迁回到原有线程的方式,来确保在特定的slo下{banned}最佳大幅度的提高执行效率。该算法通过直接访问内存中并发更新的变量来估计引擎执行排队的负载,随后的任何负载平衡决策都通过mailbox消息传递机制直接与受影响的线程同步。当然对于很轻的负载,它也支持采用中断唤醒的机制。
microquanta内核调度类
为了动态扩展cpu资源,snap和一个名为microquanta的新的轻量级内核调度器一起工作。该调度器提供了一种灵活的方式来应对延迟敏感的snap引擎任务和其他任务之间共享内核,限制对延迟敏感的任务的cpu配额,同时保持较低的调度延迟。
microquanta线程在每个周期时间单位内运行一段可配置的运行时间,剩下的cpu时间可供其他使用公平排队算法的cfs调度任务使用,用于处理高优先级和低优先级任务(而不是更传统的固定时间片)
pony express高性能协议栈
pony express是google基于snap架构自研的一个类似rdma的高性能传输协议,它实现了可靠性、拥塞控制、可选的排序、流量控制和远程内存访问。
pony express并不是重新实现的tcp/ip,也不是基于现有协议的修改,而是从头开始开发,在接口、架构和协议上都进行了创新。pony express的应用程序接口基于异步操作命令实现,而不是基于数据包级别或字节流的socket接口。pony express既实现了(双向的)消息操作,也实现了单向操作,其中rdma是一个例子。单向操作不涉及任何远程应用程序线程的交互,从而避免为远程数据访问调用应用程序线程调度器。
linux tcp协议栈试图将传输处理和应用程序的cpu维持亲和性在一个核上处理,而pony express则通过snap和应用程序将cpu分离在不同的线程中处理(因为snap和应用线程是在不同线程中的),snap将pony express的引擎线程和pcie连接的网卡做numa亲和性调度。pony express主要与其它传输相关的snap引擎共享cpu核,而不是应用程序的核,这样能够更好的支持批处理/代码局部性/减少上下文切换并通过spin-polling减少延迟。总体的设计原则是,将传输与应用分离,使得传输层和网卡numa亲和性获得更好的局部性。
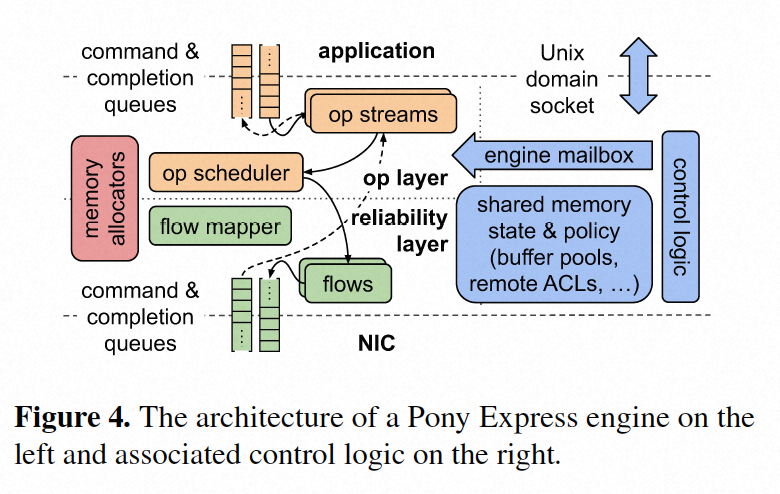
架构设计
pony express的架构如下图所示,客户端程序通过unix socket和pony express通信,unix socket主要通过传递tmpfs的fd来实现应用程序和pony express之间引导共享内存(mr)。其中一个这样的共享内存区域实现了用于异步操作的命令队列(command queue)和完成队列(completion queue)。当应用程序将命令写入command queue,然后通过polling completion queue 或者注册一个线程接收通知。其它的mr用于应用程序实现零拷贝的数据请求/响应数据交互。
pony express实现了自定义内存分配器,以优化动态创建和管理状态,包括流(streams)、操作(operations)、flows、packet memory和application buffer pools。
关键实现
传输设计
pony express将其传输逻辑分为两个层次:上层实现应用层操作的状态机,下层实现可靠性和拥塞控制。下层通过网络实现一对引擎之间的可靠的流传输,通过flow mapper将其和应用程序关联在一起。此外,这个下层仅负责可靠地传递单个数据包,而上层则处理特定操作的重排序、重组和语义。pony express中使用的拥塞控制算法是timely的一个变种,并运行在专用的网络qos class上。快速部署新版本的pony express的能力显著促进了拥塞控制的开发和调优。尽管我们每周发布一次版本,使得这个时间范围很小,但我们仍然需要在升级时确保向后兼容性。我们目前使用一个带外机制(tcp套接字)在连接到远程引擎时广告可用的传输协议版本,并选择{banned}最佳小公共分母。一旦机群变更完成,我们随后删除未使用版本的代码。
引擎操作
pony express引擎服务于接收传入的数据包,与应用程序进行交互,运行状态机以推进消息和单向操作,并生成传出的数据包。在轮询nic接收队列时,处理的数据包数量是可配置的,以便在延迟和带宽之间进行权衡,当前的默认值是每批处理16个数据包。类似地,轮询应用程序命令队列也使用可配置的批处理大小。引擎根据来自应用程序的传入数据包和命令,以及nic的available desc个数,生成用于传输的新数据包。之所以要基于nic的available desc个数实时生成数据包,是确保我们只在nic能够传输它们时生成数据包(引擎中不需要逐个数据包排队)。
使用pony express的应用程序可以要求自己独占的引擎,或者可以使用一组预加载的共享引擎。如前所述,引擎是snap中的调度和负载平衡单元,因此,对于独占引擎的应用程序,可以获得更强的性能隔离,但可能会付出更高的cpu和内存成本。当强隔离性较不重要时,应用程序可以使用共享引擎。
单向操作
单边操作不涉及目标上的任何应用程序代码,而是完全在pony express引擎上执行完成的,这样避免了调用应用程序线程带来的调度/通知等延迟,大大的提高了cpu的效率并降低了尾延迟,和rdma类似,应用程序必须显式的共享内存,并起让snap共享内存供远端的pony express引擎操作,单边操作在snap的地址空间内执行,应用程序通过polling和双边操作的协同来进行。
pony express的软件灵活性使其能够支持除了基本的远程内存读写操作外更丰富的操作,例如,支持一个自定义的间接指针读操作。与基本的远程读取相比,间接读取在数据结构需要单个指针间接时有效地使操作速率翻倍并将延迟减半。另一个自定义操作是扫描和读取,它扫描一个小的应用程序共享内存区域以匹配一个参数,并从与匹配相关联的指针获取数据。这些操作在生产系统中被使用。
消息传递和流量控制
pony express提供了用于rpc和非rpc用例的send/recv消息操作。与http2和quic一样,我们提供了创建消息流的机制,避免不同消息间的hol阻塞。而流控基于接收端驱动的buffer posting和使用credit管理的共享缓冲池混合的策略,而不是基于tcp的每个连接的接收窗口机制。 但是针对单边操作的流控会比较复杂,应用程序不感知所以无法控制,而只能采用snap中针对cpu和内存资源的计量来限制(类似picnic中描述的方式),当用户使用pony express后会实例化一个pony express引擎, 通过公平调度实现,但是单边操作无法简单的丢弃,因此需要采用拥塞控制和cpu调度机制来解决,而不是实现其他高级的流控机制来实现公平共享。
硬件卸载
在硬件卸载方面,pony express利用无状态卸载,包括intel i/oat dma设备来卸载内存复制操作。pony express还利用其他无状态nic卸载;一个例子是对每个数据包进行端到端不变的crc32计算。
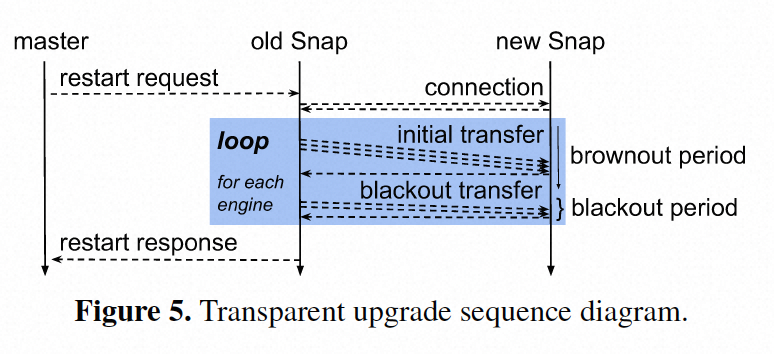
透明升级
snap的用户态设计方便了对齐进行升级,具体来说,在升级过程中,snap的运行版本将所有状态序列化为存储在与新版本共享的内存中的中间格式。与虚拟机迁移一样,升级是两个阶段的,以{banned}最佳小化断网时间和对性能影响{banned}最佳小。我们的目标是将中断时间控制在200毫秒或更短的时间内,为了实现这个目标,snap会逐步进行升级,逐个迁移引擎,每个引擎都是完整的。随着在生产环境中运行的引擎数量增加,这种方法变得必要,以保护单个引擎免受由于传输其他引擎而导致的长时间中断。除此之外,通过对集群进行渐进式升级,我们发现我们现有的应用程序在每周发生的百毫秒通信中断中几乎察觉不到。在这个中断期间可能会发生数据包丢失,但端到端传输协议会将其视为由于拥塞导致的数据包丢失。下图说明了升级流程。
首先,snap的“主”守护进程启动第二个snap实例。正在运行的snap实例连接到新实例,然后,逐个引擎,暂停控制平面unix域套接字连接,并将它们与共享内存文件描述符句柄一起在后台传输。这是使用unix域套接字的附属fd传递功能完成的。在传输控制平面连接时,新的snap重新建立共享内存映射,创建队列、数据包分配器和与引擎的新实例相关的各种其他数据结构,而旧的引擎仍在运行。完成后,旧的引擎通过停止数据包处理、分离nic接收过滤器和将剩余状态序列化为tmpfs共享内存来开始中断期。然后,新的引擎附加相同的nic过滤器并反序列化状态。一旦所有引擎都以这种方式传输完,旧的snap就会被终止。
再看andromeda
看完snap在看google的andromeda就更加清晰了,尤其对于host vswitch部分。首先andromeda的host vswitch部分就是基于snap框架实现的,如下图所示,其中vswitch的业务处理部分就是snap中的virt engine。其中fastpath部分采用类似于click一样,有一些可重用的elements组成,也是snap的特点。这里要说明的是,很多人会将其中的coprocessor认为是slowpath,这个理解是不正确的,slowpath是图中的vswitchd,而upcall流量至vswitchd上会经过coprocessor,coprocessor的核心是处理一些消耗cpu的复杂的工作。
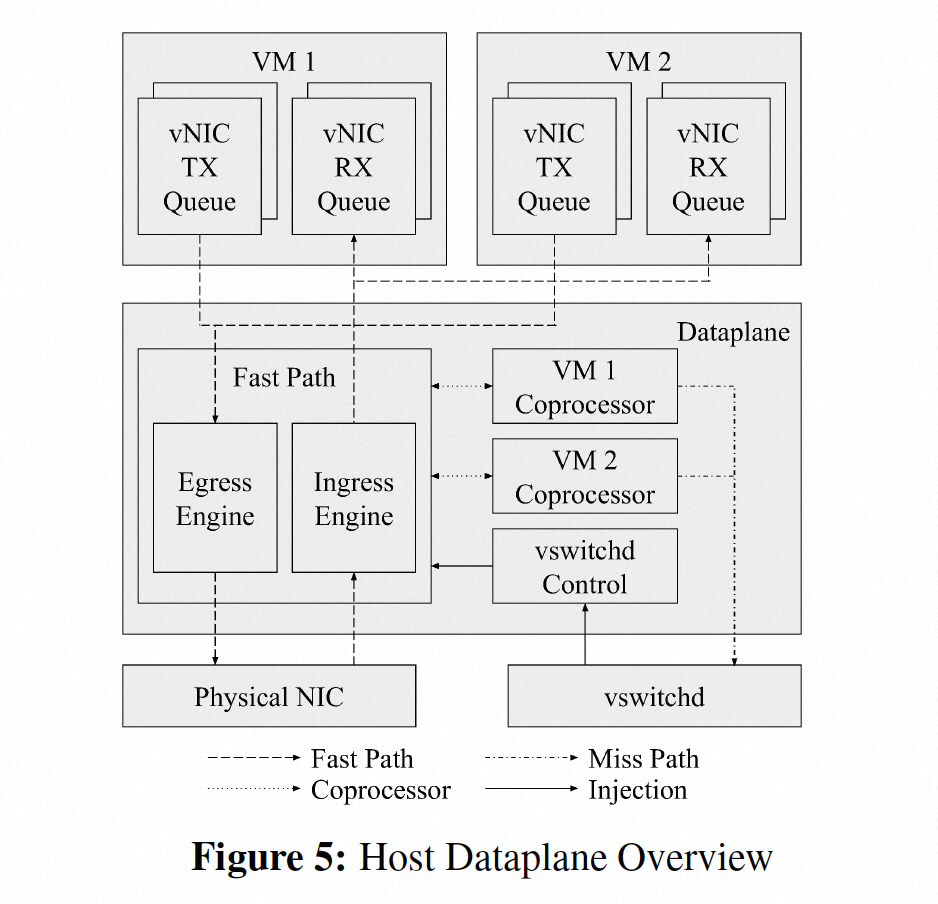
举个例子,报文的分片重组比较消耗cpu,这个逻辑就可以交给专门的coprocessor处理。这样做有两个好处,一是让fast path尽量的简单,毕竟不是所有流量都需要分片重组的;第二个是起到一定资源隔离的效果,因为fast path是所有vm共享的,试想如果分片重组在fast path,那么一个vm发送大量分片报文,无疑会消耗过多资源影响其他vm,andromeda论文中提到,coprocessor是消耗的vm的cpu,结合snap的架构可知,coprocessor也是一个独立的engine,并且每个vm对应一个,snap将其调度到对应vm所在的cpu即可,这样每个vm网络开销大的网络处理本质上是消耗vm自己的cpu(当然用户观察不到)。
不过以上资源隔离的效果仅在host模式比较有效,如果采用了智能网卡(ipu),vswitch在网卡上就不方便这么做了,当然google也picnic这篇论文也给出了对应凯发app官方网站的解决方案。
总结
本文重点介绍了google的snap网络处理框架,一方面类似于dpdk vpp实现了用户态转发的高性能以及可编排,另一方面也提供了自己内部的调度机制,负责转发工作(engine)的调度。此外着重介绍了其自研高性能协议栈pony express,在只有采用ipu架构后也即演进到了今天的falcon。