将晦涩难懂的技术讲的通俗易懂
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
分类: 高性能计算
2024-08-18 17:03:39
大模型训练中的adam算法和相关优化
一阶矩
一阶原点矩
一阶原点矩就是期望,更简单来说就是平均值。比如现在有5个数,分别是1、2、3、4、5,它们的期望计算方式如下:
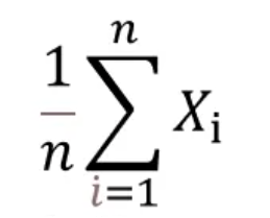
所有的值进行求和,然后除以总个数,即:(1 2 3 4 5)/5=3。所以一阶原点矩就是3,将其称之为原点矩的主要原因如下:
上面式子相当于每个数到原点0的距离进行了求和。
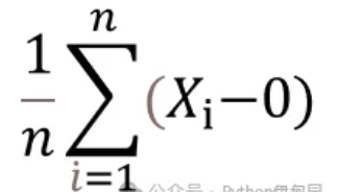
一阶中心矩
一阶中心矩是每个数字与期望(均值)的期望(均值)。
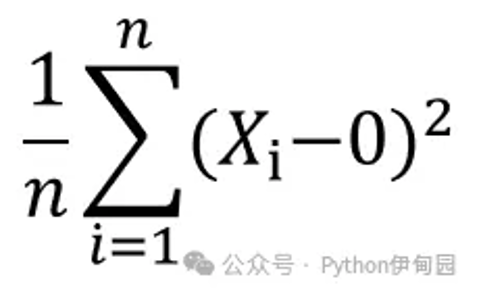
计算结果为:((1-3) (2-3) (3-3) (4-3) (5-3))/5=0
可以看到一阶中心矩为0,并且一阶中心矩永远为0。一阶中心矩一般不用。
二阶矩
二阶原点矩
二阶原点矩就是平方差求和后的均值。
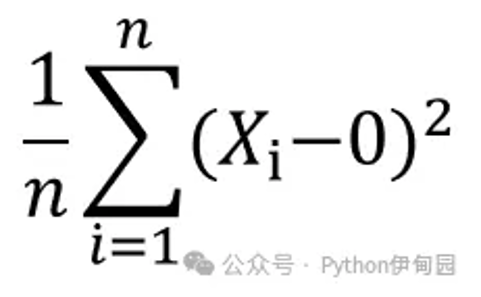
比如现在有5个数,分别是1、2、3、4、5,它们的二阶原点矩为:
((1-0)**2 (2-0)**2 (3-0)**2 (4-0)**2 (5-0)**2 )/5=11
二阶中心矩
二阶中心矩就是每个数据与数据均值的差的平方和的均值,简称方差。
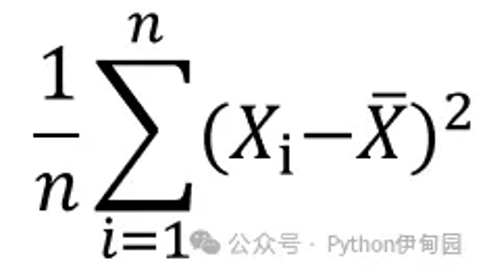
对应于那5个数据来说,其二阶中心矩为:
((1-3)**2 (2-3)**2 (3-3)**2 (4-3)**2 (5-3)**2 )/5=2
对于k阶矩,只需要将平方换成k次方就行了。
梯度下降的演进
在介绍adam优化算法之前我们先回顾一下优化算法的演进,如下图所示:

首先是梯度下降算法,梯度下降算法是一种直观的优化算法,它通过目标函数相对于参数的梯度,来指导参数的更新方向。但在实际应用中,梯度下降算法存在一定缺陷,比如容易受到梯度噪声的干扰,以及在不同参数纬度上的学习率难以统一调整等。
为了克服这些问题,研究者提出了带动量的梯度下降算法,这种算法通过引入动量项,不仅考虑当前的梯度,还将之前的梯度考虑进来,从而减少了优化过程中的震荡,加快了收敛速度。动量梯度下降算法的提出,使我们面临噪声较大,或者参数更新频繁变化的问题时,有了更稳健的优化策略。
随后为了进一步解决学习率调整的问题,均方根传递算法应运而生,均方根传递算法的核心思想是为每个参数独立的调整学习率。通过计算梯度平方的指数衰减平均,他能有效的应对梯度消失和梯度爆炸的问题。使得每个参数都可以根据历史梯度调整更新步长。
{banned}最佳后,是adam算法,他是自适应矩估计的缩写。adam算法综合了动量梯度算法以及均方根传递算法的优势,它不仅利用了动量项来减少震荡,还通过计算梯度的一阶矩和二阶矩来自适应的调整每个参数的学习率。下面我们详细看下每种算法的情况
梯度下降
梯度下降算法是一种一阶的迭代优化算法,它的核心思想是利用目标函数的梯度信息来求局部极小值。在机器学习中这个目标函数通常是损失函数,也就是模型的预测值与实际值之间的差异。如下图是一个典型的一元二次函数的图像,它看起来像是一个山谷,想象一下,我们此刻正站在山腰上,而我们的目标是走到山谷的{banned}最佳低点,那里代表了我们函数的极小值,如果每次我们迈步,都能朝着{banned}最佳陡峭的方向往下走,那么{banned}最佳终我们就能达到谷底,梯度下降算法正是模拟了这一过程,其中梯度指向了函数增长{banned}最佳快的方向,为了走向谷底,我们沿着梯度的反方向,此处负号就表示我们沿着梯度的反方向,以学习率α作为步长更新参数θ的值。
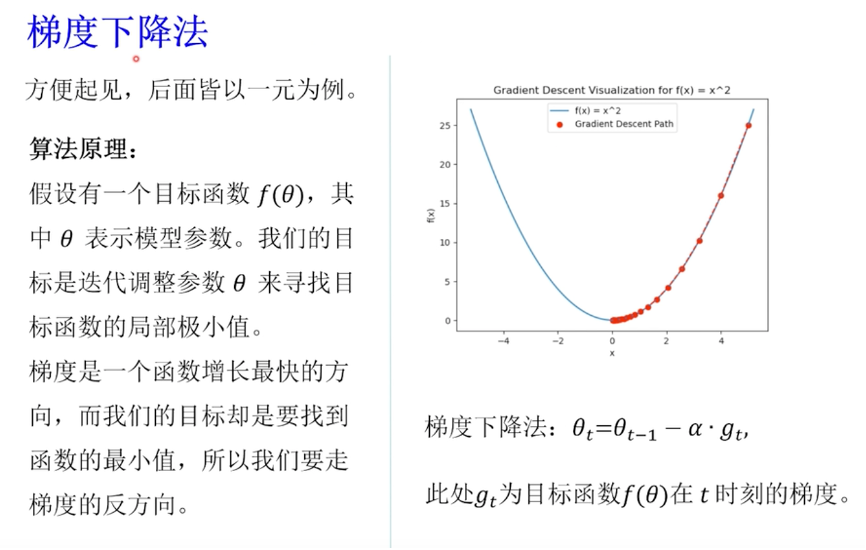
梯度下降算法虽然简单,但它为后续更复杂的优化算法提供了基础,在接下来的部分,我们将看到,如何通过引入动量项和自适应学习率等概念,来改进梯度下降算法,以应对更复杂的优化问题。
动量梯度下降
我们已经了解了梯度下降法的基本原理,现在让我们更进一步探讨,如何通过引入动量的概念来改进梯度下降算法,从而得到动量梯度下降法,在梯度下降法中,每一次参数的更新仅仅依赖于当前的梯度,然而这种方法在面对噪声较大,或者损失函数表面比较崎岖的情况时,可能会导致参数更新方向的频繁变动,从而产生震荡,影响收敛的稳定性,如下图所示:
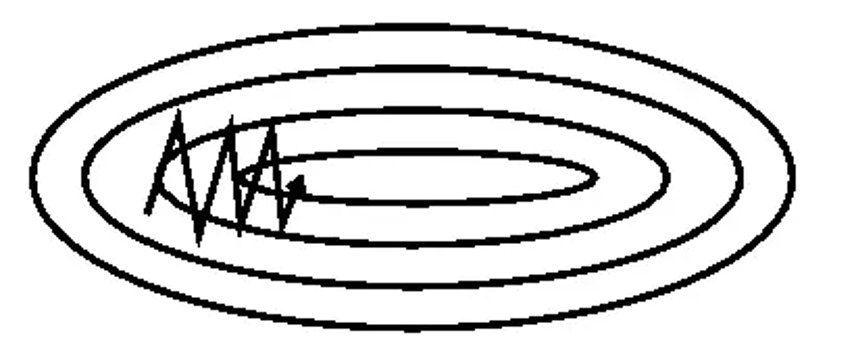
为了解决这个问题,动量梯度下降法应运而生。

如上图所示,动量梯度下降法的核心思想是引入一个动量项mt,它是之前梯度的一个加权平均,其中动量因子β1通常取0.9,它用来控制前面动量(mt-1)在当前动量(mt)计算中所占的比重。
具体来说,动量梯度下降法的更新规则是:
1. 先计算当前参数下的梯度gt;
2. 接着更新动量向mt,mt是之前动量向mt-1与当前梯度gt的加权平均;
3. {banned}最佳后我们用更新后的动量向mt来更新参数;
θ这样参数的更新不仅依赖于当前的梯度,还考虑了之前梯度的方向和大小,通过这种方式,动量梯度下降法,在面对梯度方向频繁变化的情况时,能够维持一个较为平滑的更新路径,减少了震荡,加快了收敛速度。
然而在算法开始时,如果没有适当的初始化或修正m0,直接初始化m0为零,会导致在{banned}最佳初的几个迭代中,动量项主要由当前梯度gt决定,没有充分考虑到历史梯度信息,从而未能立即发挥动量效应。为解决这个问题,实践中经常采用对mt进行偏差修正的方法,尤其是在算法的早期阶段,修正后的动量向帽子mt定义如上图。这里分母1减去β1t是为了矫正初期低估问题,随着迭代次数t的增加, β1t逐渐趋向于零,此时1减去β1t趋近于1,这就意味着,修正项的影响会随着t的增加而逐渐减少,{banned}最佳终趋近于无影响。使用修正后的动量帽子mt来更新参数,可以确保算法从一开始就充分利用动量效应,加速收敛过程。
动量梯度下降法通过引入动量项,有效地解决了梯度下降算法在面对复杂问题时的局限性,提高了优化的稳定性和效率。
均方根传递算法
我们已经了解到,动量梯度下降法通过引入动量相,有效克服了传统梯度下降法在处理复杂问题时的局限性,从而提升了优化过程的稳定性和效率,现在让我们继续沿着优化算法的发展历程,探索另一个关键的改进方法——均方根传递算法。传统的梯度下降法和动量梯度下降法采用固定的学习率,这在面对参数尺度各异(有的参数很大,有的参数很小)的复杂模型时,可能会遇到挑战。

均方根传递算法旨在应对这一难题, 均方根传递算法的关键在于计算梯度平方的指数衰减平均vt。这个vt的计算公式和我们前面讲的mt的计算公式非常相似,差别之处在于, vt计算的是梯度平方的指数衰减平均。我们得到vt以后,用根号vt来模拟梯度的大小,它实际上就是对于梯度大小的一个平滑估计。那么和前面介绍的mt一样,我们也要对它做一个修正,得到帽子vt。其中我们会使用帽子vt来控制自适应的调整学习率。
综上均方根传递的优化过程:
1. 计算梯度平方的指数衰减平均并初始化为零;
2. 对于vt做一个修正;
3. 也是我们这个算法{banned}最佳关键的一步,和传统采用固定的学习率不同,这里的学习率要除以帽子vt的平方根,得到一个自适应的学习率。
具体来说,如果某个参数的梯度比较大,那么vt的平方根就比较大,那么它的学习率就应该被调小,这样有助于避免该参数的更新步长过长,而越过{banned}最佳优解;相反如果某个参数的梯度比较小, 那么vt的平方根就比较小,学习率应该取得相对比较大,这样有助于加快该参数的收敛速度。这里α是一个全局学习率,用于控制所有参数更新的步长,这里我们加上了一个小常数ε是为了防止在计算自适应学习率时除以零,以确保数值的稳定性。通常我们ε的取值是10-8。
综上这种方法的优势在于它的适应性,它为每一个参数独立的设置了学习率,这种方法特别适用于参数更新方向和速度频繁变化的情况,能够为每个参数定制合适的学习率,从而提升模型训练的效率和稳定性。
adam算法
前面我们已经了解了两种强大的工具:动量梯度下降法和均方根传递。每种算法都有其独到之处,解决了传统梯度下降法在面对特定挑战时的不足。下面我们来学习adam算法。
adam算法结合了动量梯度下降法和均方根传递算法的优点,通过自适应的调整每个参数的学习率,来优化我们的模型,下面这张算法的图片,是我们在目在论文中截出来的伪代码。

adam算法的核心在于计算一阶矩mt和二阶矩vt。其中一阶矩mt就是梯度的指数衰减平均,二阶矩vt就是梯度平方的指数衰减平均。在算法开始之前,我们需要定义几个关键参数:
α是步长
β1和β2这两个参数分别是一阶矩和二阶矩的指数衰减率,他们的取值范围是在介于0~1之间
ε是一个非常小的常数,用于避免分母为零
下面我们介绍整个adam算法的具体实现步骤:首先,这个位置是初始化。后面是迭代更新,也就是说我们整个的主体。在每次迭代执行以下操作:
1. 计算梯度gt;
2. 基于梯度更新mt和vt;
3. 对mt和vt进行偏差校正,得到mt帽子和帽子vt;
4. 对参数进行更新;
那么这个{banned}最佳下面这个公式,就是我们整个adam算法的主体,可见, adam算法结合了动量梯度下降法和均方根传递算法的优点, adam算法因其出色的性能,在深度学习领域得到了广泛的应用。
计算设备内存
当前,大语言模型训练通常采用adam 优化算法,除了需要每个参数梯度,还需要一阶动量(momentum)和二阶动量(variance)。虽然 adam 优化算法相较 sgd算法效果更好也更稳定,但是对计算设备内存的占用显著增大。为了降低内存占用,大多数系统采用混合精度训练(mixed precision training)方式,即同时存在fp32(32位浮点数)与fp16(16位浮点数)或者bf16(bfloat16)格式的数值。fp32中第31位为符号位,第30位~第23位用于表示指数,第22位~第0位用于表示尾数。fp16中第15位为符号位,第14位~第10位用于表示指数,第9位~第0位用于表示尾数。bf16中第15位为符号位,第14位~第7位用于表示指数,第6位~第0位用于表示尾数。由于fp16的值区间比fp32的值区间小很多,所以在计算过程中很容易出现上溢出和下溢出。bf16相较于fp16 以精度换取更大的值区间范围。由于 fp16和bf16相较fp32精度低,训练过程中可能会出现梯度消失和模型不稳定的问题,因此,需要使用一些技术解决这些问题,例如动态损失缩放(dynamic loss scaling)和混合精度优化器(mixed precision optimizer)等。
混合精度优化的过程如下图所示。adam优化器状态包括采用fp32(4x)保存的模型参数备份,一阶动量(4x)和二阶动量(4x)也都采用fp32格式存储。假设模型参数量为x,模型参数和梯度都是用fp16格式存储,则共需要2x 2x+(4x+4x 4x)=16x字节存储。
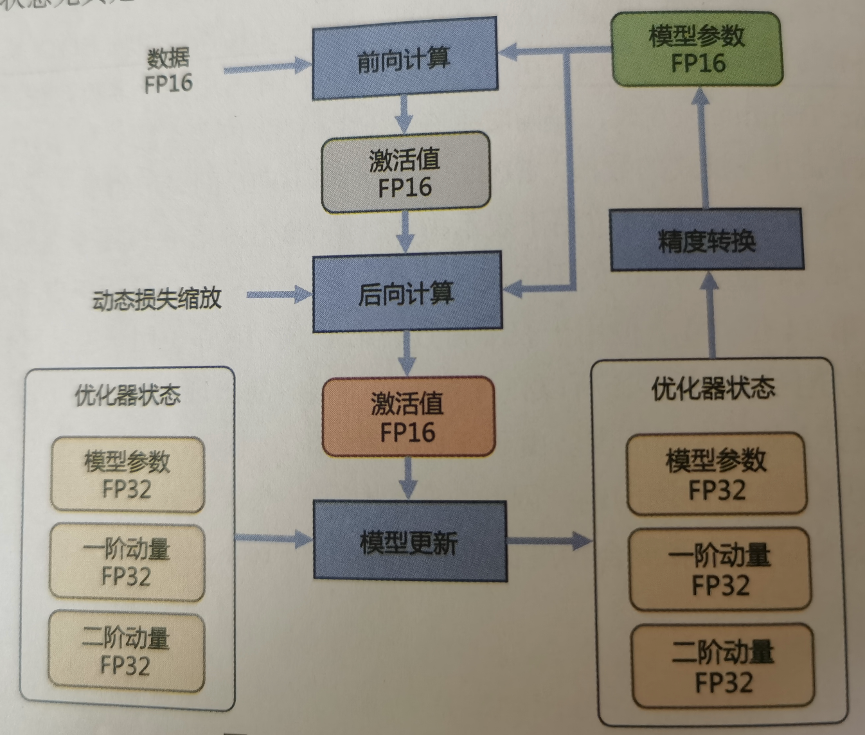
其中,adam状态占比75%。动态损失缩放反向传播前,将损失变化(dloss)手动增大2k 倍,因此反向传播时得到的激活函数梯度不会溢出;反向传播后,将权重梯度缩小2k倍,恢复正常值。举例来说,有75亿个参数的模型,如果用fp16格式,只需要15gb计算设备内存,但是在训练阶段,模型状态实际上需要耗费120gb内存。计算卡内存占用中除了模型状态,还有剩余状态(residual states),包括激活值(activation)、各种临时缓冲区(buffer)及无法使用的显存碎片(fragmentation)等。可以使用激活值检查点(activation checkpointing)方式使激活值内存占用大幅度减少,因此如何减少模型状态尤其是adam优化器状态是解决内存占用问题的关键。
zero
零冗余优化器(zero redundancy data parallelism, zero)的目标是针对模型状态的存储进行去除冗余的优化。zero使用分区的方法,即将模型状态量分割成多个分区,每个计算设备只保存其中的一部分。这样整个训练系统内只需要维护一份模型状态,减少了内存消耗和通信开销。具体来说,如下图所示,zero包含以下三种方法。
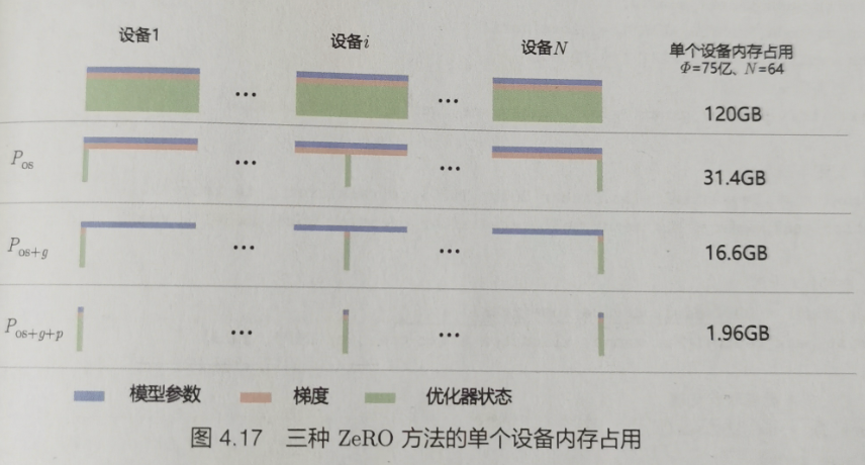
(1)对adam优化器状态进行分区,图中pos部分。模型参数和梯度依然是每个计算设备保存一份。此时,每个计算设备所需内存是4x+12x/n字节,其中n是计算设备总数。当n 比较大时,每个计算设备占用内存趋向于4xb,也就是16xb的1/4。
(2)对模型梯度进行分区,图中的pos g部分。模型参数依然是每个计算设备保存一份。此时,每个计算设备所需内存是2x (2x 12x)/n字节。当n比较大时,每个计算设备占用内存趋向于2x,也就是16xb的1/8。
(3)对模型参数进行分区,图中的pos g p部分。此时,每个计算设备所需内存是16x/n b。当n比较大时,每个计算设备占用内存趋向于0。
在deepspeed 框架中,pos对应zero-1,pos g对应zero-2,pos g p对应zero-3。此外,zero-1和zero-2 对整体通信量没有影响,虽然对通信有一定延迟影响,但是整体性能受到的影响很小。zero-3所需的通信量则是正常通信量的1.5倍。pytorch 中也实现了 zero优化方法,可以使用zeroredundancyoptimizer调用,也可与"torch.nn.parallel.distributeddataparallel"结合使用,以减少每个计算设备的内存峰值消耗。