将晦涩难懂的技术讲的通俗易懂
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
分类: linux
2024-05-12 23:45:41
rdma中的load balance技术-凯发app官方网站
网络中的拥塞整体可用分为两种,如下图所示,{banned}中国第一种是在端侧的拥塞(endpoint congestion),常见于多打一的incast场景,这种方式通常就要看各种各样的cc算法来使对应的发送端减速来解决。另一种就是fabric congestion,即网络中因为hash不均导致的拥塞。
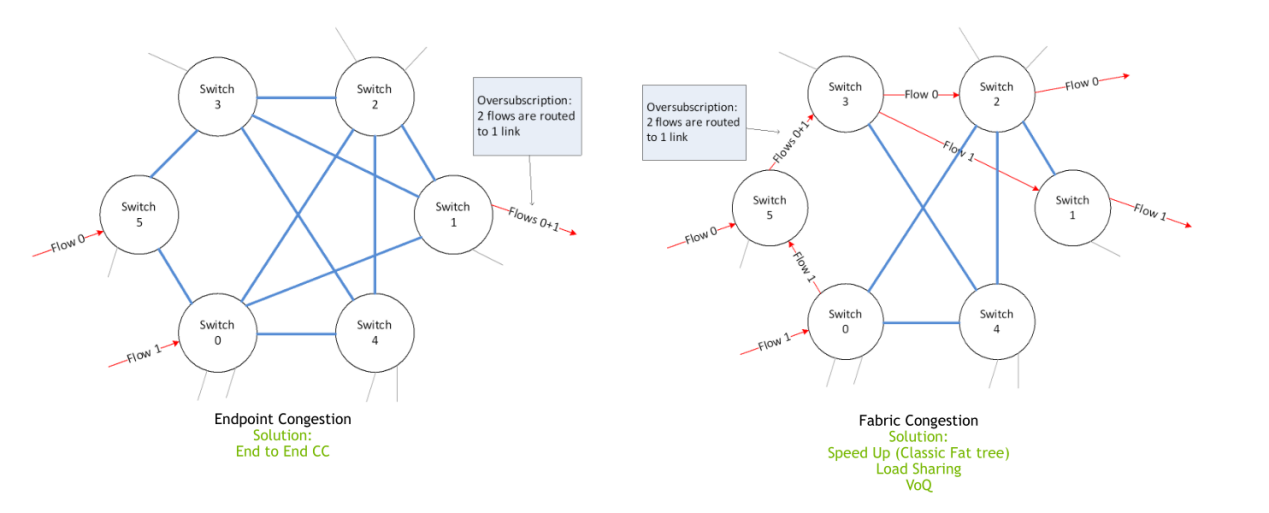
另一种就是voq这种方式,voq(virtual output queueing)是一种网络拥塞管理技术,用于防止hol阻塞(head of line blocking)的技术。在传统的输入缓冲区排队(input-buffered queueing)方案中,数据包先进入输入缓冲区,然后根据目的端口的可用性从中选择出队。如下图所示:
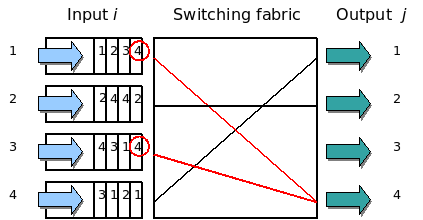
然而,当多个数据包的目的端口相同时,输入缓冲区排队会导致阻塞和拥塞,上图output 4发生拥塞会导致input 1和 input 3发往其他队列的报文也堵塞。
voq技术通过为每个输出端口创建虚拟的输出队列,将输入数据包直接放入对应的虚拟输出队列中。这样,在数据包进入路由器或交换机时就可以直接选择适当的虚拟输出队列,而无需等待目的端口的可用性。因此,voq技术可以避免输入缓冲区排队可能引起的阻塞和拥塞问题,提高网络的吞吐量和性能。
而第三种思路就是对流量进行load balance,而流量load balance按照粒度不同可以分为以下四种方式:cell based,paket based,flowlet,flow based。
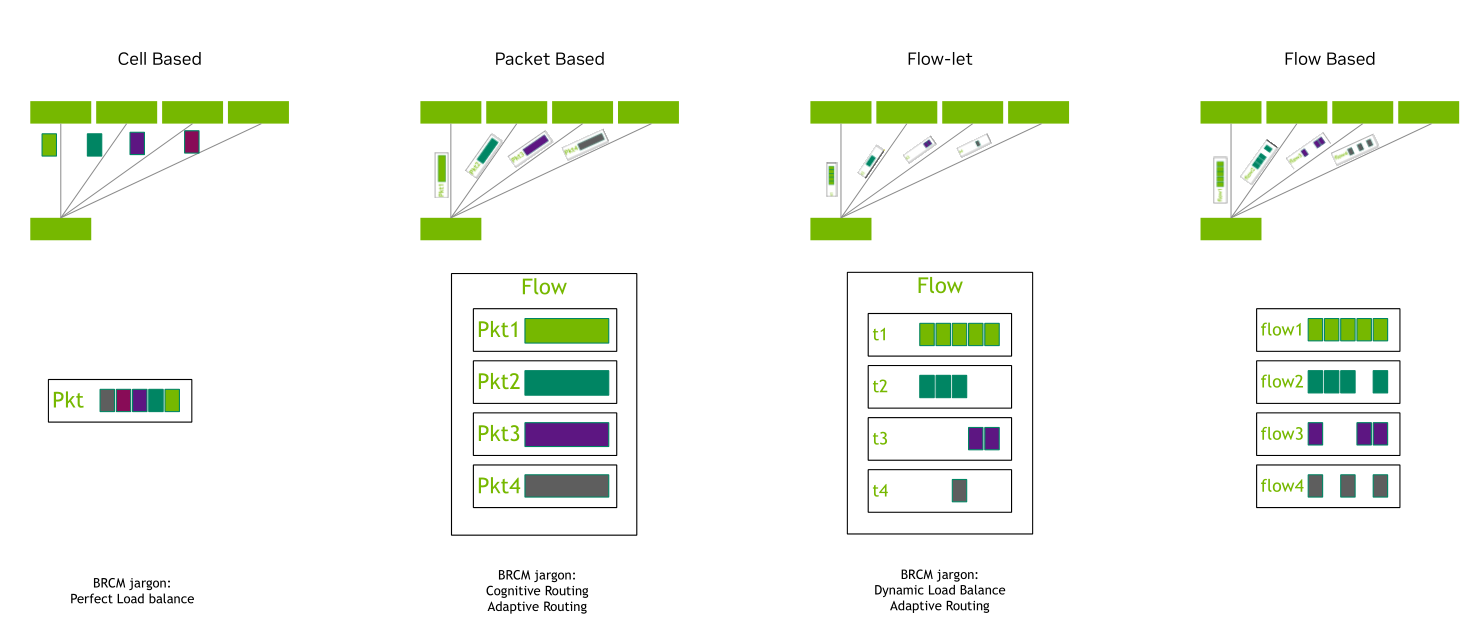
l cell based
这种方式是{banned}最佳细粒度的,就是将一个报文分成多个大小相等的小块打散传输,理论上可以{banned}最佳高的充分利用带宽。信元(cell)交换本身并不是一项崭新的技术,在目前广泛应用的框式设备中,线卡芯片与网板芯片之间的流量交换普遍都采用了信元交换的技术,以实现机框内无阻塞交换。不过信元交换以前主要应用在框式设备系统内部,往往都是各个交换机设备厂商自定义的信元格式和调度机制,不具备跨厂商互通的能力,此项技术可以进一步扩展,应用到整个网络上。2019年at&t向ocp提交了基于商用芯片的盒式路由器规范,提出了ddc(disaggregated distributed chassis)的概念,ddc使用的核心技术也是信元交换的方案。
但由于实现的复杂性,cell based常见于设备内部使用,对外透明。同时信元交换,对报文的切片、封装和重组,同样增加网络转发时延。通过测试数据比较,ddc较传统eth网转发时延增大1.4倍。显然不适应ai计算网络的需求。
l paket based
packet based就是通过逐个报文打散来实现负载均衡,充分利用带宽。但是逐包打散多路径不可避免的会导致同一条流产生乱序,所以这种方式必须要很好的解决out of order问题。
l flowlet
flowlet本质是利用tcp的流突发特性,根据设置一定间隔将流分割为一个个burst 子流,然后每次切换都是在这个间隔中间,从而避免乱序。但是这个方式也有局限性:
首先,flowlet无法应对短连接场景,试想如果一个flow一共就一个burst,那flowlet必然无法产生效果;
其次,flowlet是针对tcp的特性设计的,而rdma流量并不符合相关特征。相关论文中做过如下测试,对比rdma使用正常ecmp和不同间隔参数的flowlet情况下的fct,如下图所示,即便设置一个非常小的间隔,如10us,其效果也远不如默认情况的ecmp效果。
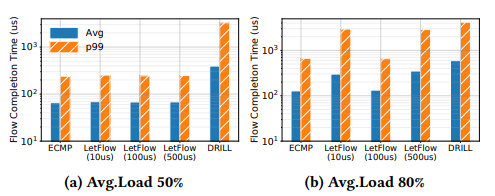
这意味着,在给定的非活动时间间隔下,与tcp相比,在rdma流量中寻找flowlet的机会要少得多。这可以归因于tcp以突发方式传输(例如tso ),并使用批量优化的ack来实现i/o和cpu效率,从而自然地在传输之间创建时间间隔。另一方面,rdma使用基于硬件的连接级数据包调度(即速率整形),导致连续的数据包流并且具有较小的时间间隔。因此,由于缺乏足够大的flowlet间隙,基于flowlet切换的方法无法很好地与rdma配合使用。
l flow based
flow based{banned}最佳经典的就是ecmp方式,其优点是没有乱序问题,但其缺点也比较明显,我们在文章开头已经做过阐述。
下面我们看一下业界的一些主要解决方法。
srd
在rdma规范中定义的可靠传输分为reliable connection(rc)和reliable datagram(rd),定义都要求数据保序提交,其区别在于rc需要建立连接,即假设有n个节点,每个节点有m个进程,rc需要使用m^2*n个qp,而rd仅需要m个qp。
但是即使是rd里面也由一个r(reliable ),这里明确一下首先rdma保序的含义为:可靠服务在发送和接受者之间保证了信息{banned}最佳多只会传递一次,并且能够保证其按照发送顺序完整的被接收,注意这里的保序是只message粒度的(不是packet粒度的)。为了实现保序协议上需要有以下机制:应答(ack),数据校验,序列号。
而在商用网卡中当前没有任何一家公司实现了rd协议,因为在共享一个rx硬件队列时,有要求多条流保序,必然导致线头阻塞(headofline blocking,holb),为了解决这个问题需要在共享rx硬件队列前加入m*n个硬件队列先做保序,或者在发送端添加m*n个virtual output queue队列实现。一般rd私有实现中将这个称之为connection,通过connection来实现rc中qp的连接管理,而rd的qp只保存一下connection共享的信息,通过这种方式节省一部分qp资源开销。但没有免费的午餐,代价就是rc接口的兼容性不友好,毕竟verbs接口中不感知这种connection。因此商卡更多的是通过将rc可以进一步演进到xrc来降低到m*n个qp,或者通过dct的方式来缓解。
srd是aws efa底层的传输协议。efa/srd早期主要针对hpc中的mp集合通信场景,这些mpi语义对保序没有太强约束,但却需要面对大规模场景由于每个进程都需要建立对应的qp消耗大量的资源,因此aws定义了一套基于(scalable reliable datagram.srd)的内存操作语义。srd通过rd的方式实现共享qp,实现qp的减少,但标准rd是需要保序的,而保序就需要维护qp粒度的信息,还是需要消耗资源,因此srd相对rd放弃了保序的要求,而将保序的工作交给了上层应用层。具体实现上srd是将message内的保序交给了其efa驱动的rxr模块,而将message间的保序交给了应用。当然即使实现message内的保序,通常也需要协议支持ddp,否则片上的资源会产生极大的消耗,关于ddp我们后面再介绍。
此外,面对很多需要严格保序和兼容rdma rc语义的情况,srd就会因为无法兼容而面临大量适配工作。aws在其efa v2(第二代efa)中完善了其兼容性方面的支持。
direct data placement (ddp)
前面讲过如果要保序需要有ack,seq机制,类似tcp一样。但是当出现乱序的时候tcp通常需要把乱序的报文暂时存在内存中,然后等缺失的报文到达后再一起提交。这个方式在rdma中是有挑战的,因为网卡的片上资源是十分有限的,无法支持大量报文的缓存,尤其在ai场景下,每个packet几乎都是大包。因此通常来说rdma场景是不允许乱序的,为了解决这个问题就不得不提ddp了。
ddp既是一种技术,也可以说是一种协议。所谓ddp技术就是将报文直接放置在host内存中,那要实现这一点我们就需要知道这个报文要放置的内存地址,所以就需要协议上的支持。在iwarp协议中其中用于实现ddp功能的协议名称就叫ddp,其具体的位置如下图,关于协议的格式我们就不详细展开了,但是从功能上我们肯定知道其中包含了报文要放置的地址(在iwarp中称作steering tag,简称stag)。

在infiniband或者roce中,实现ddp的功能的协议为rdma extended transport header (reth),具体协议如下图所示:

既然这样每个报文都有ddp header不是就没问题了吗?但实现上还是存在一些问题。我们首先需要研究下开源的nvidia collective communications library (nccl),重点关注infiniband / rocev2传输。
gpu工作负载
从技术上讲,ai训练不在乎数据以哪种顺序写入内存:无论是{banned}最佳后一个字节优先传输到内存中,还是{banned}中国第一个字节传输到内存中,只要所有字节都传输完成后,应用程序就可以正常运行。
从应用视角看,整个传输流程,如下图所示:应用程序启动传输或接收完成通知,网卡则使用rdma从内存中提取数据或写入数据到gpu内存。应用程序本身不需要按顺序传递数据包,但必须在传输完成后得到通知。
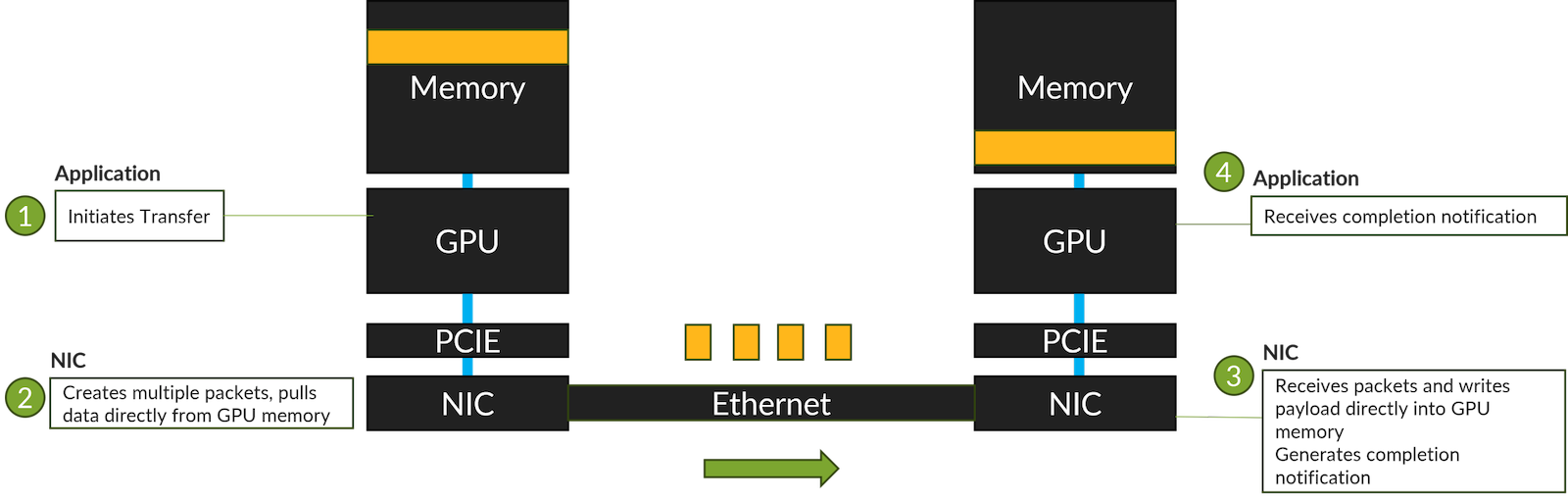
nccl使用infiniband可靠连接传输服务,该服务是面向连接的,发送者确认了数据包的传输,数据包在传输过程中严格保序。那我们能否改变标准,并修改传输语义以实现无序传输?
具体来说,nccl 使用两种不同的 infiniband “verbs” 操作进行传输:
l rdma_write - 从源内存传输到目的内存,事务从源发起。
l rdma write with_imm - 与上述相同,但还通过所谓的“immediate data”通知目的地传输完成。该操作用于序列中的{banned}最佳后一个内存传输事务。
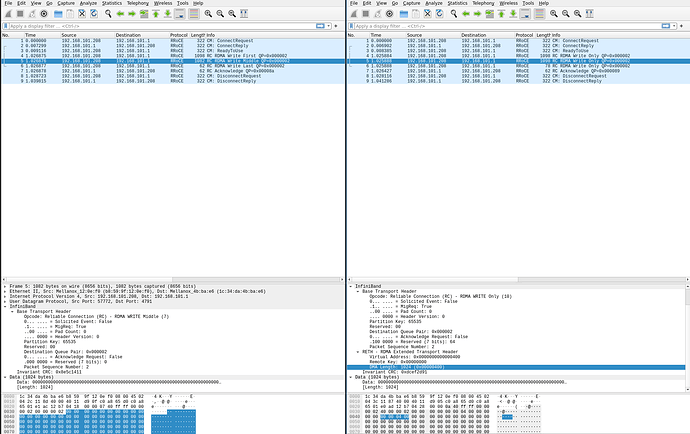
远程内存写操作支持{banned}最佳多传输2gb的数据。实际传输发生在小于或等于{banned}最佳大传输单元(通常为4kb)的较小片段中。通常,传输分为4种不同类型的片段(数据包):
ü rdma write first - {banned}中国第一个片段,包含rdma 扩展传输头(reth),其中包含远程内存地址和数据长度。头部后面是数据有效负载。网卡将地址信息存储在其本地,并在随后的片段中使用它。
ü rdma write middle - 中间片段,只包含数据有效负载。
ü rdma write last - 传输的{banned}最佳后一个片段,只包含数据有效负载。
ü rdma write last with immediate - 传输的{banned}最佳后一个片段,包含数据有效负载和 immediate data。
发现问题了没有,当前实现只有一个message的write first包含reth,而不是每包包含,如下图所示。那么如果后续的报文先到达,硬件就要面对存储问题了。
为此,nvidia 的 connect x 6 之后的网卡支持了自适应路(adaptive routing),其中支持将每个 rdma write 请求都映射到一个或多个相同类型的 rdma 操作:rdma write only。该操作在每个数据包中嵌入了 rdma 扩展传输头(reth),这使得网卡可以在接收到任何数据包后直接将数据写入 gpu 内存,并在网卡内存中携带{banned}最佳少的额外状态以检测数据包丢失。fabric 端到端凯发app官方网站的解决方案示意图如下所示。
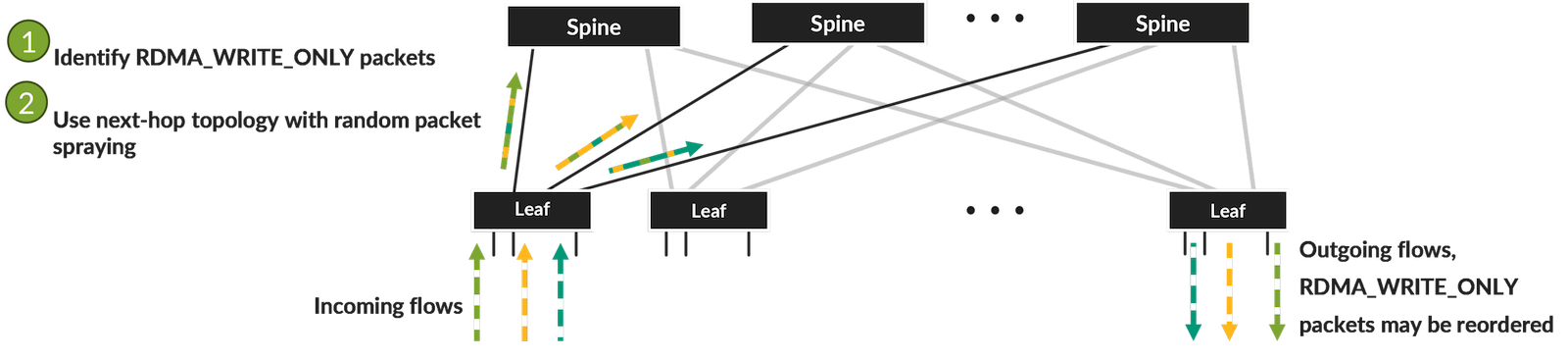
值得注意的是,nvidia 网卡对于 rdma write 实现了这种行为,但对于 rdma write withimm 则没有。从原理上也可以理解,如果{banned}最佳后一个imm先到达就需要通知gpu开始计算了,但是前面的报文可能还没有到达,因此需要先hold{banned}最佳后一个待imm的报文,这样网卡就需要消耗一定的资源。
这就是为什么 nccl 还有一个特殊的设置来启用自适应路由(默认情况下在以太网传输中禁用)。在这种操作模式下,如果数据长度超过一定限制,nccl 使用 rdma write 操作传输数据负载,然后用长度为零的 rdma write withimm 发送传输完成通知。网卡负责将通知按顺序传递给接收应用程序。
当前使用这种方式在实际测试中会观察到确认报文(ack)的数量会增加,原因是原有模式是对这个消息生成确认(rdma write first, 多个rdma write middle,以及rdma write last组成),而在adaptive routing场景会为一组rdma write only (比如3到4个)生成。
adaptive routing
提起adaptive routing(自适应路由),就不得不提nvidia spectrum-x(类似技术broadcom 也支持,只不过叫dynamic load balancing,简称dlb)。nvidia spectrum-x 的adaptive routing是一种精细化负载均衡技术,通过动态调整rdma数据路由以避免拥塞,结合bluefield 3的ddp技术,提供{banned}最佳佳负载均衡和实现更高效的数据带宽。
nvidia? spectrum?-x 网络平台是{banned}中国第一个专为提高ethernet-based ai云的性能和效率而设计的以太网平台。这项突破性技术在类似llm的大规模ai工作负载中,提升了1.7倍ai性能、能效,以及保证在多租户环境中的一致、可预测性。
spectrum-x基于spectrum-4以太网交换机与nvidia bluefield?-3 dpu网卡构建,针对ai工作负载进行了端到端优化。
spectrum-x 关键技术
为支持和加速ai工作负载,spectrum-x 从dpus到交换机、电缆/光学器件、网络和加速软件,进行了一系列优化,包括:
§ spectrum-4上的nvidia roce自适应路由
§ bluefield-3上的nvidia直接数据放置(direct data placement, ddp)
§ spectrum-4和bluefield-3上的nvidia roce拥塞控制
§ nvidia ai加速软件
§ 端到端ai网络可见性
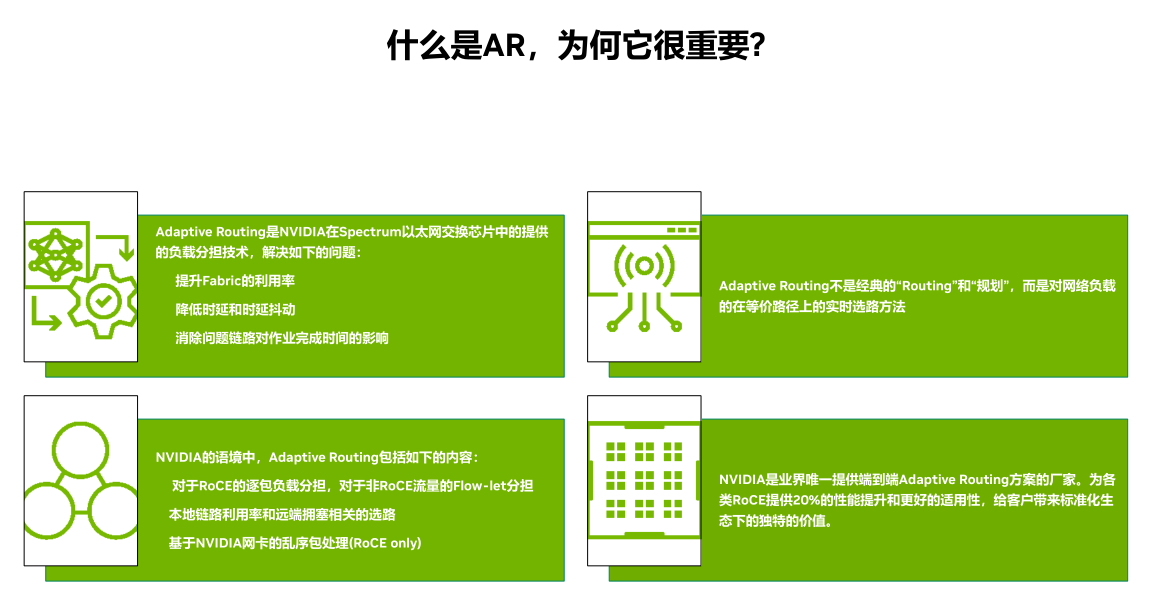
adaptive routing(ar)是nvidia在spectrum以太网交换芯片中的提供的负载分担技术,解决如下的问题:
l 提升fabric的利用率
l 降低时延和时延抖动
l 消除问题链路对作业完成时间的影响
adaptive routing的实现是需要nvdia的spectrum交换机(如spectrum-4系列交换机)和其网卡(bluefield-3 dpu网卡)配合完成的。
具体来说就是spectrum交换机可以针对rdma和tcp采用不同的策略,如tcp使用flowlet,rdma(roce)采用逐包的load balance。spectrum可以通过网络侧交换机和端侧dpu的紧耦合联动,做到实时动态监控ecmp各个链路的物理带宽和端口出口拥塞情况,来做到基于每个报文的动态负载分担。
spectrum-4交换机负责选择每个数据包基于{banned}最佳低拥塞端口,均匀分配数据传输。当同一流的不同数据包通过网络的不同路径传输时,它们可能以无序的方式到达目的地。
bluefield-3 dpu通过ddp处理无序数据,以提供连续的数据透明给应用程序。
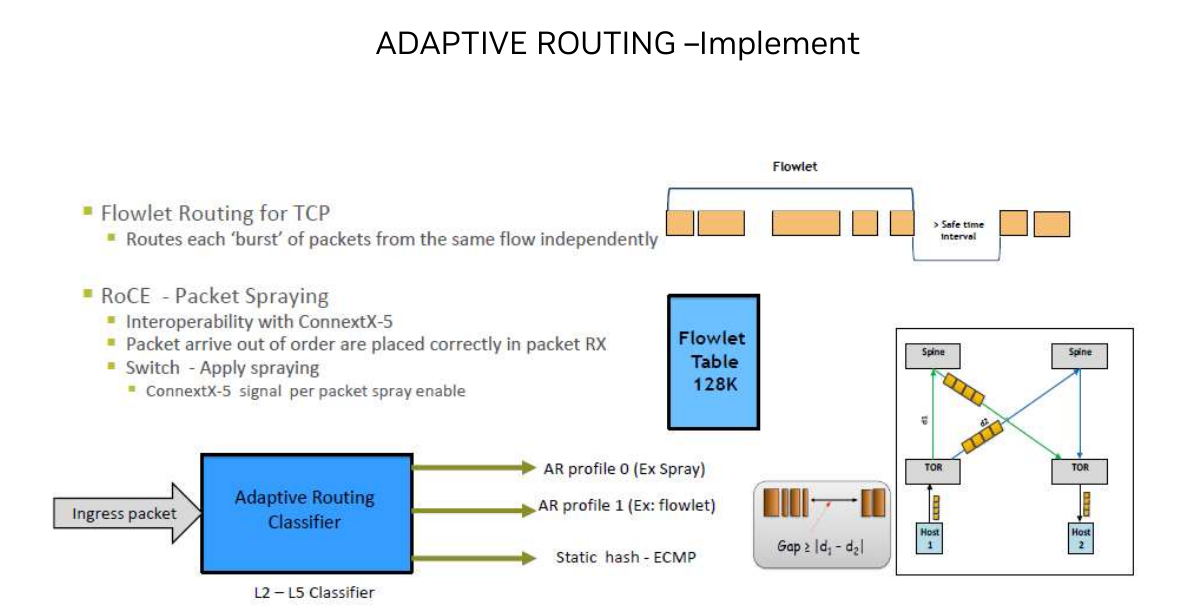
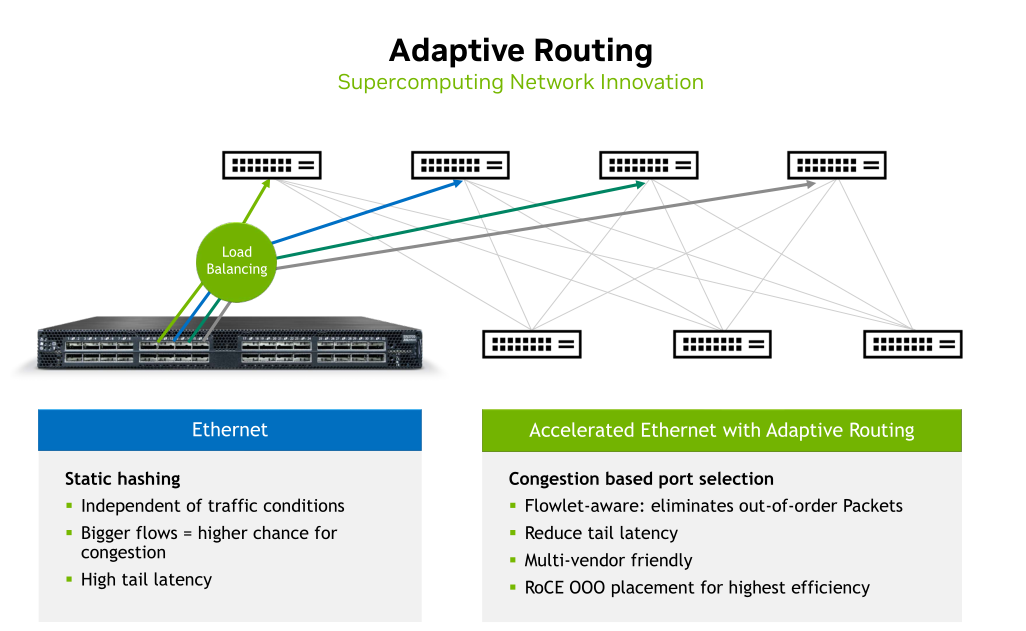
如上图所示,这里nvidia提到adaptive routing的muti-vendor friendly是指在接入侧使用nvidia设备,而其中间设备可以使用其他设备(因为感知路径和选择路径的工作可以交给接入侧)。为什么需要端侧的网卡dpu配合呢?主要由两点:
{banned}中国第一如下图:
端侧设备需要给报文打标,来告诉交换机这些流量可以进行adaptive routing,否则导致了乱序问题目的端可能无法处理,另外可能nvidia为了实现adaptive routing需要在报文中添加一些标记,这些也需要在目的端网卡去除。
另一方面,正如前所述,要实现per packet的打散,必然要面临乱序的问题,而对rdma来说在网卡上实现报文的重排序代价是比较大的,因为缓存报文需要大量的buffer。为了解决这个问题,bf3支持了ddp(direct data placement),即根据报文中的目的内存地址直接将报文放入目的host的内存中,而不需要在网卡上buffer。如下图所示,报文按照1,2,3,4的顺序发送,如果报文4先到达可直接根据报文的地址放入host内存。
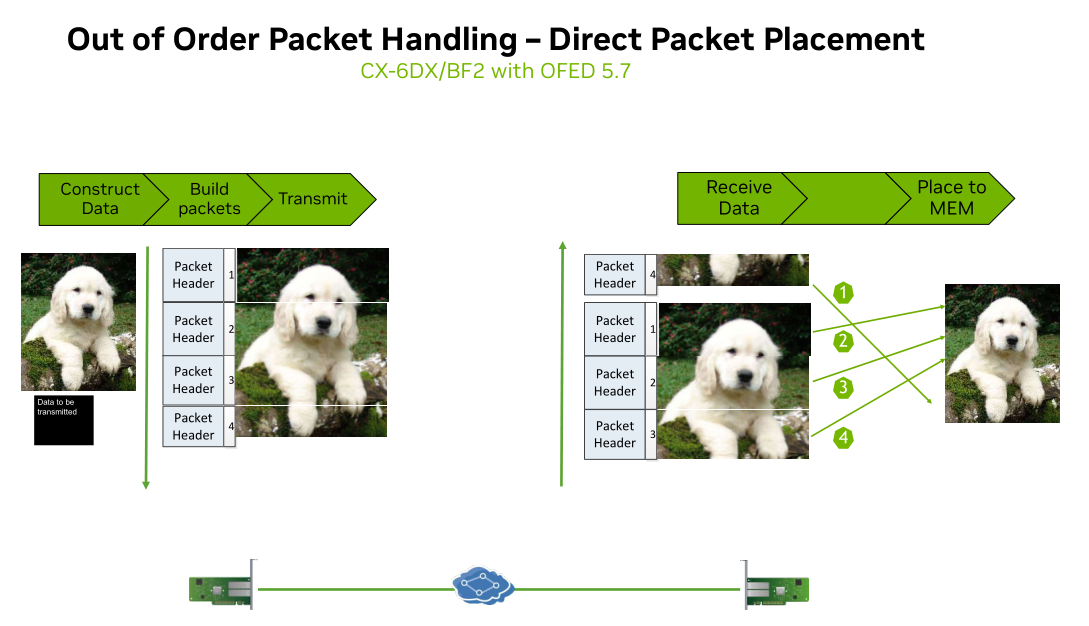
通过adaptive routing和ddp两种硬件加速技术的结合,解决了传统以太网ecmp带宽不均和报文乱序问题,也消除了一些应用由于处理乱序造成的长尾延迟问题。不过adaptive routing也有明显的缺点:
首先是必须绑定nvidia的一套硬件,包括交换机和网卡,这是nvidia的一贯风格,尽可能的绑定;再次,需要有一些配置依赖,比如通常{banned}最佳有一跳接入交换机要打开pfc,因为前面的负载均衡,可能导致{banned}最佳后一跳的下行口egress水位变高;{banned}最佳后一方面就是实际效果有待验证,如ddp的支持效果是否可以应付完全的乱序,否则就需要和flowlet之间做折中。
congnitive routing
“认知路由”(congnitive routing)是broadcom tomahawk系列的一种glb(global load balancing)技术。

所谓glb就是全局的ecmp,所以其归类的话还属于flow based的打散。只是相对普通ecmp,在决定如何分配流量时,不仅考虑本地状况,还会考量全局情况。交换机可以查看下游链路的利用率和多跳路径的信息,从而对整个网络拓扑结构拥有全局视角。这是通过在broadcom的芯片中运行了一个嵌入式应用程序来实现的。
当前congnitive routing除了glb还有其他几个关键技术,如下所示。

conweave (tor上切流保序)
conweave是2023 sigcomm上的一篇论文《network load balancing with in-network reordering support for rdma》提出的思想,。
这篇论文提出了一种名为conweave(或congestion weaving)的凯发app官方网站的解决方案,这是一个专为数据中心中的rdma设计的负载均衡框架。conweave有两个组件,一个在源端和另一个在目的地顶层交换机(tor)中运行。在源端tor交换机中运行的组件持续监视活动流的路径延迟,并在检测到拥塞时尝试进行重路由,而不是被动地等待flowlet间隙。但这种在没有足够数据包间隙的情况下进行的重路由可能导致目的地tor交换机上的乱序数据包到达。conweave的关键思想是将乱序数据包屏蔽掉,不让其传递到连接到目的地tor交换机的rdma主机。
论文通过利用intel tofino2可编程交换机上的{banned}最佳新队列暂停/恢复功能,在数据平面上将数据包重新排序,从而实现这一目标。为了确保在可用的硬件资源下能够完成这一操作,conweave以一种有原则的方式重新路由流量,以使乱序数据包只以可预测的模式到达,并且这些数据包可以在数据平面上高效地恢复到原始顺序。值得注意的是,conweave与主机无关,它被设计为在网络中(即在tors中)引入,与现有的rnic和应用程序无需任何修改即可无缝工作。
如下图所示,conweave提供了负载均衡设计中的新范式。通过网络中的重排序能力,conweave可以频繁地重路由流量,同时将乱序数据包保持在较低水平。因此,与现有方案相比,conweave能够达到更优的操作点。
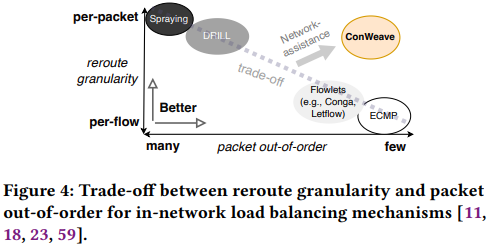
? 提出了一种在普通可编程交换机上解决数据包重排序的轻量级设计。该系统使用运行在intel tofino2交换机上的p4进行了实现。
? 设计了conweave,这是一个负载均衡设计,可以对活动流进行每个rtt的延迟监控,并利用上述网络中的数据包重排序方案,在屏蔽乱序数据包到达的同时进行路径切换。
下面看下其关键实现。
解决保序问题
为了实现保序逻辑,需要两个关键元素:(1)一个用于保留/释放数据包的原语(例如队列),(2)有状态的内存/操作,用于在数据包到达时更新/检查状态。状态操作包括跟踪数据包序列号和使用的相关队列。幸运的是,近期的可编程交换机具备了这样的功能。以tofino2 为例: (1)每个出端口{banned}最佳多128个先入先出(fifo)队列,具有基于优先级的队列调度。 (2)每个队列的暂停/恢复功能,同时对其他队列进行线速数据包处理。 (3)数十mb的有状态内存(例如寄存器数组),可以由数据平面中的alu进行更新。
如下图所示,展示了上述原语在示例场景中的使用方式。在开始时,分配一个专用于转发有序数据包的队列q0。当数据包4到达时,我们将数据包序列与状态next seq进行比较,发现它是乱序的。我们将数据包放在空队列q1中进行保留。类似地,当数据包2到达时,也是乱序的,我们将其放在q2中。接下来,数据包1按顺序到达。因此,立即通过q0转发它。此时,数据包2是下一个序列的数据包,它从q2中释放出来。next seq据此增加为3。{banned}最佳后,数据包3到达时将其转发,清空q1,并以类似的方式将next seq增加到5。
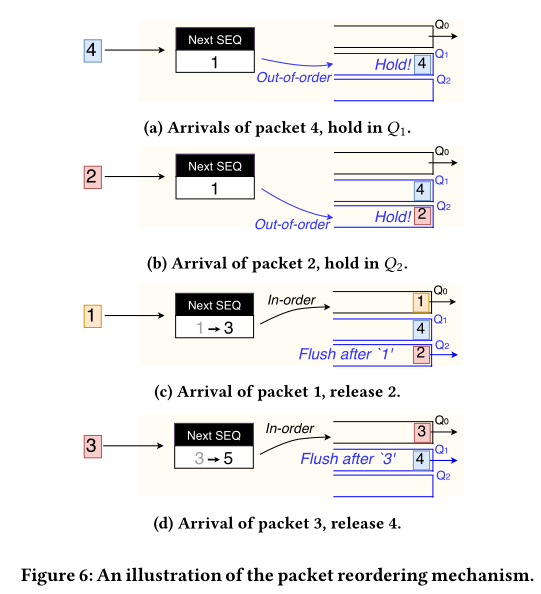
实际考虑因素 虽然上述的排序机制在逻辑上很简单,但存在一些实际问题。
1. 有限的队列资源:在数据平面中保留乱序数据包的想法受到可用队列数量的限制。例如,虽然我们的示例只需要两个队列来保留两个乱序数据包,但在{banned}最佳坏的情况下,保留n个乱序数据包将需要n个队列(想象一下n个数据包以相反的顺序到达)。不幸的是,可供用于排序的队列数量有限。因此,对于可能存在任意乱序到达的情况,这种方法可能不可行。
2. 缺乏排序原语:有人可能考虑在交换机内部使用数据包再循环来进行排序。然而,这样的实现是低效的。事实上,这不是一个可行的选择,因为有些情况下,乱序数据包的到达速率超过了有序数据包的转发速度。在这种情况下,再循环端口会溢出,导致数据包丢失。
3. 处理数据包丢失:可以通过跟踪数据包序列号来检测乱序数据包的到达。然而,当数据包丢失时,简单的序列追踪会停滞不前。标准的凯发app官方网站的解决方案是设置一个默认的等待时间,在超时后传输到下一个序列。然而,考虑到路径延迟可能存在相当大的变异性,设置适当的超时值并不是一个简单的任务。在数据平面上使用有限的资源执行此任务使得任务更加具有挑战性。
conweave的关键思想是我们频繁地(大约每个往返时间)根据网络测量结果来决定是否进行重路由。需要确保只有在网络中可以高效地对乱序数据包进行排序并在交付给终端主机之前才会进行重路由。
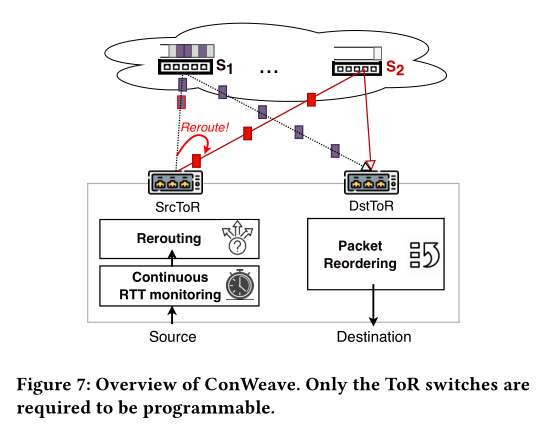
下图显示了conweave的整体架构:
● 有两个组件,一个运行在源tor交换机上,另一个运行在目的地tor交换机上。tor交换机通过数据中心网络连接。我们假设使用某种形式的源路由,以便源tor交换机可以将流“固定”到给定的路径上。
● 源tor上的组件执行以下功能:(1)进行延迟监测以识别要避免的“不好”路径,(2)如果检测到拥塞,选择一个新路径,并且(3)实现确保可以“安全”地进行重路由而不会导致终端主机乱序到达的机制。
● 目的地tor交换机上的组件提供了一个数据包重排序功能,以掩盖由于重路由引起的乱序传递。
conweave只会在以下三个条件下进行重路由:(i)现有路径拥塞,(ii)存在一个可行的非拥塞路径,(iii)由先前重路由引起的任何乱序数据包已经在目的地tor收到。
条件(i)和(ii)是为了确保需要重路由并且存在一个好的替代路径。条件(iii)是为了产生可预测的到达模式,即任何流在任何时间点{banned}最佳多只能在两条路径上有在途数据包。原因如下。首先,为了发生重路由,条件(iii)被满足。之前发送的所有数据包都应该已经到达了目的地tor交换机,所有当前的在途数据包都在单条路径上传输。重路由之后,现在可能存在两条有在途数据包的活动路径。条件(iii)禁止在条件再次成立之前进行另一次重路由。
我们在以下三个条件下进行重路由:(i)现有路径拥塞,(ii)存在一个可行的非拥塞路径,(iii)由先前重路由引起的任何乱序数据包已经在目的地tor收到。
持续rtt监测
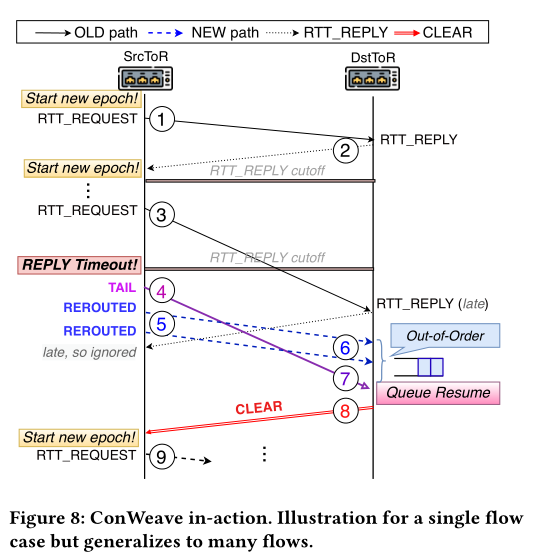
对于每个单独的活动流,conweave持续监测rtt以检测拥塞。为了实现这一点,conweave在每个时期在源tor(源tor交换机)上选择并标记一个数据流中的数据包作为1rtt_request。在目的地tor(目的地tor交换机)上,每当收到一个rtt_request时,它会回复一个带有2rtt_reply标记的数据包到源tor。这里,rtt_reply始终以{banned}最佳高优先级标记。因此,源tor接收到它的时间在反向路径上表示当前路径的拥塞状态给前向路径上的目的地tor。只要在截止时间之前收到rtt_reply,该过程就会为下一个时期重复进行。然而,如果在截止时间之前发送了3rtt_request并且没有收到回复,我们可以推断出由于rtt突然增加,现有路径可能会经历拥塞。这时触发重路由机制。
设计理念。相对于等待探查或搭载数据包,源tor能够通过及时收到rtt_reply来推断路径状态,例如即将出现的拥塞。这样确保了及时的重路由。
路径选择
在重路由之前,conweave需要选择一个非拥塞路径进行重路由。conweave通过tor交换机之间的内部信号传递来跟踪拥塞路径。
每当conweave的目的地tor接收到带有拥塞指示(例如标记了ecn位)的数据包时,它触发一个带有与路径相关信息(例如路径id)的notify数据包,发送给源tor。在接收到notify数据包时,源tor会将相应的路径标记为不可用,持续时间为path_busy。
重路由流量
为了重路由,conweave将数据流分为两个“块”- old和new。一旦选择了重路由的路径,conweave通过将一个数据包标记为4tail,再发送一个数据包到old路径。剩下的数据包被重路由到new路径,并标记为5rerouted。tail和rerouted标记允许dsttor区分在重路由之前和之后发送的两个数据包流。
重路由完成后,srctor期望从dsttor接收到一个○8clear数据包,表示所有的old数据包已经被接收。dsttor通过接收tail数据包来知道这一点。有了clear数据包,srctor可以继续开始一个新的时期9。
处理clear数据包丢失。clear数据包对于确保conweave能够进入下一个时期至关重要。然而,如果clear数据包丢失或者dsttor没有发送,conweave将无法恢复rtt监测机制。为了解决这个问题,srctor跟踪连接的非活动时间,即{banned}最佳后一个数据包处理时间与当前时间之间的间隔。如果超过inactive,conweave会自动进入下一个时期,而无需等待可能永远不会到达的clear数据包。我们设置inactive足够长,以确保在开始新的时期之前不太可能出现乱序到达(即tail和clear数据包的{banned}最佳大传播时间之和)。
以上就是conweave解决rdma load balance的方法。其弊端是明显的,就是tor硬件的资源始终是解决reorder的瓶颈,尽管论文采用了一系列tradeoff的方法,不过其优点就是可以做到通用性,网卡或者协议不感知,完全可以在中间屏蔽。