将晦涩难懂的技术讲的通俗易懂
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
分类: linux
2024-06-09 20:05:01
gpu虚拟化技术总结(2024)-凯发app官方网站
随着ai、加密货币等技术的发展,gpu在市场上“一卡难求”,这也导致gpu售价非常昂贵,而且供货周期也不稳定。对于有gpu需求的企业用户,不但需要思考gpu卡的选型,同时需要考虑怎样尽可能高效利用gpu资源。为了提高gpu资源利用率,很多人选择对gpu进行虚拟化。下面就对当今的gpu虚拟化技术进行一下总结和介绍。
目前,在gpu虚拟化大类上一般分为三种:软件模拟、直通独占(类似网卡独占、显卡独占)、直通共享(如vgpu、mig)。
全软件模拟(sgpu)
{banned}中国第一种,全软件模拟(eg sgpu)。这种方式主要通过软件模拟来完成,类似早期qemu用纯软件模拟网卡一样,主要原理就是在host操作系统层面上建立一些比较底层的api,让guest看上去好像就是真的硬件一样。这种方式的优点是比较灵活,而且并不需要有实体gpu,当然没有实体gpu的缺点就很明显了,模拟出来的东西运行比较慢。另外就是这个方式并没有官方研发,因此产品质量肯参差不齐。软件模拟虚拟化就不讲了,因为真实场景太少,做做实验还将就用,几乎没法用在生产环境,毕竟性能损失太多。
gpu直通(pgpu)
第二种,直通独占 (即pgpu) 。其实严格意义上说,这种方式不能称之为虚拟化。直通是{banned}最佳早出现,即技术上{banned}最佳简单和成熟的方案。直通主要是利用pcie pass-through技术,将物理主机上的整块gpu显卡直通挂载到虚拟机上使用,与市场网卡直通的原理类似,但是这种方式需要主机支持iommu,vt-d对iova的地址转换使得直通设备可以在硬件层次直接使用gpa(guest physical address)地址。
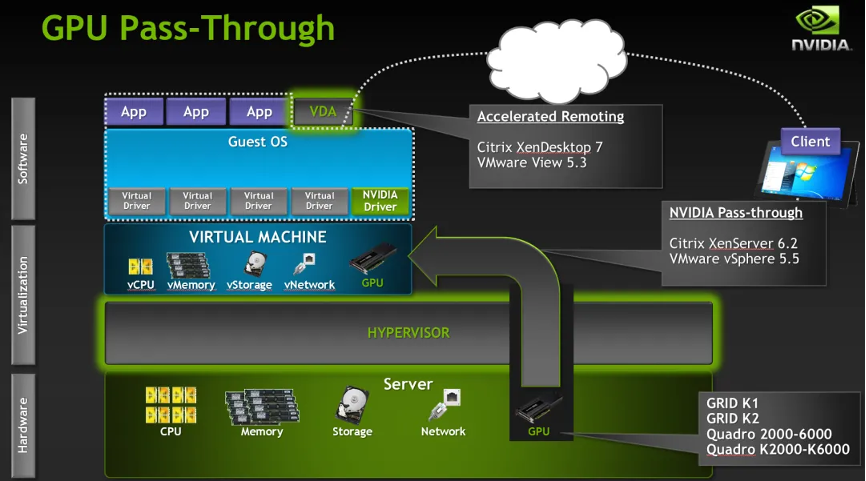
直通模式的技术方案与其他任何pci直通没有任何区别。由于gpu的复杂性和安全隔离的要求,gpu直通技术相对于任何其他设备来说,会有额外的pci 配置空间模拟和mmio的拦截(参见qemu vfio quirk机制)。比如hypervisor或者device module 不会允许虚拟机对gpu硬件关键寄存器的完全的访问权限,一些高权限的操作会被直接拦截。大家或许已经意识到原来直通设备也是有mmio模拟和拦截的。这对于我们理解gpu 半虚拟化很有帮助。
pci 直通的技术实现:所有直通设备的pci 配置空间都是模拟的。而且基本上都只模拟256 bytes的传统pci设备,很少有模拟pcie设备整个4kb大小的。而对pci设备的pci bars则绝大部分被mmap到qemu进程空间,并在虚拟机首次访问设备pci bars的时候建立ept 页表映射,从而保证了设备访问的高性能。想了解细节的同学可以去参考linux kernel document: vfio.txt
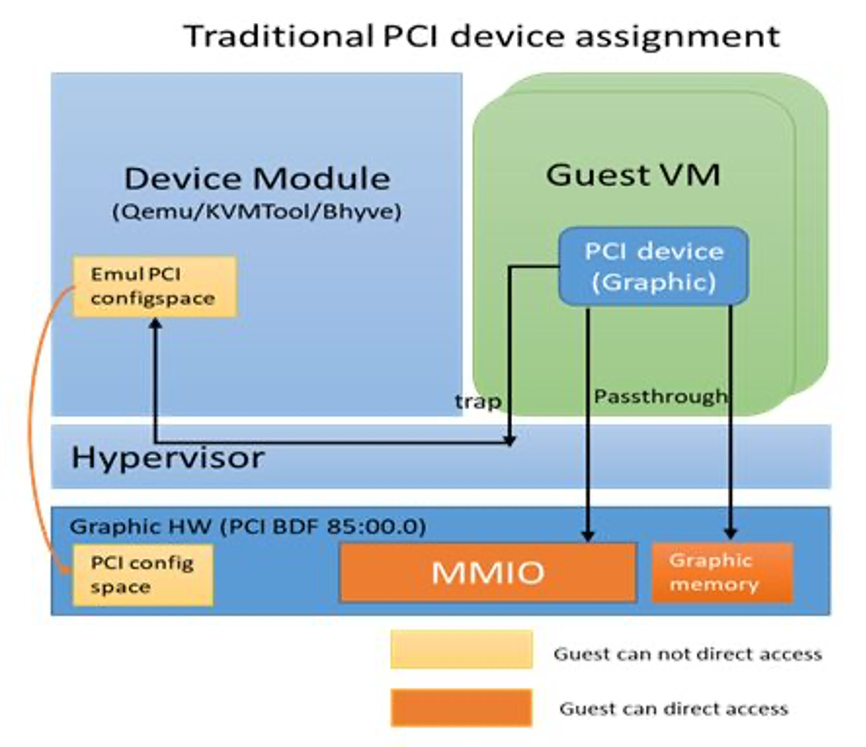
pci 直通架构
因为直通方式的性能损耗{banned}最佳小,各大公用云厂商广泛采用直通模式,而且直通方式相当于虚拟机独享gpu,因此硬件驱动无需修改。另外因为直通模式没有对gpu功能性做阉割,因此大多数功能可以在直通模式下无修改支持。但gpu 直通的缺点是一张gpu卡不能同时直通给多个虚拟机使用,相当于虚拟机独占了gpu卡。如果多个虚拟机需要同时使用gpu,需要在服务器中安装多块gpu卡,分别直通给不同的虚拟机使用。而且直通gpu的虚拟机不支持在线迁移。
为了应对gpu直通不能共享gpu的限制,第三种方式直通共享的虚拟化方式出现了。这也是目前gpu厂商主推的技术趋势,也是我们这篇文章结束的重点。在介绍直通共享方案前,首先介绍一下直通共享的原理。
gpu虚拟化技术的原理
如下图所示,是gpu的典型使用架构,从应用层到底层硬件,每一层都可以通过相关的技术实现gpu虚拟化。

按照cuda 计算 stack和opengl 渲染 stack两个场景划分,又可以分为不同的虚拟化技术。如下图所示。
cuda 计算 stack

opengl 渲染 stack
一个典型的 gpu 设备的工作流程是:
1. 应用层调用 gpu 支持的某个 api,如 opengl 或 cuda
2. opengl 或 cuda 库,通过 umd (user mode driver),提交 workload 到 kmd (kernel mode driver)
3. kmd 写 csr mmio,把它提交给 gpu 硬件
4. gpu 硬件开始工作... 完成后,dma 到内存,发出中断给 cpu
5. cpu 找到中断处理程序 —— kmd 此前向 os kernel 注册过的 —— 调用它
6. 中断处理程序找到是哪个 workload 被执行完毕了,...{banned}最佳终驱动唤醒相关的应用
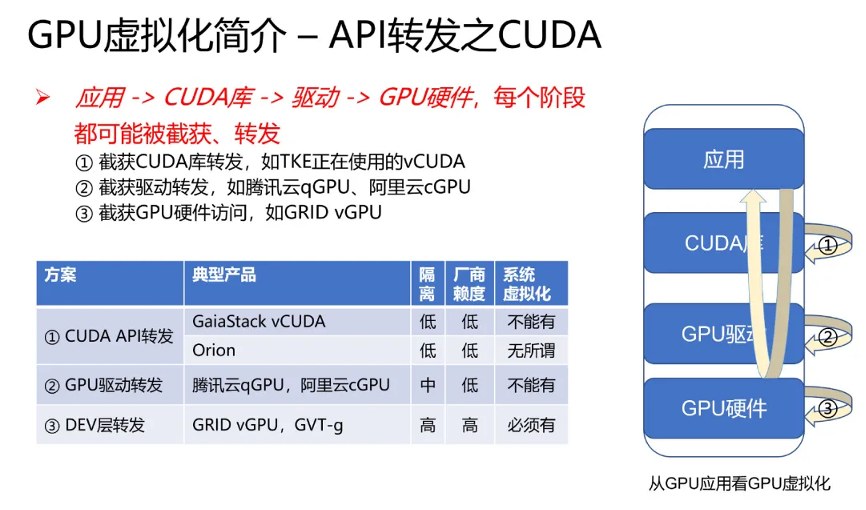
可以看出,从 api 库开始,直到 gpu 硬件,stack 中的每一个阶段,都有被截获、转发的可能性。下面主要以cuda stack为例介绍。
api转发
在介绍api转发方案前首先看一下cuda的整体架构。如下图所示:
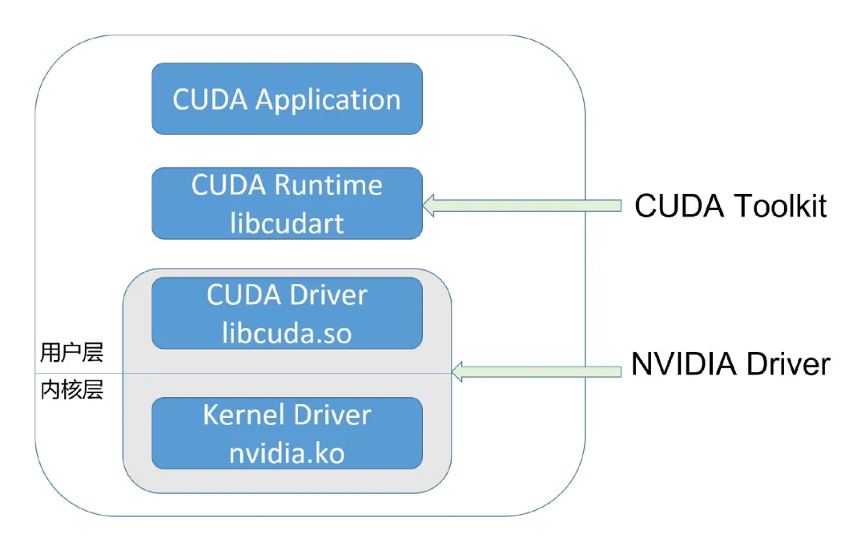
cuda 开发者使用的,通常是 cuda runtime api,它是 high-level 的;而 cuda driver api 则是 low-level 的,它对程序和 gpu 硬件有更精细的控制。runtime api 是对 driver api 的封装。
cuda driver 即是 umd(user mode driver),它直接和 kmd(kernel mode driver) 打交道。两者都属于 nvidia driver package,它们之间的 abi,是 nvidia driver package 内部的,不对外公开。英伟达软件生态封闭包括:
l 无论是 nvidia.ko,还是 libcuda.so,还是 libcudart,都是被剥离了符号表的
l 大多数函数名是加密替换了的
以 nvidia.ko 为例,为了兼容不同版本的 linux 内核 api,它提供了相当丰富的兼容层,于是也就开源了部分代码:
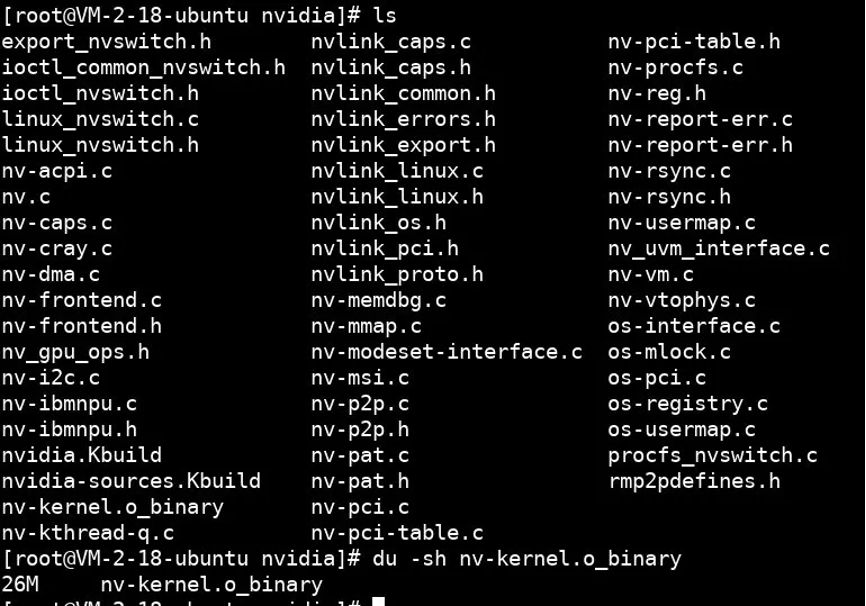
其中这个 26m 大小的、被剥离了符号表的 nv-kernel.o_binary,就是 gpu 驱动的核心代码,所有的 gpu 硬件细节都藏在其中。
从cuda架构上看,api转发分为用户态截取和内核态截取。用户层api截取是一种在用户态实现的虚拟化技术。通过创建一个函数库(如libwrapper),它能够拦截用户的api调用,解析后转发到实际的gpu驱动,从而实现资源的隔离和调度。这种方法的优势在于对用户代码零侵入,且部署灵活,无论是在裸机还是容器化环境中都易于实现。内核层拦截通过在操作系统内核空间实现模块,模拟gpu设备文件,从而拦截对gpu驱动的访问。这种方法可以有效防止用户篡改,提高安全性,但由于nvidia驱动的闭源性质,技术实现难度较高。
从虚拟机和host的调用关系上看,api转发分为被调方和调用方,两方对外提供同样的接口(api),被调方api实现是真实的渲染、计算处理逻辑,而调用方api实现仅仅是转发,转发给被调方。其核心架构示意如下图:
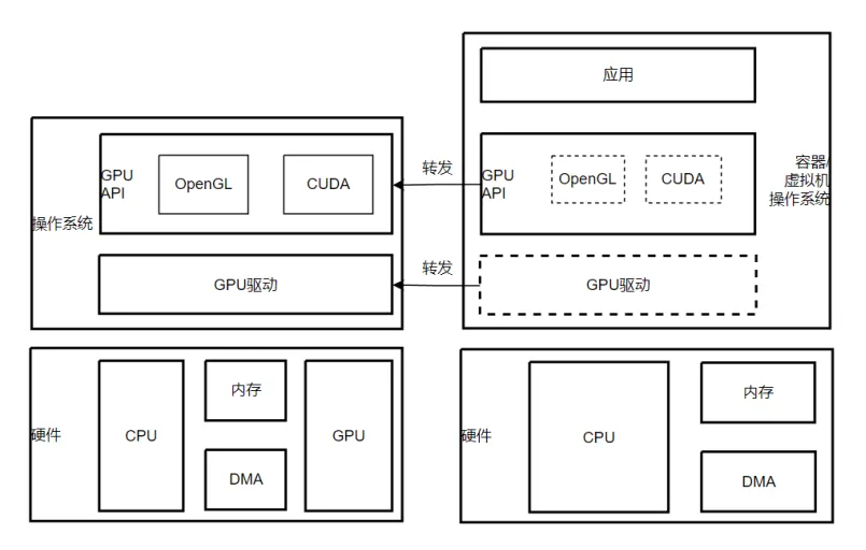
l 在gpu 用户态api层的转发,业界有针对opengl的aws elastic gpu,orionx,有针对cuda的腾讯vcuda,瓦伦西亚理工大学rcuda;
l 在gpu内核驱动层的转发,有针对cuda的阿里云cgpu和腾讯云qgpu。
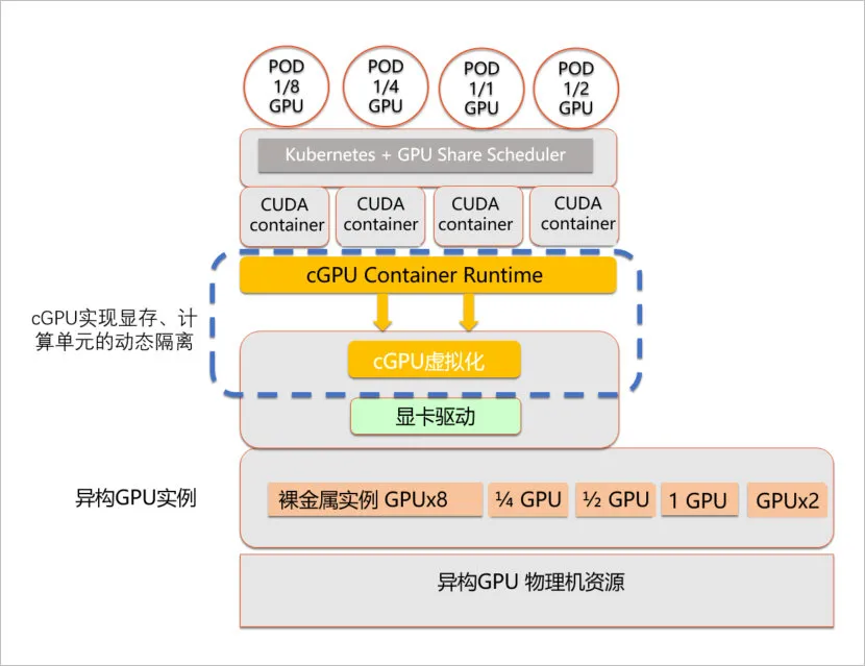
如下图是阿里云cgpu架构,相比其他方案:通过一个内核驱动,为容器提供了虚拟的gpu设备,从而实现了显存和算力的隔离;通过用户态轻量的运行库,来对容器内的虚拟gpu设备进行配置。阿里云异构计算cgpu在做到算力调度与显存隔离的同时,也做到了无需替换cuda静态库或动态库;无需重新编译cuda应用;cuda,cudnn等版本随时升级无需适配等特性。
如下图是腾讯云的qgpu(qgpu == qos gpu)架构:
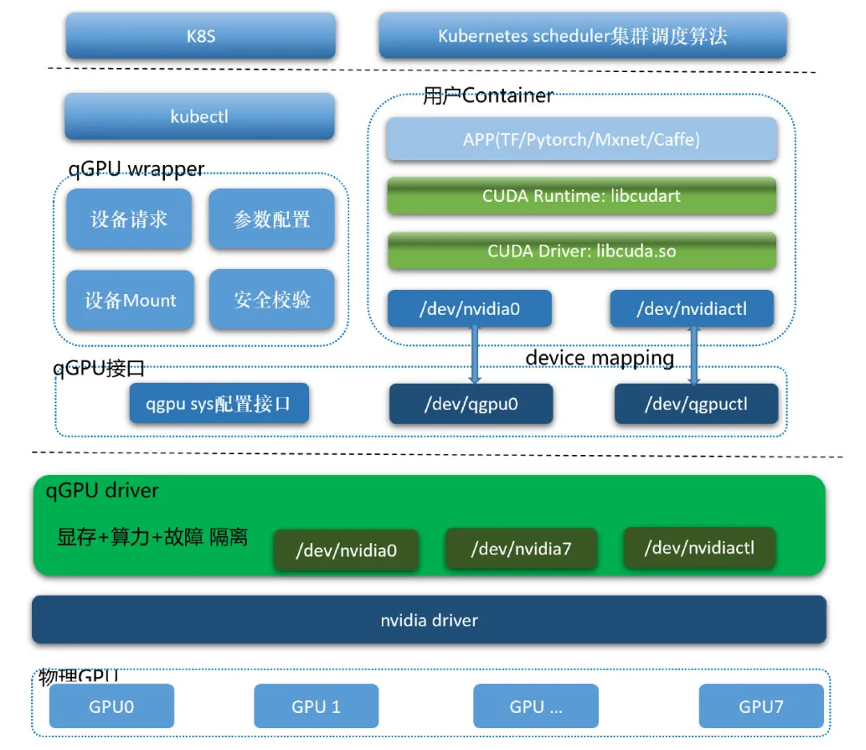
api转发的灵活性以及支持gpu虚拟化的数量不受限制,往往应用于serverless 容器场景。
api转发方案的优点是实现了1:n,并且n是可以自行设定,灵活性高。同时不依赖gpu硬件厂商。但缺点复杂度极高。同一功能有多套 api(渲染的 directx 和 opengl),同一套 api 还有不同版本(如 directx 9 和 directx 11),兼容性非常复杂。并且功能不完整,如不支持媒体编解码,并且,编解码甚至还不存在业界公用的 api。
硬件虚拟化
从硬件虚拟化角度又可分为hardware partition即空分和time sharing即时分。
hardware partition
pcie sr-iov
前文我们提到了gpu直通,这种通过pcie直通gpu的方式只能支持1:1,不支持gpu资源分隔。于是为了解决这个问题,pcie sr-iov(single root input/output virtualization)出现。amd 从 s7150 开始、英伟达从 turing 架构开始,数据中心 gpu 都支持了 sr-iov。但是它不是 nic 那样的 sr-iov,它需要 host 上存在一个 vgpu 的 device-model,来模拟从 vm 来的 vf 访问。
基于pcie sr-iov的gpu虚拟化方案,本质是把一个物理gpu显卡设备(pf)拆分成多份虚拟(vf)的显卡设备,而且vf 依然是符合 pcie 规范的设备。核心架构如下图:
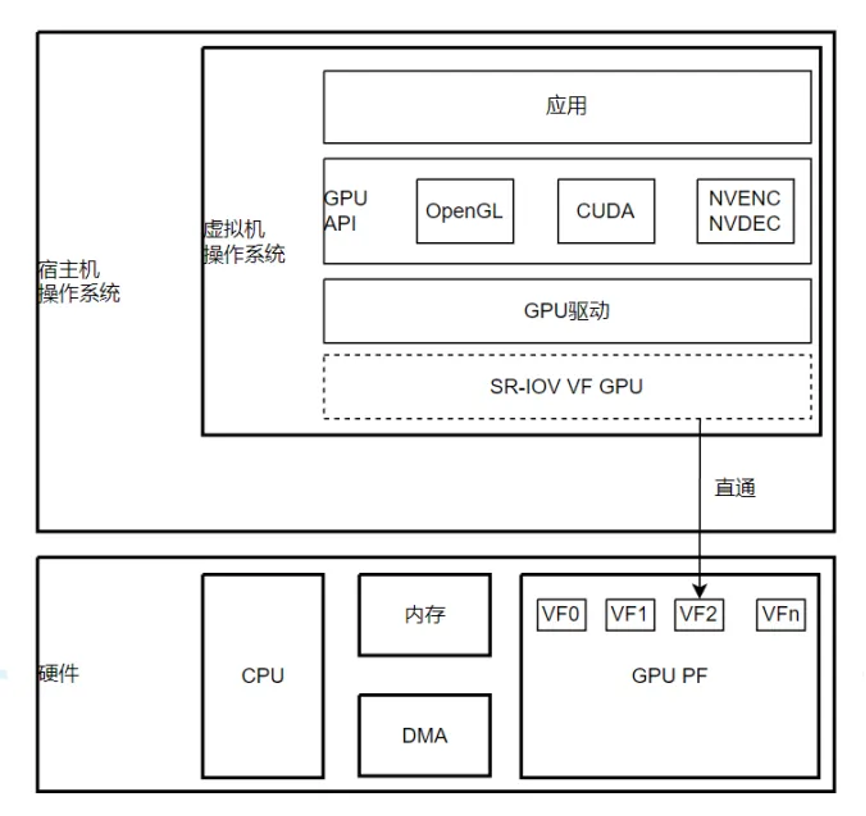
sriov的本质是把一个pci卡资源(pf)拆分成多个小份(vf),这些vf依然是符合pci规范的endpoint设备。由于vf都带有自己的bus/slot/function号,iommu/vt-d在收到这些vf的dma请求的过程中可以顺利查找iommu2nd translation table从而实现gpa到hpa的地址转换。这一点与gvt-g和nvidia的grid vgpu(分片虚拟化)有本质上的区别。gvt-g与nvidia grid vgpu并不依赖iommu。其分片虚拟化的方案是在宿主机端实现地址转换和安全检查。应该说安全性上sriov方法要优于gvt-g和grid vgpu,因为sriov多了一层iommu的地址访问保护。sriov代价就是性能上大概有5%左右的损失(当然mdev分片虚拟化的mmio trap的代价更大)。由于sriov的优越性和其安全性,不排除后续其他gpu厂商也会推出gpu sriov的方案。
这里要说一点,amd gpu sriov从硬件的角度看就是一个对gpu资源的分时复用的过程(严格意义上说amd的实现其实是一种time sharing),并不是真的资源切割,因此其运行方式也是与gpu分片虚拟化类似。
pcie sr-iov的有点就是真正实现了真正实现了1:n,一个pcie设备提供给多个vm使用;但缺点是灵活性较差,无法进行更细粒度的分割与调度;并且不支持热迁移。
nvidia mig
上文介绍的基于 sr-iov 硬件虚拟化技术的 gpu,vf 的数量比较固定,且每个 vf 获得的资源是均分的、定额的。将这些 vf 透传给虚拟机后,由于各个虚机的 workload 不同,就可能出现某些 vf 的资源不够用,而另一些 vf 的资源用不完的情况。
作为业界一哥的 nvidia,自 2020 年的 ampere 微架构(比如 a100)开始支持一种叫做 mig (multi instance gpu) 的技术,gpu可以被安全分割为{banned}最佳多七种独立的gpu实例,服务于cuda应用,从而使多个用户能各自拥有独立的gpu资源,以达到{banned}最佳佳利用率。
对于有多租户需求的云服务提供商(csp),mig技术确保了单一客户端的行为不会干扰其他客户端的运行或调度,同时增强了对各个客户的安全隔离性。
在mig模式下,每个实例所对应的处理器具备独立且隔绝的内存系统访问路径——片上交叉开关端口、l2缓存分段、内存控制器以及dram地址总线均会专一地分配给单个实例。这使得即便有其他任务在对其自身缓存进行大量读写操作或已使dram接口达到饱和的情况下,单个工作负载仍能获得稳定、可预期的执行速度和延迟时间,同时保证相同水平的l2缓存分配与dram带宽资。
mig能够对gpu中的计算资源(包括流式多处理器或sm,以及诸如拷贝引擎或解码器之类的gpu引擎)进行划分,从而为不同的客户(例如虚拟机、容器或进程)提供预设的服务质量(qos)保障及故障隔离机制。
运用mig技术后,用户可以像管理实体gpu一样查看和安排在新建的虚拟gpu实例上的任务。mig兼容linux操作系统,支持基于docker engine的容器部署,同时亦对接kubernetes及建立于red hat虚拟化和vmware vsphere等支持的虚拟机管理程序之上的虚拟机。
multi-instance,那一个 instance 具体是什么呢?
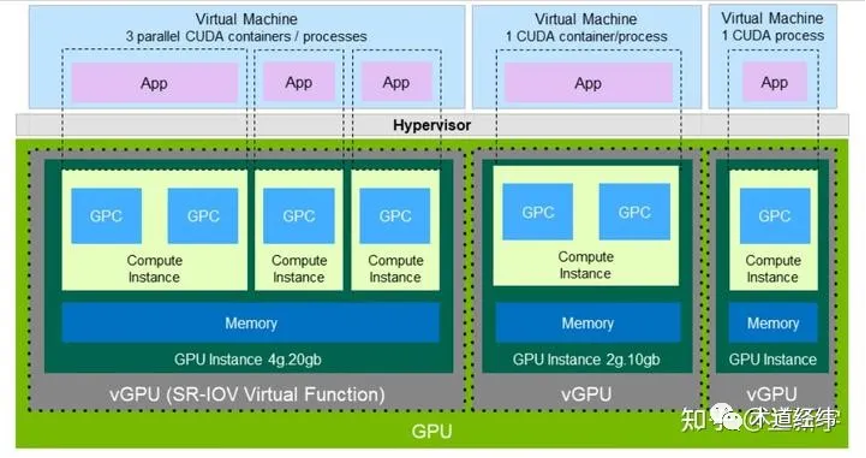
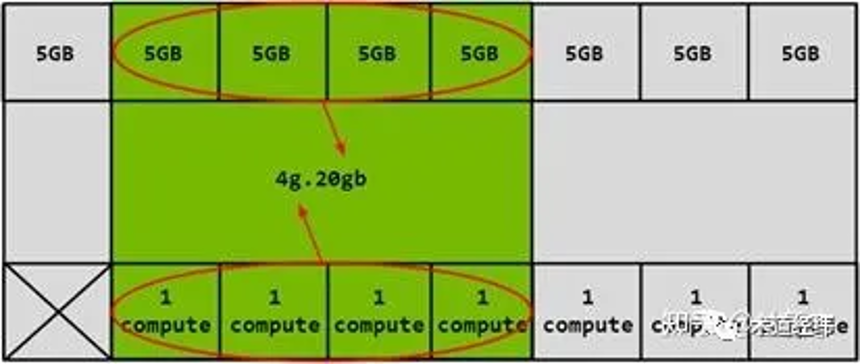
划分方式多种多样,在不牺牲隔离性的同时提高了应用的灵活性:
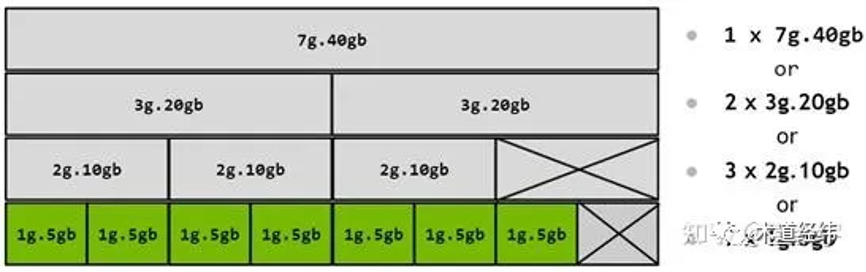
不过 slice 的划分不是随心所欲的,不是你想切多细就能切多细(想起了涡虫),还是受到底层硬件设计的限制:
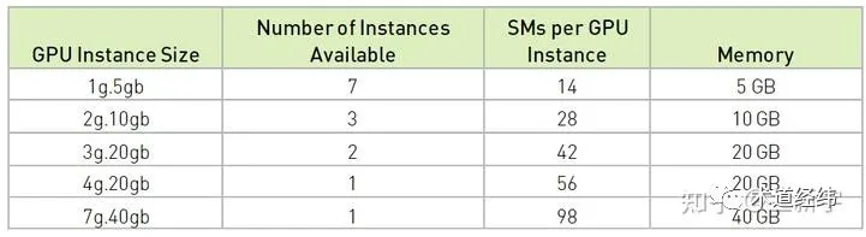
mig 技术可视作是基于传统 sr-iov 的演进和创新,一个 instance 大致可对应一个 pcie vf。以 mig 为代表的硬件资源划分主要在空间上(spatial),同一物理 gpu上的各个 vgpu 获得的资源是专属的(dedicate),可以获得良好的并行性。
gpu分片虚拟化
技术上讲gpu分片虚拟化,就是指基于vfio mediated 透传框架的gpu虚拟化方案。该方案由nvidia提出,并联合intel一起提交到了linux 内核4.10代码库,该方案的kernel部分代码简称mdev模块。随后redhat enterprise,centos{banned}最佳新的发行版花了不少力气又back porting到了3.10.x内核。所以如果目前采用{banned}最佳新的redhat发行版(企业版或者centos 7.x)等都已经自带mdev模块。而如果采用ubuntu 17.x以后版本的话,不但自带mdev功能,连intel gpu驱动(i915)也已经更新到支持vgpu。无需任何代码编译就可以直接体验vgpu虚拟机功能。
那么什么叫mediated透传呢?它与透传的区别是什么呢?一句话解释:把会影响性能的访问直接透传给虚拟机,把性能无关和功能性的mmio访问做拦截并在mdev模块内做模拟(是不是和网卡虚拟化vdpa的思想一样)。
如果熟悉网卡虚拟化vdpa技术的同学一定都对mdev不陌生,没错,mdev{banned}最佳早就是为gpu分片虚拟化而生的。另外要说明一点关于vgpu这个词的含义,它有两层含义,通用的含义是只通过虚拟化技术虚拟出的虚拟gpu都可以称作vgpu,但是有时也特指nvidia grid vgpu技术。
gpu分片虚拟化的方案被nvidia与intel两个gpu厂家所采用。nvidia grid vgpu系列与intel的gvt-g(xengt或kvmgt)系列。
当然,只有内核的支持还不够,需要加上qemu v2.0 以后版本,以及intel或者nvidia自带的gpu mdev驱动(也就是对gpu mmio访问的模拟),那么gpu分片虚拟化的整个路径就全了。而gpu厂家的mdev驱动是否开源取决于自己。按照一贯的作风,intel开源了其绝大部分代码,包括{banned}最佳新的基于mdev的gpu热迁移技术,而nvidia也保持其一贯作风:不公开。
gpu分片虚拟化看起来整个框架就如下图一样(以kvmgt作为例子):
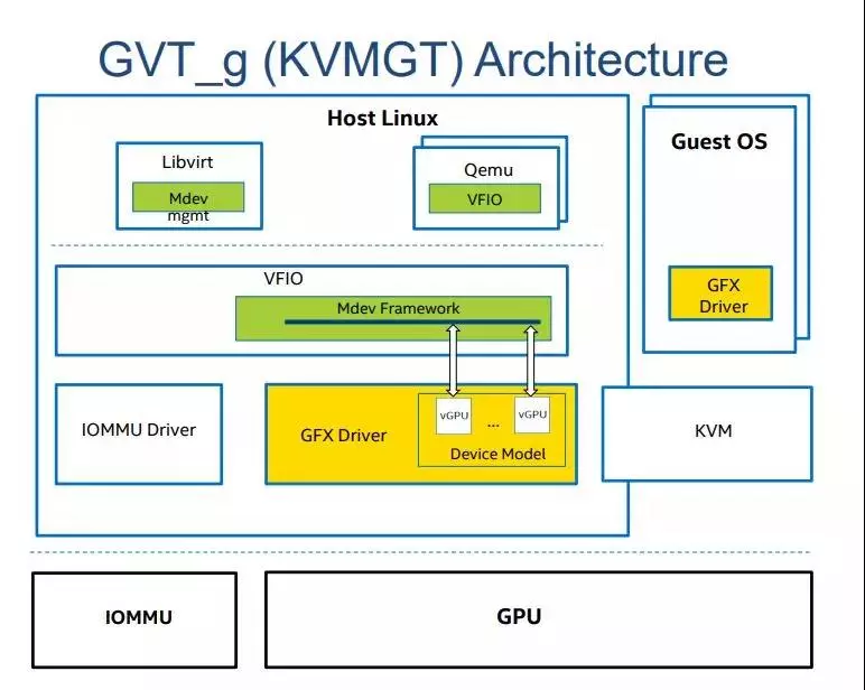
可以从上图看到,vgpu的模拟是通过kvmgt(intel)或者nvidia-vgpu-vfio(nvidia)来完成的。该模块只模拟对mmio的访问,也就是功能性,不影响性能的gpu寄存器。而对gpu aperture和gpu graphic memory则通过vfio的透传方式直接映射到vm内部。
值得注意的是一般pass through的方式都依赖io mmu来完成gpa到hpa的地址转换,而gpu的分片虚拟化完全不依赖io mmu,也就是说其vgpu的cmd提交(内含gpa地址)并不能直接运行于gpu硬件之上,至少需要有一个gpa到hpa的翻译过程。该过程可以通过host端的cmd扫描来修复(kvm gt),nvidia grid vgpu每一个上下文有其内部页表,会通过修改页表来实现。
需要注意的是,nvidia grid vgpu是收费的,所以企业用户要去凯发k8官网下载客户端中心官网购买license才可以使用。
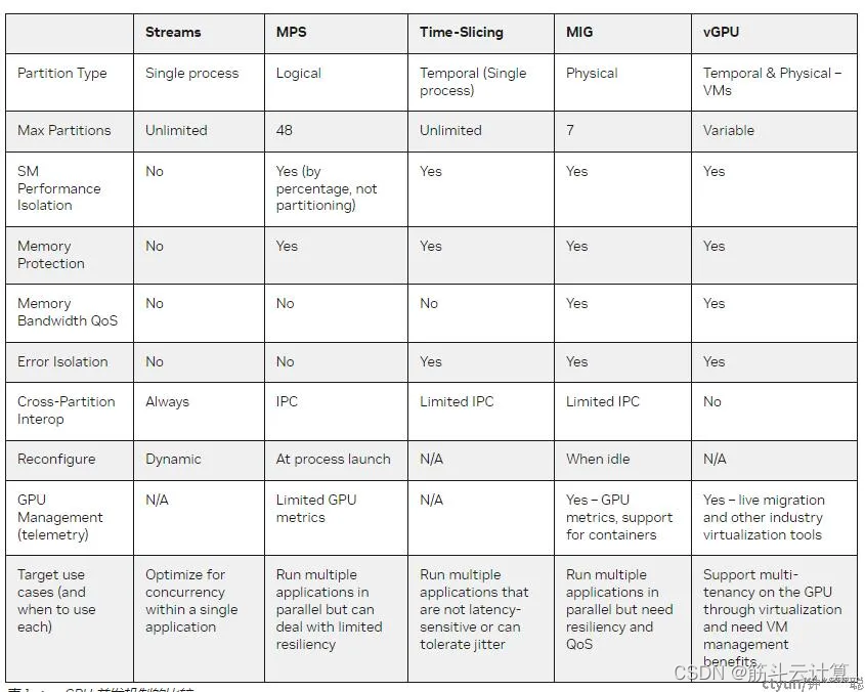
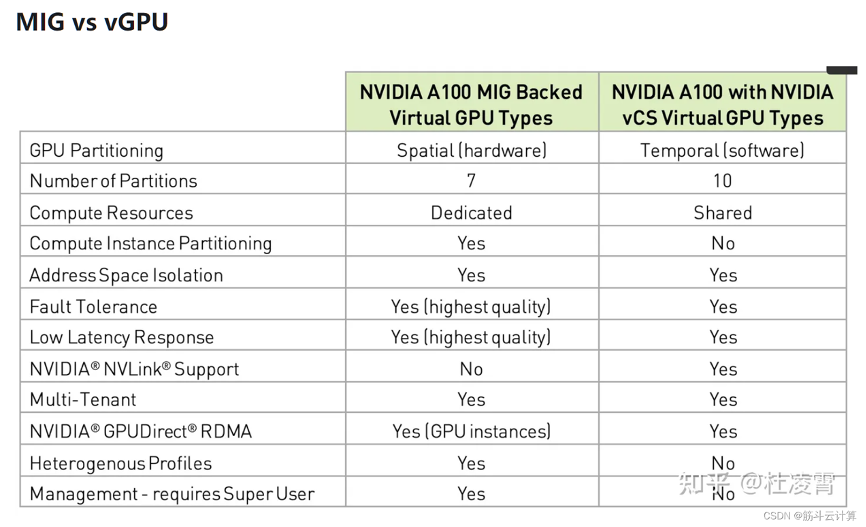
下面是mig和vgpu的一个能力对比:
time sharing
nvidia mps
mps (nvidia multi-process service,)是nvidia公司为了进行gpu共享而推出的一套方案,由多个cuda程序共享同一个gpu context,省去了 context switch 的开销,也在 context 内部实现了算力隔离,从而达到多个cuda程序共享gpu的目的。同时,在volta gpu上,用户也可以通过cuda_mps_active_thread_percentage变量设定每个cuda程序占用的gpu算力的比例。
该方案和pcie sr-iov方案相比,配置很灵活,并且和docker适配良好。mps基于c/s架构,配置成mps模式的gpu上运行的所有进程,会动态的将其启动的内核发送给mps server,mps server借助cuda stream,实现多个内核同时启动执行。
但该方案的一个问题在于,各个服务进程依赖mps,一旦mps进程出现问题,所有在该gpu上的进程直接受影响,需要使用nvidia-smi重置gpu 的方式才能恢复。
time-slicing gpu
nvidia gpu 支持基于 engine 的 context switch。不管是哪一代的 gpu,其 engine 都是支持多任务调度的。一个 os 中同时运行多个 cuda 任务,这些任务就是在以 time sharing 的方式共享 gpu。这种虚拟化方式就和 cpu 虚拟化就比较像了。vgpu 被串行地调度执行,一个 vgpu 需等待其他 vgpu 让出物理 gpu,但当它获得物理 gpu 时,其对 gpu engine 的使用是 exclusive 的。
这种方式非常适合容器runc的场景,为此nvidia还提供给了对k8s的支持:
总结
以上就是gpu目前的场景虚拟化技术,其实按照“空分”和“时分”只是一个大概分类,很多技术,如分片虚拟化其实是两者的结合。下图是nvidia gpu虚拟化的发展实际线:
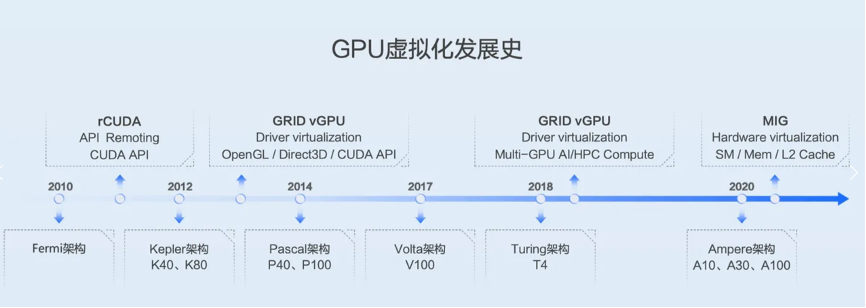
以及nvidia gpu虚拟化技术对比