将晦涩难懂的技术讲的通俗易懂
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
分类: linux
2024-06-09 20:48:05
gpudirect 虚拟化-凯发app官方网站
在ai和hpc场景,gpu间需要大量的交换数据,gpu通信性能成为了非常重要的指标。nvidia推出的gpudirect就是一组提升gpu通信性能的技术。
传统上,当数据需要在 gpu 和另一个设备之间传输时,数据必须通过 cpu,从而导致潜在的瓶颈并增加延迟。使用 gpudirect,网络适配器和存储驱动器可以直接读写 gpu 内存,减少不必要的内存消耗,减少 cpu 开销并降低延迟,从而显著提高性能。gpu direct 技术包括 gpudirect storage、gpudirect rdma、gpudirect p2p 和 gpudirect 视频,这里我们重点说一下gpudirect p2p特性。
某些工作负载需要位于同一服务器中的两个或多个 gpu 之间进行数据交换,在没有 gpudirect p2p 技术的情况下,来自 gpu 的数据将首先通过 cpu 和 pcie 总线复制到主机固定的共享内存。然后,数据将通过 cpu 和 pcie 总线从主机固定的共享内存复制到目标 gpu,数据在到达目的地之前需要被复制两次。
2011年,gpudirect增加了相同pci express root complex 下的gpu之间的peer to peer(p2p) direct access和direct transers的支持。有了 gpudirect p2p 通信技术后,将数据从源 gpu 复制到同一节点中的另一个 gpu 不再需要将数据临时暂存到主机内存中。如果两个 gpu 连接到同一 pcie 总线,gpudirect p2p 允许访问其相应的内存,而无需 cpu 参与。前者将执行相同任务所需的复制操作数量减半。
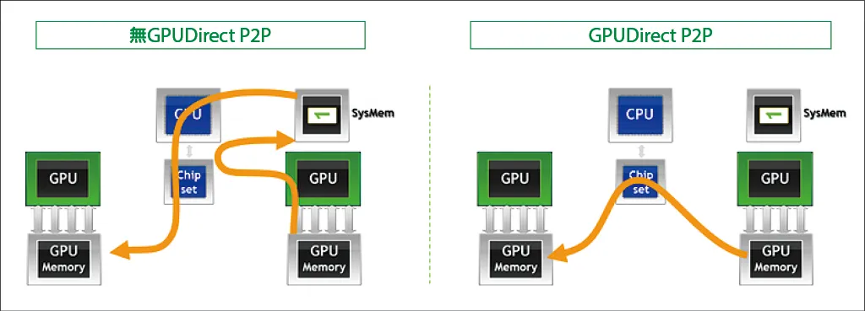
gpudirect p2p虚拟化
目前云厂商大多是通过虚拟机(或安全容器)提供主机服务的,这就涉及到p2p技术在虚拟化场景的应用。但在虚拟化场景下使用基于pcie的gpudirect p2p却存在一些限制。
首先就是不在同一个intel ioh(或pch)芯片组(相当于rc)下面pci-e p2p通信是不支持的,因为intel cpu之间是qpi协议通信,pcie p2p通信是无法跨qpi协议的。所以gpu driver必须要知道gpu的pci拓信息,同一个ioh芯片组下面的gpu才能使能gpudiret p2p。
其次在bare-metal中,nvidia 驱动程序能够检测此类拓扑,并将 gpu 组织成互斥的“cliques”即能够进行点对点通信的 gpu 组。 然而在虚拟机中,pcie拓扑由hypervisor模拟,qemu会将拓扑flattened,呈现给虚拟机内的拓扑结构不再是实际物理拓扑。但是nvidia 会限定特定芯片组和 pci express switches,并通过 pci express 拓扑来确定硬件是否能够支持p2p,这就导致gpu p2p能力在虚拟机中是默认关闭的。
为了让gpu driver获取到真实的gpu拓扑结构,hypervisor需要为guest中的gpu 驱动提供额外的信息,让驱动感知gpu的clique。nv为此提供了一个凯发app官方网站的解决方案,即在hypervisor层模拟一个虚拟的capability用于向gpu驱动提供peer-to-peer信息,nv driver在初始化时会读取该值。同时nv对这个capability的格式和编码进行了规定,并且要求在虚拟机中当gpu设备被nv驱动接管时该capability需要保持静态不变。
如下图所示,我们通过qemu向虚拟机中gpu capability 链表插入p2p approval capability。之后nv驱动通过读取peer clique id的值来更新peer-to-peer 拓扑,允许具有相同clique id的gpu建立p2p映射关系。
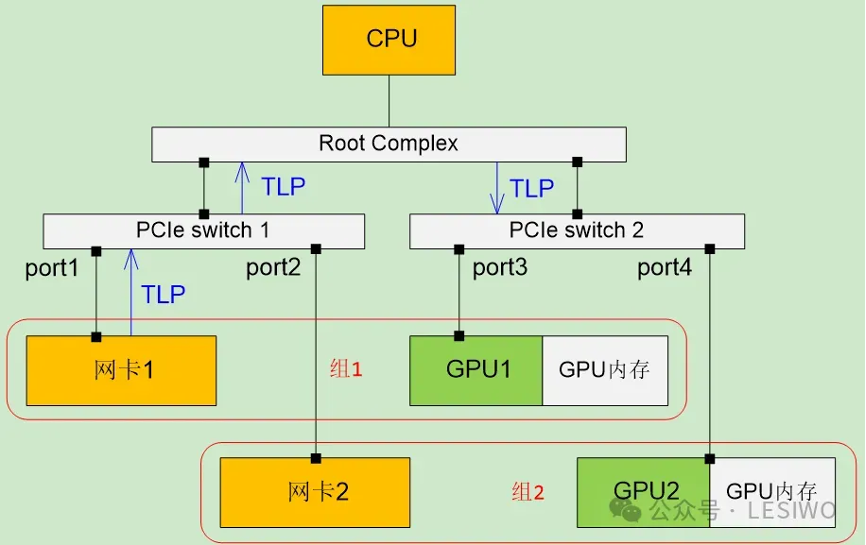
此外pcie的p2p和iommu配合存在一些问题,我们知道iommu是为了支持设备硬件辅助虚拟化而引入的技术,intel称为vt-d,amd称为amd-vi,arm称为smmu,它们的实现细节不同,但原理相同。iommu是集成在rc中的一个部件,当设备访问主机内存时,它将设备访问时使用的地址转换为主机内存的地址,在虚拟化场景下可以将设备访问的gpa转换为hpa。而pcie p2p是两个设备的直接通信,自然不在经过rc,也就无法经过iommu的地址翻译。那会有什么问题呢?考虑如下图场景,假设网卡1 gpu1被直通给vm1,网卡2 gpu2被直通给vm2,虚拟机的一个原则就是不感知自己是虚拟机,所以vm1和vm2独立配置gpu内存的pcie域的地址范围,如果这两个值是相交(甚至是相同)的,那么网卡1对gpu1内存做读写请求时,当tlp到达pcie switch 2时,pcie switch 2根据地址查表,它无法判断出应该转发到port3还是port4。这就出现了设备的隔离安全问题,肯定是不行的。
那是不是pcie p2p就不能在虚拟化场景使用了呢?当然不是,这里就要引入一个新的特性,acs(access control services)。acs是指pcie(peripheral component interconnect express)规范中引入的一项技术特性——access control services。在pcie架构中,acs是为了增强i/o虚拟化安全性而引入的。在虚拟化环境中,多个虚拟机(vm)可能共享同一物理主机上的pcie设备。如果没有适当的隔离措施,不同vm之间的直接内存访问(dma)可能会导致数据泄露或安全漏洞。acs机制通过提供一种方法来限制和控制pcie设备间的直接通信(peer-to-peer,p2p)以及设备对系统内存的访问,从而增强了虚拟化环境下的i/o设备隔离能力。如果没有acs,那么你的p2p程序将在虚拟化下无法运行。
acs是怎么解决设备隔离的问题呢?答案是acs的开启会影响到pcie的tlp的路由。如果设备开启了acs,那么这个设备的pcie数据包都会强制走其upstream port,{banned}最佳佳终走到cpu的rc。而我们知道rc的一个功能就是带iommu的地址翻译。vm内部的数据都是gpa(guest physical address),vm内驱动送给设备运行的数据都必须进过一次iommu的地址翻译才能{banned}最佳佳终访问到正真的物理内存。acs正式通过强制将p2p的pcie tlp路由到rc iommu才保证了设备的安全隔离。所以开启了acs control以后,在物理层面,其实就是禁止了任何pcie endpoint之间的物理p2p连接,因为所有的数据都会强制到rc中转。
但也正是由于开启acs pcie p2p会强制绕行到rc iommu,因此在这种情况下gpudirect的性能相对正常的p2p也会有较大下降。
acs和iommu的关系
这里再补充一下acs和iommu的关系。acs(access control services)和iommu(input/output memory management unit)在pcie系统共同协作,以增强对输入输出设备访问系统内存的控制和管理,但它们扮演着不同的角色。
iommu的作用
● 地址转换:iommu负责将设备发起的dma(direct memory access)请求中的总线物理地址转换为主机物理地址或虚拟机内存地址,这在虚拟化环境中尤为关键,因为它允许直接内存访问的同时保持虚拟机内存的隔离。
● 访问权限控制:确保i/o设备只能访问被授权的内存区域,通过维护一个i/o页表来定义设备可访问的地址范围和权限,从而增加了系统的安全性。
● 保护主机内存:防止恶意或错误的i/o操作破坏系统内存或访问敏感数据。
acs的作用:
● 设备间隔离:在pcie架构内部,acs主要关注的是不同pcie设备间的直接通信和资源访问控制,确保一个设备不能未经许可就访问另一个设备的配置空间或其直接连接的资源。
● 配置灵活性:允许系统软件配置pcie拓扑中的访问控制规则,以适应不同的系统配置和安全需求。
● 辅助虚拟化:配合iommu,为虚拟化环境提供更细粒度的设备隔离和资源分配,确保虚拟机只能看到并使用分配给它们的pcie设备。
两者的关系:
iommu和acs虽然功能上有重叠,但侧重点不同。iommu主要关注设备对系统内存的访问控制,而acs则聚焦于pcie设备间的交互和资源隔离。
iommu group是一个{banned}最佳佳小可以assign同一个vm的单元。比如有两个gpu设备在同一个pcie switch下面,如果switch与这两个gpu设备都不支持acs control的话(没有这个control bit)那么这两个gpu必须同时assign给同一个vm,或者其中一个assign给vm,另外一个必须在host端禁用。
为什么这两个gpu必须同时assign给同一个vm呢? 因为从vm的角度来看,如果这两个设备分别属于不同vm的话,一旦这两个gpu之间发生p2p数据交换的话,就相当于其中一个vm可以访问另外一个vm的数据。安全隔离性就无法满足。
那么为什么开启了acs以后,两个gpu就可以分别assign给不同的vm了呢(开启了acs这两个设备就属于不同的iommu group了)? 因为acs的作用就是强制数据流走rc的iommu翻译,这就导致了两个vm的数据会在rc一层互相访问,而无法实现硬件层面的真正的p2p访问。
因此两个gpu如果自带acs,那么即使他们在同一个pcie switch下面,他们也分属与不同的iommu group,如果他们不带acs,那么他们则属于同一个iommu group,必须同进同出。
而目前几乎所有的pcie 设备都带acs control,所以它们可以单独assign给不同的vm(无论是否在一个pcie switch下),但是随之而来的就是即使两个gpu同时assign给同一个vm,由于acs的存在,他们之间也不会有真正的物理层面的p2p访问(必须绕行rc)。
从pcie到nvlink
有没有虚拟机下高性能的gpudierct性能方案呢?当然一种hack的方案是通过虚拟化的修改让虚拟机的地址和物理相等,即gpa=hpa,设置iommu passthough,但这种方式不够灵活,也只能用于单个虚拟机(或裸金属)。另一个方式就是不用pcie,而使用nvlink。
nvlink技术是在2014年3月的nvidia gtc 2014上发布的。nvlink是一种解决服务器内gpu之间通信限制的协议。与传统的pcie交换机不同,nvlink带宽有限,可以在服务器内的gpu之间实现高速直接互连。第四代nvlink提供更高的带宽,每条通道达到112gbps,比pcie gen5通道速率快三倍。
在nvlink之前,gpu和gpu通信,或者gpu和cpu通信只能通过pcie,而以pcie gen3为例,每个通道(每个lane)的双向带宽是2b/s,gpu一般是16个lane的pcie连接,所以pcie连接的gpu通信双向带宽可以达到32gb/s,要知道pcie总线堪称pc系统中第二快的设备间总线(中国{banned}中国第一的是内存总线)。但是在nvlink 300gb/s的带宽面前,还是差距太大。
nvlink不仅增大了通信带宽,同时也解决了虚拟化场景下开启acs,导致gpudirect p2p绕行rc的问题。因为acs是主要是针对pci express (pcie) 总线架构设计的安全与访问控制机制,而nvidia的nvlink是一种高速互连技术,主要用于gpu与gpu之间或者gpu与cpu之间的高速数据传输,它并不属于pcie总线架构, 因此不受acs控制,自然也就不会绕行到rc了。但是还有一个问题,gpu直通给vm后,vm的驱动设置给gpu的地址是gpa,如果不经过rc,gpudirect产生的gpa将怎么被正确转发给对端呢? 这就要从nvlink的使用方式说起了,如果使用nvlink创建虚拟机的时候就需要先把nvlink通道建立起来,使用的是gpu内部的显存地址,这样通道建立之后就不需要地址转换了。
gpudirect rdma虚拟化
所谓gpudirect rdma,就是计算机1的gpu可以直接访问计算机2的gpu内存。而在没有这项技术之前,gpu需要先将数据从gpu内存搬移到系统内存,然后再利用rdma传输到计算机2,计算机2的gpu还要做一次数据从系统内存到gpu内存的搬移动作。gpudirect rdma技术使得进一步减少了gpu通信的数据复制次数,通信延迟进一步降低。
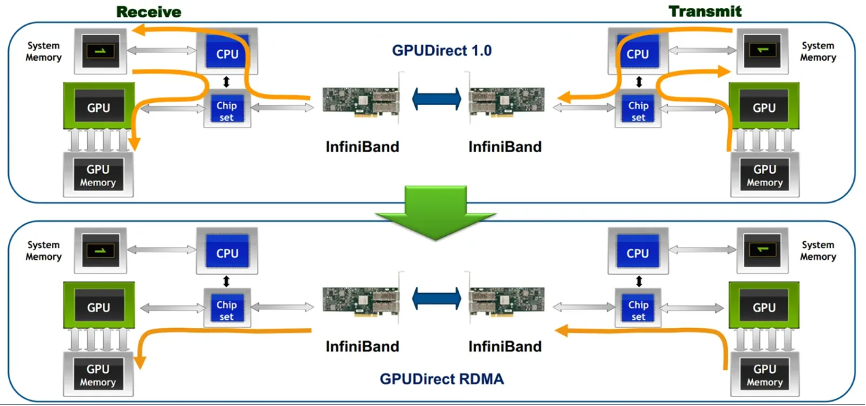
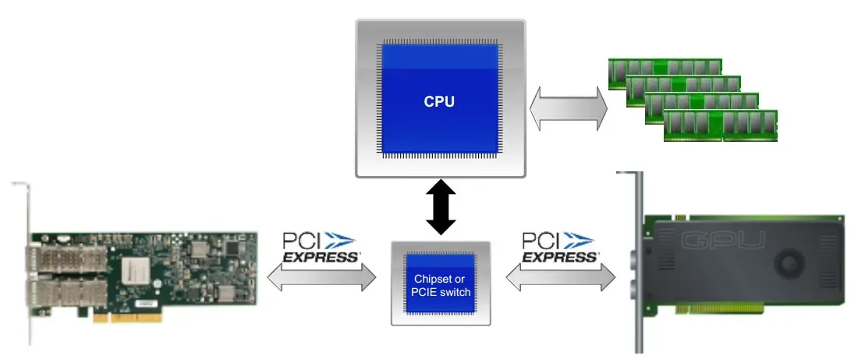
需要注意的是,要想使用gpudirect rdma,需要保证gpu卡和rdma网卡在同一个root complex下,如下图所示:
网卡和gpu之间一般是无法走nvlink的,在虚拟化场景下网卡使用的也是gpa地址,怎么进行转换呢?当然开启网卡acs也可以让网卡pcie通信绕行rc iommu。但如前文所说这会影响性能。另一个方案就是开启网卡的ats特性。ats说白了就是pcie设备自己在本地上缓存的iommu cache。ats 是address translation service 的缩写,它的提出主要是为了缓解iommu硬件iova转换的压力。尤其是当设备上有大量的dma working sets时,ats能够有效减少因为pcie链路压力过大导致的设备性能抖动。ats由位于pcie设备上的atc(address translation cache) 和 translaion agent(ta,通常也是位于iommu硬件上)组成。atc的作用可以跟cpu端的tlb来做类比,因此它也经常被称为device tlb。atc里面存储的主要是iova到hpa的映射关系,当atc发生miss的时候需要跟ta之间进行一些交互。目前大多数高级网卡/dpu都支持ats功能。