将晦涩难懂的技术讲的通俗易懂
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
- ·
分类: linux
2024-07-14 16:00:42
从google falcon看拥塞控制
falcon是google自研的可靠传输协议,其采用分层设计,由底层数据包传输层,事务层和ulp层构成。可支持rdma,nvme等不同ulp协议。其拥塞控制主要采用google的swift和plb,两个算法都比较经典。本文就以falcon拥塞控制为切入点,讲一下其拥塞控制。

流量控制和拥塞控制
首先,我发现现实中大家讨论流量反压/限速过程中经常搞混流量控制和拥塞控制。
流量控制是作用于接收者的,它是控制发送者的发送速度从而使接收者来得及接收,防止分组丢失的。所以流量控制的核心是防止接受端处理不过来。
而拥塞控制是作用于网络的,它是防止过多的数据注入到网络中,避免出现网络负载过大的情况,拥塞控制就是防止这种现象的发生,或者缓解拥堵问题。所以拥塞控制的核心是防止中间链路处理不过来。如果仅有首发两端的1对1通信是不需要拥塞控制的。
以tcp为例,其流量控制方法是“滑动窗口”,接收方在返回的数据中会包含自己的接收窗口的大小,以控制发送方的数据发送。
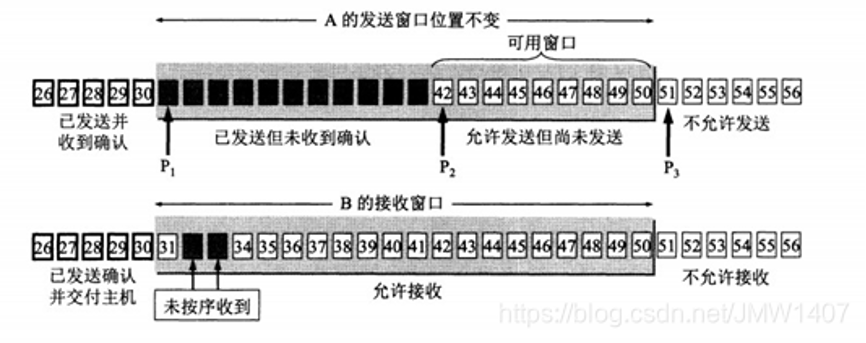
而拥塞控制方法就比较多了,如常见的reno算法(慢启动、拥塞避免算法
、快速重、快速恢),bbr,cubic等。所以tcp的发送窗口是受到流量控制和拥塞控制共同影响的:
发送窗口的上限值 = min [rwnd, cwnd],其中rwnd为接收端窗口,cwnd为拥塞窗口;
l 当 rwnd < cwnd 时,是接收端的接收能力限制发送窗口的{banned}最佳大值。
l 当 cwnd < rwnd 时,则是网络的拥塞限制发送窗口的{banned}最佳大值。
不过拥塞控制其实也包含了流量控制的的部分作用,比如接受端处理不过来和中间交换机buffer溢出都会导致丢包或者rtt增加,这个在发送端是无法感知的,所以如果由于超过接受端处理能力,也会导致拥塞控制感知,{banned}最佳终降速。那是不是有了拥塞控制就不需要流量控制了呢?当然不是,俗话说专业的人干专业的事,因为流量控制专门针对接收端,可以通过滑动窗口或credit机制的过早的感知接收端的能力,不用等到真正接收端丢包才做出反应。
另一个方面,其实有些技术也不严格的区分流量控制还是拥塞控制,比如ecn,pfc,如果中间链路的交换机buffer 超过阈值导致pfc,那是拥塞控制,如果因为目的端buffer超过阈值导致pfc,那就是流量控制了。
滑动窗口的局限性
从tcp滑动窗口的原理上我们可以看出其只考虑了接收端buffer的处理能力,因为早期通常情况下接收端的瓶颈只会出现在buffer不足。但是随着技术的发展,接收端也有其他瓶颈逐步出现,比如cpu的处理能力。而这个并没有在滑动窗口中体现。当前{banned}最佳终他会体现拥塞控制中的丢包或者rtt增加。
falcon拥塞控制
falcon拥塞控制(cc)是在每个连接的基础上实现的,并且是数据包传输子层的一部分。cc算法实现在一个速率更新引擎(rue)中,rue是一个逻辑模块,与数据包传输子层的主要数据路径分开。数据包传输子层向rue提供多种拥塞信号和状态信息,包括延迟的精确测量、ecn标记、接收缓冲区占用情况、已确认(acked)和未确认(nacked)的数据包数量等。数据包传输子层与rue之间的接口在每个方向上使用生产者-消费者队列,并在后续部分进行描述。rue逻辑模块可以完全在硬件中实现,也可以在nic上的嵌入式cpu上运行的软件中实现。
将拥塞控制功能在数据包传输子层与rue之间的分离至少有两个优点:
● 无论rue是基于软件还是硬件,对拥塞控制信号的测量、确认数据包的生成以及针对单个连接的拥塞窗口和速率的执行都在靠近数据传输线路的falcon硬件中实现。这种分离使得cc能通过快速的信号测量和速率执行对网络拥塞做出更迅速的响应。
● rue与falcon协议其他部分的分离允许对cc进行调整和迭代,而不影响数据包传输子层的主要数据路径。
接下来,我们将介绍swift拥塞控制算法和保护性负载平衡(plb)。swift设计在以下论文中有详细描述——《swift: delay is simple and effective for congestion control in the datacenter》。plb的设计则在另一篇论文中阐述——《plb: congestion signals are simple and effective for network load balancing》
swift
swift 是google发表在2020年sigcomm上的一篇论文中,用于datacenter的一种基于delay的拥塞控制算法。丢包即拥塞和基于delay判断网络拥塞一直是两条传统的研究路线,所以swift使用delay作为网络拥塞判断依据并不是一个新颖的做法,因为timely也是基于delay(rtt)实现的,但是swift提出了一个很重要的观点:将网络拥塞拆分为endpoint congestion(主机侧拥塞控制)和fabric congestion(网络侧拥塞控制),分别计算 ecwnd和fcwnd来控制发送速率,传统的工作的研究点都集中在fabric congestion,而swift指出,endpoint congestion也是不可忽略的。
如下图所示,swift在pony express中实现,pony express是一个提供自定义可靠传输的网络堆栈,在snap 中实例化。它使用nic和软件时间戳进行准确的rtt测量。它使用pony express进行cpu高效运行和实现低延迟,并且适合于诸如分组调整等特性。下图显示了swift在pony express中的位置。pony express提供了命令和完成队列api:应用程序向pony express提交命令,也称为“ops”,并接收完成。ops映射到网络流,而swift管理每个流的传输速率。
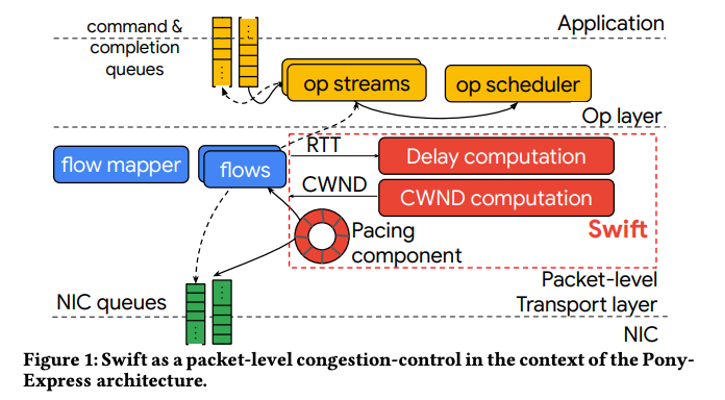
下面分四个小节介绍,分别是rtt的组成,延迟的测量,fabric congestion和endpoint congestion的意义,以及cwnd的调整。
rtt的组成
下图显示了一个rtt的组成,从本地发送一个数据包到收到对端响应的ack数据包:
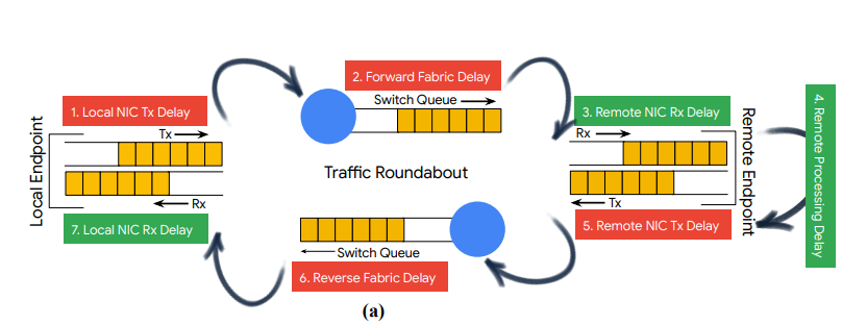
l local nic tx delay 当 nic 准备好发送数据包时,主机将数据包交给 nic,因此此延迟可以忽略不计。
l forward fabric delay 数据包在源和目的地之间的交换机上的序列化、传播和排队延迟的总和。 它还包括 nic 序列化延迟。
l remote nic rx delay 数据包进入远程网nic,到被远程协议栈处理的时延。
l remote processing delay 远程协议栈处理时延,不包括在远程网卡收队列和发队列中的时延。
l remote nic tx delay 响应的数据包被远程协议栈交给网卡的发送队列,到数据包从网卡的发送队列被发出去的时延。
l reverse fabric delay ack数据包在反向路径上花费的时间。 值得注意的是,正向和反向路径可能不是对称的。
l local nic rx delay ack包进入nic后,在被网络协议栈处理之前所花费的时间。
延迟测量
因为swift使用延迟来判断网络是否拥塞,所以需要精确测量延迟。下图中的红色为软件时间戳,蓝色为硬件时间戳。
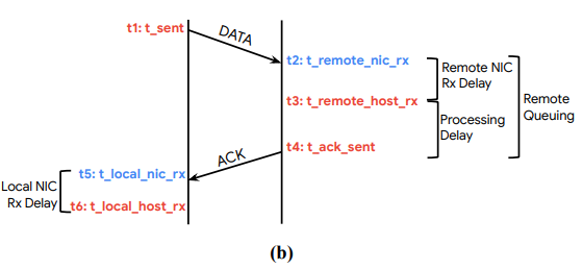
t1是数据包被发送的时间,由协议栈记录。
t2是数据包到达对端网卡的时间,由网卡记录。
t3是数据包被远程协议栈处理的时间,t3?t2就是数据包在远程网卡收包队列中的排队时延。
t4是ack数据包被协议栈发出去的时间,是t4?t3是远程协议栈处理数据包花费的时间。
t5是网卡收到响应ack数据包的时间。
t6是协议栈处理ack数据包的时间,t6?t1就是rtt。
注意:和timely一样,swift没有考虑发送方向从协议栈到网卡的时延。
区分fabric congestion和endpoint congestion,那么自然就会引出fabric delay和endpoint delay和fabric target delay和endpoint target delay这两组概念。因为swift要根据fabric delay和fabric target delay来判断是否发生了fabric congestion,以及根据endpoint delay和endpoint tartet delay来判断是否发生了endpoint congestion。
什么是fabric delay?这里先说endpoint delay,endpoint delay等于local nic rx delay(t6-t5)与remote queuing(t4-t2)两者的和,那就知道了fabric delay等于rtt-endpoint delay。
由于t6是{banned}最佳终计算rtt时协议制可以随时获取的,所以如果实现一个协议中,报文需要能够存放4个timestamp,即t1,t2,t4,t5。
拥塞窗口调整
swift 的核心算法是一个简单的aimd(加法增加,乘法减小)控制器,基于测量到的延迟是否超过目标延迟。我们发现简单性是一种优点,因为 timely 演变成 swift 并删除了一些复杂性,例如,使用 rtt 与目标延迟之间的差异而不是 rtt 梯度。
swift根据收到ack时得到的delay,然后和target delay比较计算出合适的cwnd。如果delay小于target delay,则cwnd(以数据包为单位)增加ai/cwnd(ai=附加增量),使得在一个 rtt上的累积增加等于ai。 否则,cwnd乘法减小,减小的粒度取决于delay与target delay的距离。乘法减少被限制为每个rtt一次,因此 swift 在一个rtt内不会多次对同一个拥塞事件做出反应。我们通过检查{banned}最佳后一次cwnd减少的时间来做到这一点。cwnd的初始值在我们的设置中几乎没有影响,算法的细节见下图:

其中关键是7-11行的加法增加部分,为什么要区分cwnd大于1的情况,并且还要ai/cwnd。首先这几个的{banned}最佳终目的都是为了确保在一个 rtt中,cwnd的累积增加等于ai。而一个rtt发送端是可以发送cwnd个packet的,因此是需要收到cwnd个报文的ack的(包括聚合ack)。如果假设ai为1,即控制每个rtt中cwnd增加1,因此在cwnd大于1时需要ai/cwnd。而cwnd小于1是swift的一个创新,因为正常cwnd{banned}最佳小就是1。swift允许cwnd小于1主要是为了解决incast场景。
在部署过程中,我们遇到了依赖于极大规模incast的应用程序,成千上万的流量同时流向单个主机。在这种情况下,当流量数量超过路径bdp时,即使是单个数据包的拥塞窗口(cwnd=1)也过高,无法防止过载。为了处理这种情况,我们扩展了swift,允许拥塞窗口下降到低于一个数据包,{banned}最佳低到0.001个数据包。这种情况需要特殊处理算法1中的增量更新(第7-11行)。为了实现分数拥塞窗口,我们将其转换为数据包之间的rtt/cwnd延迟,发送方使用该延迟将数据包步进式地发送到网络中。例如,cwnd为0.5的结果是在2 × rtt的延迟后发送一个数据包。
而12-14的乘法减,前者(delay-target_delay)/delay主要是希望延时比target_delay越大,则乘法的因子就越小,以便cwnd更快的减小;而又不希望cwnd减小的太小,所以有(1-max_mdf)约束。至于算法中的参数(ai,max_mdf等)都是根据实际环境评估出的。其中can_decrease是用于判断是否处于一个rtt中。
当然swift也考虑了重传超时和快恢复的处理,具体如下,这里不再展开。

target_delay(目标延时)怎么来?
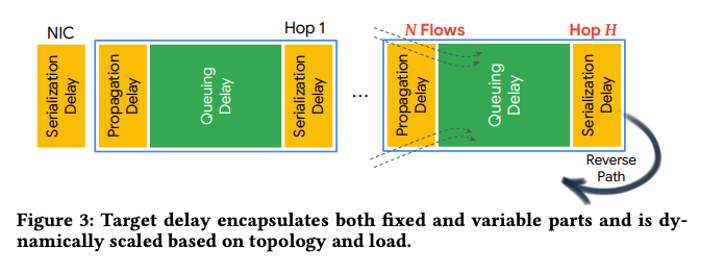
到目前为止,我们已经描述了具有固定目标延迟的swift。接下来,我们描述如何根据路径较长或负载较重的延迟来缩放目标基础设施延迟(target_delay)(以下简称为目标延迟)。目标延迟封装了基础设施延迟的固定和可变部分,如下图所示。目标延迟的基础部分包括对于小型数量流量的单跳网络所发生的延迟:传播延迟、nic和交换机中的序列化延迟(这取决于链路速度)、少量流量的排队延迟、软件和硬件时间戳的测量误差,以及网络中的任何未计算延迟,例如由于qos调度引起的延迟。在此基础之上,我们根据拓扑和负载对目标延迟进行缩放。
fabric congestion vs endpoint congestion
传统基于delay研究拥塞控制都没有区分fabric congestion和endpoint congestion,swift的作者认为区分这两者是有必要的。为什么很有必要呢?作者在paper没有详细讨论,只是在多处提及很重要,其中一处原文解释如下:
many congestion control designs focus on the fabric as the network, and ignore host issues. we learned over time that host issues are important and need a different congestion response.
通过查阅sigcomm‘2015 timely,找到了一些解释。在广域网,rtt一般都是亚秒级别,主要延迟是在链路上的传播延迟,而host内的处理延迟可以相对忽略不计。但是在数据中心不一样,一般链路上的单向传播延迟可能也就十几个微秒,所以这时候host内的处理延迟相对而言就不小了,必须要重视。另外应用类型也会造成不同的拥塞,例如iops-intensive应用更容易造成endpoint congestion,throughput-intensive应用更容易造成fabric congestion。
但我认为这里仅仅解释了为什么要考虑host延时,而没有解释为什么要单独考虑host延时。因为类似timely测量整体rtt中也包含了host的延时。为什么要将host延时和fabric延时分开考虑,使用两个cwnd,我认为是为了更加精准敏捷的控制。考虑一下如果host侧出现了拥塞,而fabric非常空闲,如果分开考虑此时就可以精准感知到host的cwnd减少而降速,而如果统一考虑整体cwnd,势必降低的会比较慢。
swift使用了两个拥塞窗口,fcwnd和ecwnd,分别对应fabric congestion和endpoint congestion。fcwnd和ecwnd的计算都采用前面图中的算法,区别是:
there is a slight difference in that we use exponentiallyweighted moving average (ewma) filtering for the endpoint delay,given that endpoint delays are more noisy in our experience.
但paper原文只说了fabric target delay的值如何评估,endpoint target delay的值如何给成了悬念。{banned}最佳后实际用的拥塞窗口为min(fcwnd,ecwnd)。
再看流量控制和拥塞控制
如果注意的话,可以看到swift这里min(fcwnd,ecwnd)和tcp的“发送窗口的上限值 = min [rwnd, cwnd]”有点类似?那是不是可以理解为这里单独考虑的ecwnd就是流量控制中的rwnnd。我认为应该这么理解:正如前文所述,流量控制是端到端的控制,当目前滑动窗口仅仅考虑了接受端buffer的因素,而其他因素没有考虑,这里的ecwnd正是滑动窗口的一个补充。考虑一下接受端buffer充足,但是由于流量过大导致cpu资源紧张,处理的不够及时,这样就能通过ecwnd反馈在swift的拥塞控制上。从另一方面,如果流量控制考虑了per connection的cpu credit,以及其他因素(如pcie带宽,内存带宽等),那么确实不需要这里swift的ecwnd控制了。但是实际情况我们很难向buffer一样,约束一个connection的各种资源,如cpu credit,pcie带宽,内存带宽等。因此,这里的端侧拥塞控制可以理解为滑动窗口流量控制的补充。
基于ecn/rate vs基于window
谷歌的timely(sigcomm15)是rate-based mechanism,而swift则变成window-based。window-based 还是rate-based的速率调控也是一直在讨论的问题。那两者有什么差异呢?
基于ecn/rate的拥塞控制
ecn(explicit congestion notification)是一种网络拥塞通知机制,它允许网络设备在检测到即将发生拥塞时,通过标记网络包来通知发送端和接收端。在rdma中,当ecn标记被检测到时,发送端会根据信号降低其发送速率,从而减轻网络拥塞。
● 速率控制(rate control):这种方式下,端点会根据网络的拥塞信号来动态调整发送速率。如果网络中出现拥塞迹象(例如,通过ecn标记),发送端会降低其发送速率以减轻拥塞;如果网络拥塞情况缓解,发送速率可以逐渐增加。
● 优点:可以更精细地控制发送速度,对网络变化的响应更为直接和快速。
● 缺点:要求网络设备和协议栈支持ecn标记和处理逻辑,可能需要更复杂的算法来确定适当的发送速率(当然timely这种基于rtt的不需要)。
基于窗口的拥塞控制
窗口基拥塞控制,如tcp中使用的tcp拥塞控制算法,依赖于未确认数据的数量(即“拥塞窗口”)来决定可以发送多少数据。发送端根据网络的传输确认来调整拥塞窗口的大小。
● 窗口调整(window adjustment):发送端根据确认回来的数据包来增加或减少拥塞窗口的大小。如果数据包成功传送并确认,窗口就增大;如果发生丢包,窗口则缩小。
● 优点:是已经广泛实施并经过测试的成熟技术,特别是在tcp协议中。
● 缺点:响应速度可能比基于ecn/rate的方法慢,因为窗口调整依赖于数据包的往返时间(rtt)。
我个人觉得随着dcn链路速度的增加window-based的调节(或者rate-based window-based)可能性能更好, 因为window-based调节能更好地控制inflight数据量,当拥塞发生时不会因端的拥塞控制还未来得及反应而造成拥塞加剧。hpcc (sigcomm 2019)论文里包含了这个观点,它论文里给rate-based 的拥塞控制加了window限制后性能提升不少。
plb
现代网络通过并行使用许多链路来扩展容量,通常采用clos拓扑结构。这种设计导致从源点到每个目的节点都有许多条路径。在这种设置中,有效的机制来分散可用网络路径上的负载对应用程序性能和网络效率至关重要。当前广泛采用的ecmp不能产生平衡的负载(一方面有大象流,另一方面可能hash极化),并可能加剧拥塞热点问题。falcon采用了plb方案进行处理。plb使用ipv6 flow label区分路径和连接,并且通过一定测量保证大流量和小流量都能够平滑切换。
plb 是一种主机设计,它将负载均衡与 ipv6 流量的传输集成在一起。它与 ecmp/wcmp 路由互补,只不过流量哈希扩展到包括 flow label 以及通常的 4-元组。plb 设计有两个部分:拥塞检测和重新路径。
发送主机通过传输检测到连接正在经历拥塞。然后,它通过为后续传出的数据包分配一个新的、随机生成的 flow label 来重新路径连接。plb 使用相应传输中的现有拥塞信号进行拥塞控制,不需要任何额外的拥塞工具。目前google已经开发了 plb-tcp,并与 bbrv2 拥塞控制一起使用,整个 plb-tcp 实现大约是 linux 内核 tcp 堆栈中的 50 行代码。
检测拥塞
plb-tcp 发送方使用一个简单的 dctcp 类似启发式来检测连接是否拥塞。伪代码显示在算法 1 中,如下图所示:

当交换机队列超过某个阈值时,交换机在数据包上标记 ce。接收方将 ce 标记回传给发送方。这些都是 ecn 的现有 tcp/ip 行为。对于每个收到的 ack,发送方调用 tcp_congdetection()。发送方计算每个往返行程中带有 ce 标记的数据包的分数(fraction)。当这个次数大于一个常数 k时,我们称该轮次(一个rtt是一个轮次)为拥塞的。在经历了 m个连续拥塞的轮次之后,我们标记该流为拥塞。
重新路径(repathing)
repath会导致乱序,尽管当前linux tcp的rack技术已经{banned}最佳小化了由于重新排序引起的错误丢失恢复,但是在gro场景仍然有问题。乱序会导致gro过早聚合结束,起不到聚合64k的效果,进而导致cpu的开销过大。
为了避免乱序,plb采用对一个拥塞(congested)flow进行延时repathing,即发现flow出现拥塞,不立即进行repathing,而是等到flow变的idle在切换。这里idle并不是flow结束,而是flow段时间空闲。因为大部分应用都是多个rpc调用复用一个tcp长连接,rpc调用之间就是flow的idle状态。这样flow repathing时没有infly的报文,就不会导致乱序,这种策略有效是因为大多数rpc都是比较轻量,可以快速结束的。但面临一些大的rpc调用导致的heavy flow时,我们强制flow在n个连续的congested rounds后进行repath。具体策略参考算法2,这样{banned}最佳坏情况也是每n 个rtt才会有一次切换导致乱序。

通过这两种策略结合,可以将轻负载的流(有idle的rpc流)切换到不合重负载流冲突的路径,从而降低轻负载rpc的长尾延时。
链路故障
为了应对链路故障情况,plb 还会在发生超时重传(rto)时进行repathing,所以虽然 ecn 是检测拥塞的常见情况,但发现 rto 超时也是repathing的关键部分。
pony express的plb拥塞检测
在google内部,使用名为pony express的传输协议以及tcp。pony express在用户空间运行,直接访问nic以实现低延迟传输。plb-pony express的实现大约也是50行代码,并与基于swift的延迟拥塞控制一起使用。plb-pony express与plb-tcp的唯一区别在于它如何检测拥塞,如算法1图。对于收到的每个ack,发送方调用swift_congdetection()。与ecn标记不同,pony express中的swift拥塞控制使用nic时间戳来测量网络路径和排队延迟,并旨在保持rtt低于目标值(target delay)。对于每个往返行程(round-trip),plb计算超过目标延迟????????????????????_????????????????????????_????????????????????的rtt测量值的比例。目标延迟是基于预期路径传播延迟和排队目标的swift配置参数。与tcp一样,当有m个连续往返行程中至少有k比例的高rtt时,我们就认为检测到拥塞。pony express不使用tso和gro,因为它绕过了内核。然而,{banned}最佳小化重新排序仍然很重要,以避免误报丢失恢复和拥塞反应。为此,我们使用算法2中的相同重新路径逻辑。
算法动态
这部分描述了plb如何与拥塞控制交互,以及它如何实现全网络范围内的负载均衡。
与拥塞控制的交互
路径负载均衡的一个核心问题是:当发现有路径出现了拥塞(如rtt增加),此时是该调用负载均衡算法切换路径呢,还是该调用拥塞控制进行降速?
针对此问题,plb在时间维度上进行分离,让plb和拥塞控制可以同时操作,而不会有不利的交互。当一个流经历拥塞时,plb会等待几个往返行程(由算法2中的m,n配置)才重新路径(repath)。这给了拥塞控制响应瞬态问题的时间。如果plb立即repath,那么拥塞控制就会发现每个往返行程可能测量到不同的路径,进而干扰拥塞控制的算法执行。因此,plb更倾向于在空闲后repath,此时拥塞状态可能已过时,而且需要探测以获取新状态。通过这种方式,plb不需要修改底层拥塞控制模块。
另一方面,我们不希望长时间承受严重的拥塞(即算法1中的大n,k)。这可能会降低性能,因为拥塞控制可能会减慢流速,而不是plb寻找更多可用带宽。我们进行了参数测试,并经验性地发现???? = 0.5, ???? = 3 和???? = 12时在一系列工作负载中取得了良好的平衡。我们发现没有特别的敏感性,只是需要不同的m和n来同时更快地重新路径,以加速小型rpcs,并且更慢地避免干扰大型rpcs。对于其他工作负载模式,可能需要不同的值。例如,如果交换机ecn标记阈值较高,则可能需要较低的k值。如果相应的拥塞控制需要更多的往返行程来响应和稳定拥塞,则需要更高的m。
在链路故障时,故障链路上的流将经历数个rto后,plb将repath它们,这是符合预期的。但是在repath后,如果当前的workload大于新路径的容量,很可能导致再次拥塞,而这种情况不应该再次触发repath,因为很可能重新repath到之前的故障链路上。为此,plb通过在算法1中的plbdetection()模块暂停plb,在rto超时后抑制repath。而抑制时间是根据预期的链路恢复时间设置的其值的一到两倍。
plb 在生产中的部署
我们在所有google数据中心服务器上为tcp和pony express部署了plb。我们的生产网络由遍布全球的许多大型数据中心组成。它们支持从存储工作负载到像内存中键值存储这样的低延迟工作负载等多种应用。ipv6的使用非常普遍,所有交换机除了四元组外,还使用flow label进行ecmp/wcmp哈希。网络控制器或流量工程(例如ecmp和wcmp权重、路由)没有其他更改。plb涵盖了几乎所有内部应用程序在数据中心内部和跨b4骨干网的传输。tcp使用bbrv2拥塞控制,而pony express使用swift拥塞控制。这两种协议共享相同的底层网络,因此它们的plb实现会相互交互。plb允许快速部署,因为它可以单方面在发送方逐流启用,甚至不需要重启流。因此,plb可以快速且逐步部署,而不会干扰各个数据中心中的应用程序。它也可以有选择地禁用用于故障排除,尽管我们没有这个需求。
总结
以上就是falcon的流量控制方法,其实总体可以分为三部分:流量控制,拥塞控制,负载均衡。其中流量控制是滑动窗口,拥塞控制通过swift,负载均衡通过plb。正常我们设计一个高性能传输协议通常也需要考虑这几方面,当然负载均衡是可选的,但在ai大带宽场景通常是比较重要的。